






Business Intelligence
is the act of transforming raw/operational data into useful information for business analysis
- BI based on Data Warehouse technology extracts information from a company's operational systems.
- The data is transformed (cleaned and integrated), and loaded into Data Warehouses.
- Since this data is credible, it is used for business insights.
Why
- Data collected from various sources & stored in various databases cannot be directly visualized.
- The data first needs to be integrated and then processed before visualization takes place.
Pros
- Strategic questions can be answered by studying trends.
- Data Warehousing is faster and more accurate.
Note : Data warehouse is not a product that a company can go and purchase, it needs to be designed and depends entirely on the company requirements. It's strategy to make your data easier to access and be interpreted.
Properties
Subject-oriented:
data is categorized and stored by business subject rather than by application.
Integrated
data on a given subject is collected from disparate sources and stored in a single palce.
Time-variant
data is stored a series of snapshots, each representing a period of time.
None-volatile
typically data in the data warehouse is not updated or deleted.
ETL
is the process of extracting the data from various sources, transforming this data to meet your requirements and then loading it into a target data warehouse, for example, Informatic.
Data Mart
- Data Mart is a smaller version of the Data Warehouse which deals with a single subject.
- Data marts are focused on one area, hence, they draw data from a limited number of sources.
- Time taken to build data marts is very less compared to the time taken to build a data warehouse.
Dependent Data Mart
- OLTP -> Data Warehouse -> Data Mart
Independent Data Mart
- OLTP -> Data Mart
Hybrid Data Mart
- OLTP -> Data Mart
- Data Warehouse -> Data Mart
Metadata
define which table is source and target, and which concept is used to build business logic called transformation to the actual output.
Architecture
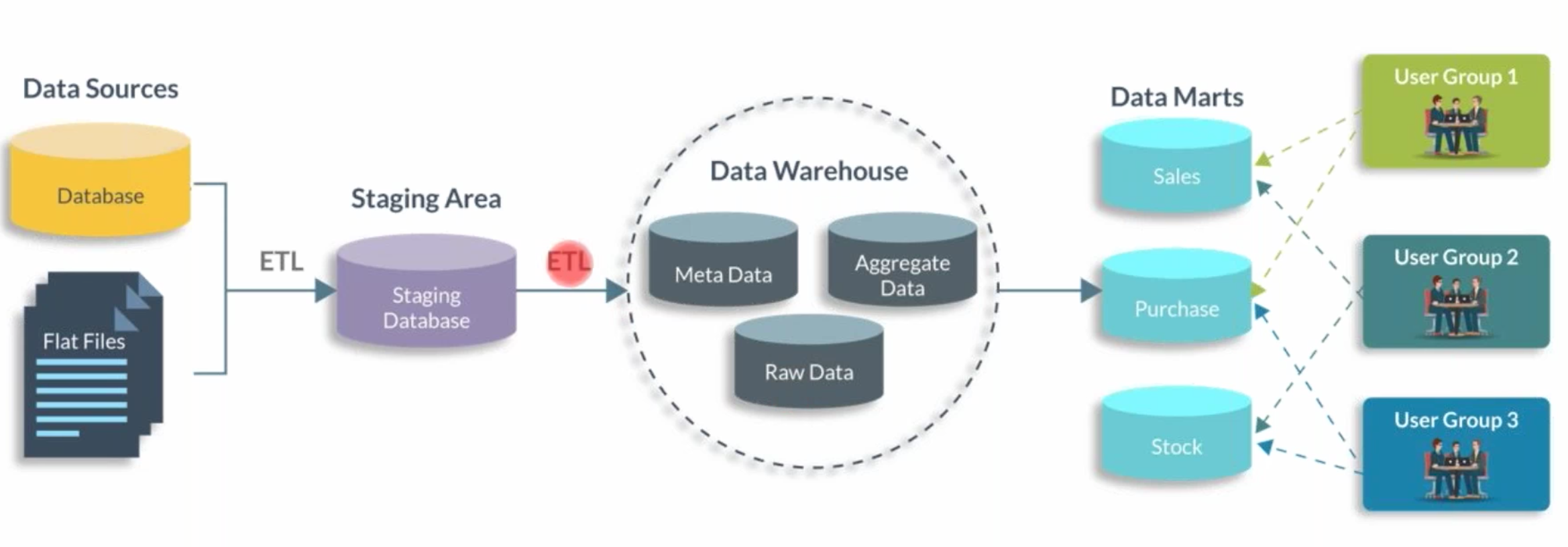
数据库
http://www.cnblogs.com/muchen/p/5272620.html
建模
概念模型建模(ER建模/需求可视化) : 在这个环节中,数据开发人员绘制ER图,并和项目各方人员协同需求,达成一致。由于这部分的工作涉及到的人员开发能力比较薄弱,甚至不懂开发,因此ER图必须清晰明了,不能涉及到过多的技术细节。在ER图绘制完毕之后,才开始将它映射为关系表。这个映射的过程,就叫做逻辑模型建模或者关系建模。
有人会说,ER图不是可以直接映射到关系吗,而且已经有了相应的映射工具了,为什么还要绘制ER图多此一举呢?ER图是拿出去和别人谈需求的,要求各方人员都能看得懂。而关系表设计到了过多实现细节,比如:要给多对多联系/多值属性等多建一张表,要设置外码,各种复合主码等。这些东西不应该在谈需求的时候出现,它们应当对非开发人员透明。而且ER图中每个属性只会出现一次,减少了蕴含的信息量,是更好的交流和文档化工具。
还有,ER模型所蕴含的信息,也没有全部被逻辑模型包含。比如联系的自定义基数约束,比如实体的复合属性,派生属性,用户的自定义约束等等。因此ER模型在整个开发流程(如物理模型建模,甚至前端开发)中是都会用到的,不能认为ER模型转换到逻辑模型后就可以扔一边了。
需求分析阶段(概念建模)
- 需求可视化,概念建模(ER建模)
- 这部分工作要求开发人员和业务方,数据库的使用者,公司领导等方面协同好需求,并将需求以ER图的模式可视化展现出来。
关系表设计(逻辑建模)
逻辑建模/关系建模
ER图到具体关系表的建立需要经过两个步骤:
- 逻辑模型设计
- 物理模型设计。
其中前者将ER图映射为逻辑意义上的关系表,后者则映射为物理意义上的关系表。逻辑意义上的关系表可以理解为单纯意义上的关系表,它不涉及到表中字段数据类型,索引信息,触发器等等细节信息。
范式

