






一、工作流程
SAX(Simple API for XML)使用回调模型与用户代码交互,这是一种基于事件的编程模型。基于事件的编程模型的特点在于用户代码不是主动去执行,也就是说,它从来不会去指使XML解析器去做这做那,它是被动的,在等待被调用,然后才会去执行程序。
SAX由解析器和用户代码组成。在处理整个文档时,解析器负责逐个依次扫描文档元素,用户代码负责侦听事件并执行响应,当解析器遇到标签、文本等元素,都会触发相应的用户代码。在SAX的解析过程中,读取到文档开头、元素开头、元素内容、元素结尾、文档结尾分别会调用:startDocument()、startElement()、characters()、endElement()、endDocument()、开发人员可以根据需要,为感兴趣的事件编写相应的处理逻辑。
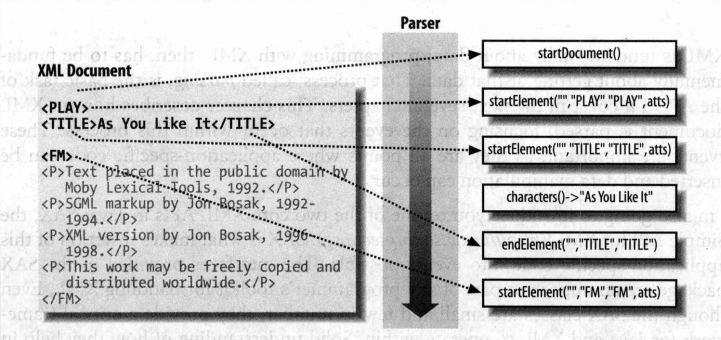
(若想知道文档元素是如何触发相应事件的,也许阅读SAX源代码会有些帮助?SAX源代码下载)
二、用户代码
查看Android API可知,startDocument()、startElement()、characters()、endElement()、endDocument() 这五个方法在 ContentHandler 接口中被定义,若想使用这五个方法,首先必须实现ContentHandler接口。
然而这里我们不需要直接去定义一个类去implements ContentHandler,因为Java已经帮我们做好了这个事情,DefaultHandler 类实现了ContentHandler接口并重写了上述的五个方法,但是都是空方法,”By default, do nothing. Application writers may override this method in a subclass to take specific actions”,在默认情况下,什么都不做,开发人员可以在子类中重写方法以便作出针对性的处理。
所以第一步,我们新建一个类并继承DefaultHandler,并重写父类的五个方法。
《第一行代码》书中把新建的类命名为ContentHandler,注意这里的ContentHandler为自定义的类名,不是org.xml.sax.ContentHandler,为避免混淆,建议将自定义的类名命名为SaxHandler、MyHandler等其它名字
如果按照书中的写法,将新建的类命名为ContentHandler,那么在MainActivity中使用
ContentHandler handler = new ContentHandler();时,不可以导入包org.xml.sax.ContentHandler!否则使用的ContentHandler就不是自定义的类了
public class MyHandler extends DefaultHandler {
@Override
public void startDocument() throws SAXException {
...
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) {
...
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
...
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
...
}
@Override
public void endDocument() throws SAXException {
}
}三、解析器
有以下两种方法实现解析器:
1. 使用XMLReader(《第一行代码》书中方法)
SAXParserFactory factory = SAXParserFactory.newInstance(); //新建工厂类
XMLReader xmlReader = factory.newSAXParser().getXMLReader(); //通过工厂类获取SAXParser类实例,并再次获取到XMLReader实例
MyHandler myHandler = new MyHandler();
xmlReader.setContentHandler(myHandler);
xmlReader.parse(new InputSource(new StringReader(response)));我们新建一个工厂类SAXParserFactory,让工厂类产生一个SAX的解析类SAXParser并从SAXPsrser中得到一个XMLReader实例。综上所述,SAX解析XML可以归纳为六个步骤:
新建一个工厂类SAXParserFactory
SAXParserFactory factory =SAXParserFactory.newInstance();让工厂类产生一个SAX的解析类SAXParser
SAXParser parser = factory.newSAXParser();从SAXParser中得到一个XMLReader实例
XMLReader reader = parser.getXMLReader();得到内容处理器
MyHandler myHandler = new MyHandler();把自己写的handler注册到XMLReader中
reader.setContentHandler(myHandler);将一个xml变成一个java可以处理的InputStream流后,解析开始
reader.parse(newInputSource(new FileInputStream("books.xml")));
或者把xml变成字符串,reader.parse(new InputSource(new StringReader(xmlString)));
2. 不使用XMLReader,直接使用SAXParser
上述的步骤1、2不变,产生SAX的解析类SAXParser后,不必获取到XMLReader类实例,查看API 可以看到SAXParser类下也有parse方法,直接使用parse方法解析,同时传入两个参数——要解析的数据和用户代码(回调的方法)
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
MyHandler myHandler = new MyHandler();
parser.parse(new InputSource(new StringReader(response)), myHandler);以上这两种方法解析所得的结果完全一致,任选一种方法即可,似乎第一种方法使用更广泛…至于为什么要对同样的目的设计两种方法,我不清楚,但是注意到XMLReader包含在由第三方提供的包org.xml.sax.XMLReader中。
3. 使用XMLReaderFactory获取XMLReader实例(注意要设置系统属性!)
在 1 中通过工厂类SAXParserFactory获取到SAXParser再获取到XMLReader,然而还可以通过另外的工厂类XMLReaderFactory,使用静态方法createXMLReader获取。XMLReader myReader = XMLReaderFactory.createXMLReader(); 。
然而这种方法可以通过编译,但是运行时会提示错误“Can’t create default XMLReader; is system property org.xml.sax.driver set?”。解决办法:在MainActivity类的onCreate方法中添加语句设置driver系统属性,System.setProperty("org.xml.sax.driver","org.xmlpull.v1.sax2.Driver");,通过这个语句将org.xml.sax.driver的值设定为org.xmlpull.v1.sax2.Driver即可。
- 可参考stackoverflow上的回答:why am I getting”Can’t create default XMLReader; is system property org.xml.sax.driver set?”
XMLReader xmlReader = XMLReaderFactory.createXMLReader();
MyHandler myHandler = new MyHandler();
xmlReader.setContentHandler(myHandler);
xmlReader.parse(new InputSource(new StringReader(response)));这样做可能的原因是:所有兼容SAX标准的XML解析器都必须实现SAX中的org.xml.sax.XMLReader接口,不同解析器提供商实现了接口的类的名字(或者包名)不同。那么实例化XMLReader时,利用不同提供商的类实例化所使用的语句也就不同。为了避免这种情况,才引入了XMLReaderFactory类,通过XMLReaderFactory.createXMLReader();方法统一了实例化的语句。但即使XMLReaderFactory类,也必须指定解析器提供商,通过设置org.xml.sax.driver属性来指定。
在写Java程序时,这个系统属性可以在运行时使用java -Dorg.xml.sax.driver=org.apache.xerces.parsers.SAXparser来指定。
- 对于java -D用法,可参考这篇文章。-> java程序启动参数-D是用来做什么的?
四、待解决问题
解析器读取标签之后还会读取一个空白本文,即使看上去那里并没有任何内容?
参考书籍:第一行代码Android、Java与XML(第三版)Oreilly&中国电力出版社















 1355
1355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









