







 范数是衡量向量或矩阵大小的概念,包括l0、l1和l2范数。在机器学习中,正则化通过引入l1或l2范数避免过拟合,l1正则化产生稀疏模型,适合特征选择,l2正则化有助于权重衰减。L1正则化对应Laplace先验,L2正则化与Gaussian先验相对应。
范数是衡量向量或矩阵大小的概念,包括l0、l1和l2范数。在机器学习中,正则化通过引入l1或l2范数避免过拟合,l1正则化产生稀疏模型,适合特征选择,l2正则化有助于权重衰减。L1正则化对应Laplace先验,L2正则化与Gaussian先验相对应。
什么是范数?
范数,是具有 “长度” 概念的函数。在线性代数、泛函分析及相关的数学领域,范数是一个函数,是矢量空间内的所有矢量赋予非零的正长度或大小。
在数学上,范数包括向量范数和矩阵范数。
向量范数表征向量空间中向量的大小,矩阵范数表征矩阵引起变化的大小。 一种非严密的解释就是,对应向量范数,向量空间中的向量都是有大小的,这个大小如何度量,就是用范数来度量的,不同的范数都可以来度量这个大小,就好比米和尺都可以来度量远近一样;对于矩阵范数,学过线性代数,我们知道,通过运算 AX=B,可以将向量 X 变化为 B,矩阵范数就是来度量这个变化大小的。
向量的范数可以简单形象的理解为向量的长度,或者向量到零点的距离,或者相应的两个点之间的距离。
范数的定义
将任意向量
x
x
x的
l
p
l_p
lp范数定义为:
∣
∣
x
∣
∣
p
=
∑
i
∣
x
i
∣
p
p
||x||_p=\sqrt[p]{\sum_i|x_i|^p}
∣∣x∣∣p=pi∑∣xi∣p
当
p
=
0
p=0
p=0,就有了
l
0
l_0
l0范数,即
∣
∣
x
∣
∣
0
=
∑
i
x
i
0
0
||x||_0=\sqrt[0]{\sum_i{x_i}^0}
∣∣x∣∣0=0∑ixi0,表示向量
x
x
x中非0元素的个数。
在诸多机器学习模型中,我们很多时候希望最小化向量的
l
0
l0
l0范数。然而,由于
l
0
l0
l0范数仅仅表示向量中非0元素的个数,因此,这个模型被认为是一个NP-hard问题,即直接求解它很复杂。因此,可以把它转换成
l
1
l1
l1范数最小化问题。
当
p
=
1
p=1
p=1,为
l
1
l1
l1范数,即
∣
∣
x
∣
∣
1
=
∑
i
∣
x
i
∣
||x||_1=\sum_i{|x_i|}
∣∣x∣∣1=∑i∣xi∣,等于向量中所有元素绝对值之和。相应的,一个
l
1
l1
l1范数优化问题为:
m
i
n
∣
∣
x
∣
∣
1
min||x||_1
min∣∣x∣∣1
s
.
t
.
A
x
=
b
s.t.Ax=b
s.t.Ax=b
这个问题相比于
l
0
l_0
l0范数优化问题更容易求解,借助现有凸优化算法,就能够找到我们想要的可行解。
当
p
=
2
p=2
p=2,为
l
2
l2
l2范数,表示向量或矩阵的元素平方和,即
∣
∣
x
∣
∣
2
=
∑
i
x
i
2
||x||_2=\sqrt{\sum_i{x_i}^2}
∣∣x∣∣2=∑ixi2,
l
2
l2
l2范数的优化模型如下:
m
i
n
∣
∣
x
∣
∣
2
min||x||_2
min∣∣x∣∣2
s
.
t
.
A
x
=
b
s.t.Ax=b
s.t.Ax=b
正则项与模型
为了避免过拟合的问题,一种解决办法是在模型的损失函数中加入正则项。对于线性回归模型,使用 l 1 l1 l1正则化的模型叫做Lasso回归,使用 l 2 l2 l2正则化的模型叫做Ridge回归。
l
1
l1
l1范数表示的正则项,可以产生稀疏权值矩阵(很多元素为0,只有少数元素是非零的矩阵),即产生一个稀疏模型,可以用于特征选择。
l
2
l2
l2范数表示的正则项可以防止模型过拟合,一定程度上,
l
1
l1
l1也可以防止过拟合。
参数的稀疏意味着什么?