先对表做一个简单说明,employeeId是员工id,departmentName是部门名称,job代表岗位,jobDescription是岗位说明,skill是员工技能,departmentDescription是部门说明,address是员工住址。
第一范式(1NF)
如果一个关系模式R的所有属性都是不可分的基本数据项,则R∈1NF。
简单的说,第一范式就是每一个属性都不可再分。不符合第一范式则不能称为关系数据库。对于上表,不难看出Address是可以再分的,比如”北京市XX路XX小区XX号”,着显然不符合第一范式,对其应用第一范式则需要将此属性分解到另一个表,如下:

第二范式(2NF)
若关系模式R∈1NF,并且每一个非主属性都完全函数依赖于R的码,则R∈2NF
简单的说,是表中的属性必须完全依赖于全部主键,而不是部分主键.所以只有一个主键的表如果符合第一范式,那一定是第二范式。这样做的目的是进一步减少插入异常和更新异常。在上表中,departmentDescription是由主键DepartmentName所决定,但却不是由主键EmployeeID决定,所以departmentDescription只依赖于两个主键中的一个,故要departmentDescription对主键是部分依赖,对其应用第二范式如下表:

第三范式(3NF)
关系模式R<U,F> 中若不存在这样的码X、属性组Y及非主属性Z(Z Y), 使得X→Y,Y→Z,成立,则称R<U,F> ∈ 3NF。
简单的说,第三范式是为了消除数据库中关键字之间的依赖关系,在上面经过第二范式化的表中,可以看出jobDescription(岗位职责)是由job(岗位)所决定,则jobDescription依赖于job,可以看出这不符合第三范式,对表进行第三范式后的关系图为:

BC范式(BCNF)
设关系模式R<U,F>∈1NF,如果对于R的每个函数依赖X→Y,若Y不属于X,则X必含有候选码,那么R∈BCNF。
简单的说,bc范式是在第三范式的基础上的一种特殊情况,既每个表中只有一个候选键(在一个数据库中每行的值都不相同,则可称为候选键),在上面第三范式的noNf表中可以看出,每一个员工的email都是唯一的(难道两个人用同一个email??)则此表不符合bc范式,对其进行bc范式化后的关系图为:

