







ML:定义
"A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E."
Example: playing checkers.
E = the experience of playing many games of checkers
T = the task of playing checkers.
P = the probability that the program will win the next game.
In general, any machine learning problem can be assigned to one of two broad classifications:
supervised learning, OR
unsupervised learning.
Supervised Learning
监督学习定义
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output.
We could turn this example into a classification problem by instead making our output about whether the house "sells for more or less than the asking price." Here we are classifying the houses based on price into two discrete categories.
Unsupervised Learning
非监督学习定义
Unsupervised learning, on the other hand, allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don't necessarily know the effect of the variables.
We can derive this structure by clustering the data based on relationships among the variables in the data.
With unsupervised learning there is no feedback based on the prediction results, i.e., there is no teacher to correct you.
ML:Linear Regression with One Variable
Model Representation
单输入参数线性回归定义
Recall that in regression problems, we are taking input variables and trying to fit the output onto a continuous expected result function.
Linear regression with one variable is also known as "univariate linear regression."
Univariate linear regression is used when you want to predict a single output value y from a single input value x. We're doing supervised learning here, so that means we already have an idea about what the input/output cause and effect should be.
The Hypothesis Function
假设函数的定义
y^=hθ(x)=θ0+θ1x
| input x | output y |
|---|---|
| 0 | 4 |
| 1 | 7 |
| 2 | 7 |
| 3 | 8 |
通过x,y拟合出一条y=kx+b的一元一次方程,这里使用的其实最小二乘法来完成k与b的解,最终将k与b带入到假设函数中,就是线性规划拟合出来的方程解,这里的是否让你想起高中课本中正态分布,没错这就正态分布的第一步,然后求假设函数的方差,再将方差带入到高斯函数中就是正态分布。
将b和k看作一个2*1的矩阵,将x看作一个1*2的矩阵第二列的值为1,将这两个足证相乘就可以得到假设函数
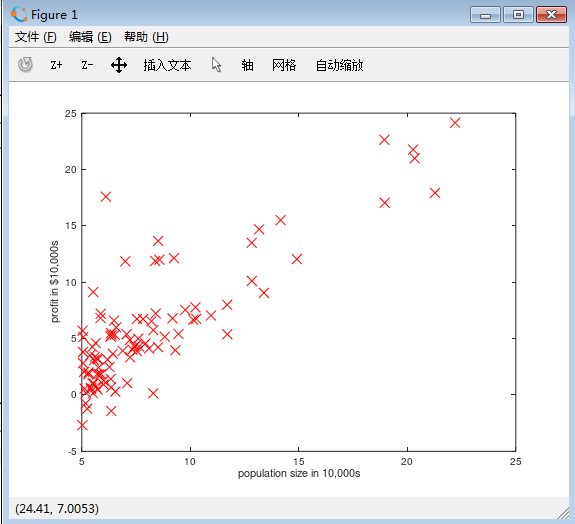
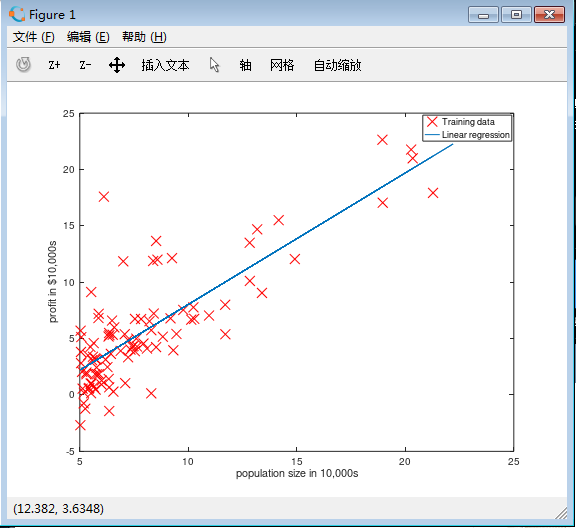
Cost Function
代价公式如下,代价函数其实就是对最小二乘法乘以1/2m进行优化。代价函数与方差公式很相似但又不是。这里也有人提出过为什么不用平方根,平方根增加了计算成本,所以将方差进行优化。
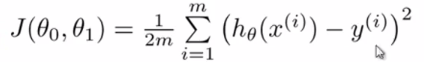
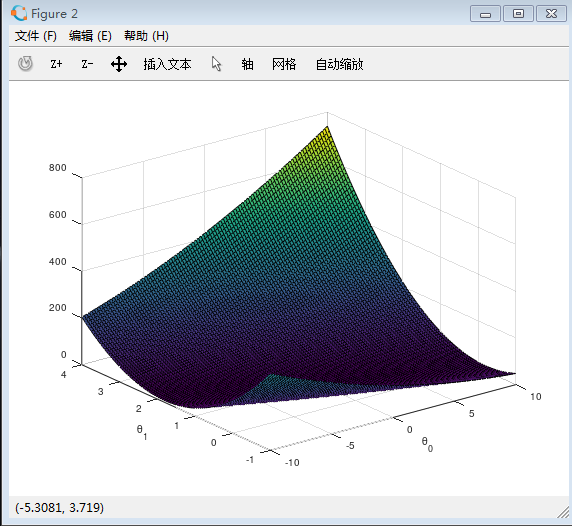
ML:Gradient Descent
梯度下降就是重复求代价函数的斜率,因为代价函数在不考虑假设函数b情况下相当于一个凹函数,所以代价函数有一个全局最小值,通过不断的减小斜率,可以得出代价函数的最小值,当代价函数最小时,其斜率为0.















 2891
2891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