一个模型中真正重要的参数可能并不多,另外参数变少可以使整个模型获得更好的可解释性。
参数值越小代表模型越简单吗?
是的。因为越复杂的模型,越是会尝试对所有的样本进行拟合,甚至包括一些异常样本点,这就容易造成在较小的区间里预测值产生较大的波动,这种较大的波动也反映了在这个区间里的导数很大,而只有较大的参数值才能产生较大的导数。因此复杂的模型,其参数值会比较大。
为什么
l
1
l1
l1相比于
l
2
l2
l2更容易获得稀疏解?
损失函数:
m
i
n
L
1
(
w
)
=
m
i
n
f
(
w
)
+
λ
n
∑
∣
w
i
∣
minL_1(w)=minf(w)+\frac{\lambda}{n}\sum{|w_i|}
minL1(w)=minf(w)+nλ∑∣wi∣,
m
i
n
L
2
(
w
)
=
m
i
n
f
(
w
)
+
λ
2
n
∑
w
i
2
minL_2(w)=minf(w)+\frac{\lambda}{2n}\sum{w_i^2}
minL2(w)=minf(w)+2nλ∑wi2
分别求导:
d
L
1
(
w
)
d
w
i
=
d
f
(
w
)
d
w
i
+
λ
n
s
i
g
n
(
w
i
)
\frac{\text{d}L1(w)}{\text{d}w_i}=\frac{\text{d}f(w)}{\text{d}w_i}+\frac{\lambda}{n}sign(w_i)
dwidL1(w)=dwidf(w)+nλsign(wi)
w
i
←
w
i
−
η
d
f
(
w
)
d
w
i
−
η
λ
n
s
i
g
n
(
w
i
)
w_i\leftarrow{w_i-\eta{\frac{\text{d}f(w)}{\text{d}w_i}}-\eta{\frac{\lambda}{n}sign(w_i)}}
wi←wi−ηdwidf(w)−ηnλsign(wi)
得到
w
i
w_i
wi的更新公式。
d
L
2
(
w
)
d
w
i
=
d
f
(
w
)
d
w
i
+
λ
n
w
i
\frac{\text{d}L2(w)}{\text{d}w_i}=\frac{\text{d}f(w)}{\text{d}w_i}+\frac{\lambda}{n}w_i
dwidL2(w)=dwidf(w)+nλwi
w
i
←
w
i
−
η
d
f
(
w
)
d
w
i
−
η
λ
n
w
i
w_i\leftarrow{w_i-\eta{\frac{\text{d}f(w)}{\text{d}w_i}}-\eta{\frac{\lambda}{n}w_i}}
wi←wi−ηdwidf(w)−ηnλwi
得到
w
i
w_i
wi的更新公式。
可以想象用梯度下降的方法,当
w
w
w大于1时,
l
2
l2
l2正则项获得比
l
1
l1
l1正则项更快的减小速率;当
w
w
w小于1的时候,
l
2
l2
l2正则项的惩罚效果越来越小,
l
1
l1
l1正则项惩罚效果依然很大。
l
1
l1
l1可以惩罚到0,而
l
2
l2
l2很难。因此
l
1
l1
l1正则项会获得更多的接近于0的
w
w
w,即
l
1
l1
l1比
l
2
l2
l2的参数更稀疏。
由此可得,
l
1
l1
l1正则项更偏向于特征选择,