第四范式(4NF)
关系模式R<U,F>∈1NF,如果对于R的每个非平凡多值依赖X→→Y(Y X),X都含有候选码,则R∈4NF。
简单的说,第四范式是消除表中的多值依赖,也就是说可以减少维护数据一致性的工作。对于上面bc范式化的表中,对于员工的skill,两个可能的值是”C#,sql,javascript”和“C#,UML,Ruby”,可以看出,这个数据库属性存在多个值,这就可能造成数据库内容不一致的问题,比如第一个值写的是”C#”,而第二个值写的是”C#.net”,解决办法是将多值属性放入一个新表,则第四范式化后的关系图如下:
而对于skill表则可能的值为:

总结
建模工作的作用,就是能够让设计的关系更容易满足规范化设计中的(第三)范式要求,从而减少数据冗余,消除更新异常。但是上面对于数据库范式进行分解的过程中不难看出,应用的范式登记越高,则表越多。表多会带来很多问题:
- 查询时要连接多个表,增加了查询的复杂度
- 查询时需要连接多个表,降低了数据库查询性能
而现在的情况,磁盘空间成本基本可以忽略不计,所以数据冗余所造成的问题也并不是应用数据库范式的理由。因此,并不是应用的范式越高越好,要看实际情况而定。第三范式已经很大程度上减少了数据冗余,并且减少了造成插入异常,更新异常,和删除异常了。大多数情况应用到第三范式已经足够,在一定情况下第二范式也是可以的。
ETL
http://lxw1234.com/archives/2015/04/31.htm
数据抽取
可以理解为是把源数据的数据抽取到数据库或者数据仓库中
源数据类型
- 关系型数据库,如Oracle,Mysql,Sqlserver等;
- 文本文件,如用户浏览网站产生的日志文件,业务系统以文件形式提供的数据等;
- 其他外部数据,如手工录入的数据等;
抽取的频率
- 大多是每天抽取一次, 也可以根据业务需求每小时甚至每分钟抽取。当然得考虑源数据库系统能否承受;
抽取策略
个人感觉这是数据抽取中最重要的部分,可分为全量抽取和增量抽取。全量抽取适用于那些数据量比较小,并且不容易判断其数据发生改变的诸如关系表,维度表,配置表等;增量抽取,一般是由于数据量大,不可能采用全量抽取,或者为了节省抽取时间而采用的抽取策略;
如何判断增量,这是增量抽取中最难的部分,一般包括以下几种情况:
- 通过时间标识字段抽取增量;源数据表中有明确的可以标识当天数据的字段的流水表,如createtime,updatetime等;
- 根据上次抽取结束时候记录的自增长ID来抽取增量;无createtime,但有自增长类型字段的流水表, 如自增长的ID,抽取完之后记录下最大的ID,下次抽取可根据上次记录的ID来抽取;
- 通过分析数据库日志获取增量数据,无时间标识字段,无自增长ID的关系型数据库中的表;
- 通过与前一天数据的Hash比较,比较出发生变化的数据,这种策略比较复杂,在这里描述一下,
- 比如一张会员表,它的主键是memberID,而会员的状态是有可能每天都更新的,我们在第一次抽取之后,生成一张备用表A,包含两个字段,第一个是memberID,第二个是除了memberID之外其他所有字段拼接起来,再做个Hash生成的字段,在下一次抽取的时候,将源表同样的处理,生成表B,将B和A左关联,Hash字段不相等的为发生变化的记录,另外还有一部分新增的记录,根据这两部分记录的memberID去源表中抽取对应的记录;
- 由源系统主动推送增量数据;例如订单表,交易表,有些业务系统在设计的时候,当一个订单状态发生变化的时候,是去源表中做update,而我们在数据仓库中需要把一个订单的所有状态都记录下来,这时候就需要在源系统上做文章,数据库触发器一般不可取。我能想到的方法是在业务系统上做些变动,当订单状态发生变化时候,记一张流水表,可以是写进数据库,也可以是记录日志文件。
- 当然肯定还有其他抽取策略,至于采取哪种策略,需要考虑源数据系统情况,抽取过来的数据在数据仓库中的存储和处理逻辑,抽取的时间窗口等等因素。