l
2
l2
l2正则项更偏向于权重衰减。
正则项与先验
如果从贝叶斯的观点来看,所有的正则化都是来自于对参数分布的先验。
先验的意思是对一种未知的东西的假设,比如我们看到一个正方体的骰子,那么我们会假设它的各个面朝上的概率是1/6,这个就是先验。但事实上骰子的材质可能是密度不均的,所以还要从数据集中学习到更接近现实情况的概率。同样,在机器学习中,我们会根据一些已知的知识对参数的分布进行一定的假设,这就是先验。有先验的好处就是可以在较小的数据集中有良好的泛化性能,当然这是在先验分布是接近真实分布的情况下得到的,从信息论的角度来看,向系统中加入了正确先验这个信息,肯定会提高系统的性能。
L1正则化和Laplace先验
Laplace的概率密度函数为:
f
(
x
∣
μ
,
b
)
=
1
2
b
e
x
p
(
−
∣
x
−
μ
∣
b
)
f(x|\mu,b)=\frac{1}{2b}exp(-\frac{|x-\mu|}{b})
f(x∣μ,b)=2b1exp(−b∣x−μ∣)
分布集中在
μ
\mu
μ附近,且b越小,分布越集中。
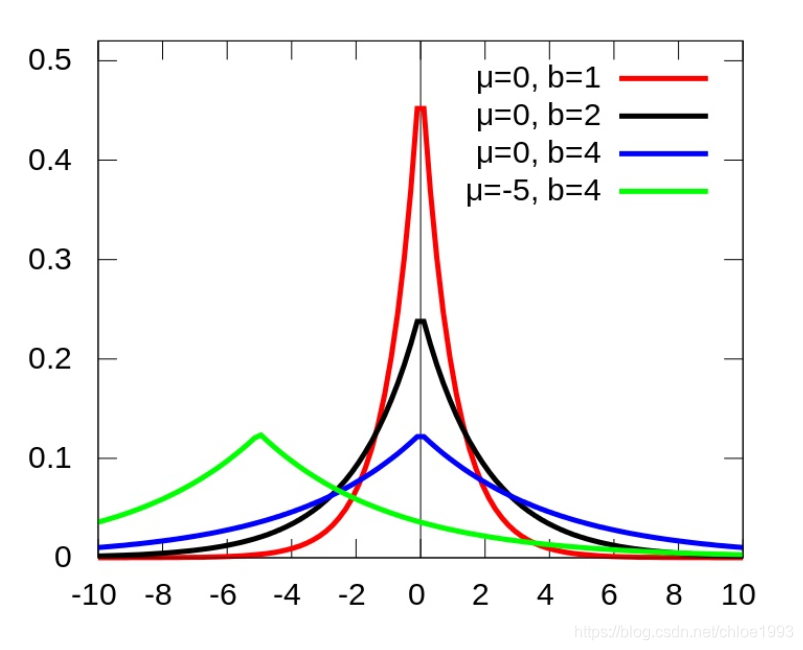
最大似然估计:
以线性规划作为例子,线性模型为:
f
(
X
)
=
∑
x
(
x
i
θ
i
)
+
ϵ
=
X
θ
T
+
ϵ
f(X)=\sum_x{(x_i\theta_i)+\epsilon}=X\theta^T+\epsilon
f(X)=x∑(xiθi)+ϵ=XθT+ϵ
ϵ
\epsilon
ϵ是噪声,即
ϵ
\epsilon
ϵ~
N
(
0
,
δ
2
)
N(0, \delta^2)
N(0,δ2)。那么对于一对数据
(
X
i
,
Y
i
)
(X_i, Y_i)
(Xi,Yi),在这个模型中用
X
i
X_i
Xi得到
Y
i
Y_i
Yi的概率是
Y
i
Y_i
Yi~
N
(
f
(
X
i
)
,
δ
2
)
N(f(X_i),\delta^2)
N(f(Xi),δ2):
P
(
Y
i
∣
X
i
,
θ
)
=
1
δ
2
π
e
x
p
(
−
∣
∣
f
(
X
i
)
−
Y
i
∣
∣
2
2
δ
2
)
P(Y_i|X_i,\theta)=\frac{1}{\delta\sqrt{2\pi}}exp(-\frac{||f(X_i)-Y_i||^2}{2\delta^2})
P(Yi∣Xi,θ)=δ2π1exp(−2δ2∣∣f(Xi)−Yi∣∣2)
假设数据集中每一对数据都是独立的,那么对于数据集来说:
P
(
Y
∣
X
,
θ
)
=
∏
1
δ
2
π
e
x
p
(
−
∣
∣
f
(
X
i
)
−
Y
i
∣
∣
2
2
δ
2
)
P(Y|X,\theta)=\prod{\frac{1}{\delta\sqrt{2\pi}}exp(-\frac{||f(X_i)-Y_i||^2}{2\delta^2})}
P(Y∣X,θ)=∏δ2π1exp(−2δ2∣∣f(Xi)−Yi∣∣2)
是概率
P
(
Y
∣
X
,
θ
)
P(Y|X,\theta)
P(Y∣X,θ)最大的参数
θ
∗
\theta^*
θ∗就是最好的参数。根据极大似然估计:
θ
∗
=
a
r
g
m
a
x
(
∏
1
ϵ
2
π
e
x
p
(
−
∣
∣
f
(
X
i
)
−
Y
i
∣
∣
2
2
δ
2
)
)
=
a
r
g
m
a
x
(
−
1
2
δ
2
∑
∣
∣
f
(
X
i
)
−
Y
i
∣
∣
2
+
∑
l
n
(
δ
2
π
)
)
=
a
r
g
m
i
n
(
∑
∣
∣
f
(
X
i
)
−
Y
i
∣
∣
2
)
\theta^*=argmax(\prod{\frac{1}{\epsilon\sqrt{2\pi}}exp(-\frac{||f(X_i)-Y_i||^2}{2\delta^2})})=argmax(-\frac{1}{2\delta^2}\sum{||f(X_i)-Y_i||^2}+\sum{ln(\delta\sqrt{2\pi})})=argmin(\sum||f(X_i)-Y_i||^2)
θ∗=argmax(∏ϵ2π1exp(−2δ2∣∣f(Xi)−Yi∣∣2))=argmax(−2δ21∑∣∣f(Xi)−Yi∣∣2+∑ln(δ2π))=argmin(∑∣∣f(Xi)−Yi∣∣2)
(最小二乘公式)
极大似然估计中假设的
θ
\theta
θ是均匀分布的,如果假设参数
θ
\theta
θ是Laplace分布,那么
P
(
θ
i
)
=
λ
2
e
x
p
(
−
λ
∣
θ
i
∣
)
P(\theta_i)=\frac{\lambda}{2}exp(-\lambda|\theta_i|)
P(θi)=2λexp(−λ∣θi∣)
其中
λ
\lambda
λ是控制参数
θ
\theta
θ集中情况的超参数,
λ
\lambda
λ越大那么参数的分布就越集中在0附近。
则
θ
∗
=
a
r
g
m
i
n
(
∑
∣
∣
f
(
X
i
)
−
Y
i
∣
∣
2
+
λ
∑
∣
θ
i
∣
)
\theta^*=argmin(\sum{||f(X_i)-Y_i||^2}+\lambda\sum{|\theta_i|})
θ∗=argmin(∑∣∣f(Xi)−Yi∣∣2+λ∑∣θi∣)
这就是由Laplace导出
l
1
l1
l1正则化。
L2和Gaussian先验
假设参数
θ
\theta
θ的分布是符合以下的高斯分布:
P
(
θ
i
)
=
λ
π
e
x
p
(
−
λ
∣
∣
θ
∣
∣
2
)
P(\theta_i)=\frac{\lambda}{\sqrt{\pi}}exp(-\lambda||\theta||^2)
P(θi)=πλexp(−λ∣∣θ∣∣2)
则
θ
∗
=
a
r
g
m
i
n
(
∑
∣
∣
f
(
X
i
)
−
Y
i
∣
∣
2
+
λ
∑
∣
∣
θ
i
∣
∣
2
)
\theta^*=argmin(\sum{||f(X_i)-Y_i||^2+\lambda\sum{||\theta_i||^2}})
θ∗=argmin(∑∣∣f(Xi)−Yi∣∣2+λ∑∣∣θi∣∣2)
参考文献
什么是范数
如何通俗易懂地解释范数?
L1,L2,L0区别,为什么可以防止过拟合
Laplace(拉普拉斯)先验与L1正则化

















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