数据清洗
把不需要的,和不符合规范的数据进行处理。数据清洗最好放在抽取的环节进行,这样可以节约后续的计算和存储成本;
- 空值处理:根据业务需要,可以将空值替换为特定的值或者直接过滤掉;
- 验证数据正确性:主要是把不符合业务含义的数据做一处理,比如,把一个表示数量的字段中的字符串替换为0;把一个日期字段的非日期字符串过滤掉等等;
- 规范数据格式:比如,把所有的日期都格式化成YYYY-MM-DD的格式等;
- 数据转码:把一个源数据中用编码表示的字段,通过关联编码表,转换成代表其真实意义的值等等;
- 数据标准/统一;比如在源数据中表示男女的方式有很多种,在抽取的时候,直接根据模型中定义的值做转化,统一表示男女;
- 其他业务规则定义的数据清洗。。。
数据转换和加载
很多人理解的ETL是在经过前两个部分之后,加载到数据仓库的数据库中就完事了。数据转换和加载不仅仅是在源数据->ODS数据库这一步,数据库->数据仓库, 数据仓库->数据集市包含更为重要和复杂的ETL过程。
什么是ODS
ODS(Operational Data Store)是数据仓库体系结构中的一个可选部分,ODS具备数据仓库的部分特征和OLTP系统的部分特征,它是“面向主题的、集成的、当前或接近当前的、 不断变化的”数据。 (摘自百度百科)。
其实大多时候,ODS只是充当了一个数据临时存储,数据缓冲的角色。一般来说,数据由源数据加载到ODS之后,会保留一段时间,当后面的数据处理逻辑有问题,需要重新计算的时候,可以直接从ODS这一步获取,而不用再从源数据再抽取一次,减少对源系统的压力。
另外,ODS还会直接给数据集市或者前端报表提供数据,比如一些维表或者不需要经过计算和处理的数据;
还有,ODS会完成一些其他事情,比如,存储一些明细数据以备不时之需等等;
数据转换(刷新)
数据转换,更多的人把它叫做数据刷新,就是用ODS中的增量或者全量数据来刷新DW中的表。DW中的表基本都是按照事先设计好的模型创建的,如事实表,维度表,汇总表等,每天都需要把新的数据更新到这些表中。更新这些表的过程(程序)都是刚开始的时候开发好的,每天只需要传一些参数,如日期,来运行这些程序即可。
数据加载
个人认为,每insert数据到一张表,都可以称为数据加载,至于是delete+insert、truncate+insert、还是merge,这个是由业务规则决定的,这些操作也都是嵌入到数据抽取、转换的程序中的。
ETL工具
在传统行业的数据仓库项目中,大多会采用一些现成的ETL工具,如Informatica、Datastage、微软SSIS等。这三种工具我都使用过,优点有:图形界面,开发简单,数据流向清晰;缺点:局限性,不够灵活,处理大数据量比较吃力,查错困难,昂贵的费用;选择ETL工具需要充分考虑源系统和数据仓库的环境,当然还有成本,如果源数据系统和数据仓库都采用ORACLE,那么我觉得所有的ETL,都可以用存储过程来完成了。。在大一点的互联网公司,由于数据量大,需求特殊,ETL工具大多为自己开发,或者在开源工具上再进行一些二次开发,在实际工作中,一个存储过程,一个shell/perl脚本,一个java程序等等,都可以作为ETL工具。
ETL过程中的元数据
试想一下,你作为一个新人接手别人的工作,没有文档,程序没有注释,数据库中的表和字段也没有任何comment,你是不是会骂娘了?业务系统发生改变,删除了一个字段,需要数据仓库也做出相应调整的时候,你如何知道改这个字段会对哪些程序产生影响?
。。。。
- 源系统表的字段及其含义,源系统数据库的IP、接口人,
- 数据仓库表的字段及其含义,
- 源表和目标表的对应关系,
- 一个任务对应的源表和目标表,任务之间的依赖关系,
- 任务每次执行情况等等等等,
这些元数据如果都能严格的管控起来,上面的问题肯定不会是问题了。。。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}