






摘要
本周主要看了一篇GNN的论文,与以往普通的GNN通过聚合邻居节点的特征来更新节点不同,RWGNN利用随机游走来采样图中的节点序列,并将这些序列作为输入进行学习。其次,本周我还跟师兄学习了GNN方向写论文该怎么入手。在代码学习上,本周主要的学习内容是找了一个GNN-LSTM的模型学习搭建。其次,因为前面两周没怎么学数学建模,这周又看了一些pandas的代码。
This week, I mainly read a paper on GNN. Unlike the conventional GNN that updates nodes by aggregating the features of neighboring nodes, RWGNN utilizes random walks to sample node sequences in the graph and learns from these sequences as inputs. Additionally, I learned from my senior colleague about how to start writing a paper in the GNN field. Regarding coding, my main focus this week was learning to build a GNN-LSTM model. Furthermore, since I didn’t study much mathematical modeling in the previous two weeks, I also looked at some code related to pandas this week.
文献阅读
**题目:**Random Walk Graph Neural Networks
文章地址:https://www.lix.polytechnique.fr/~nikolentzos/files/rw_gnns_neurips20
**作者:**Giannis Nikolentzos, Michalis Vazirgiannis
摘要
近年来,图神经网络(GNNs)已成为在图上执行机器学习任务的实际工具。大多数GNN属于消息传递神经网络族(MPNNs)。这些模型采用迭代邻域聚合(neighborhood aggregation)方案来更新顶点表示。然后,为了计算图的向量表示,它们使用一些置换不变函数(permutation invariant function)来聚合顶点的表示。因此,MPNN将图形视为集合,因此似乎忽略了从图形拓扑中产生的特征。
本文提出了一种更直观、更透明的图形结构数据体系结构,即随机步行图神经网络(RWNN)。模型的第一层由许多可训练的“隐藏图”组成,这些图与使用随机游走核(random walk kernel)产生图形表示的输入图进行比较。然后将这些表示传递给产生输出的完全连接的神经网络。所采用的随机游走核是可微的,因此该模型是端到端可训练的。演示了模型在合成数据集上的透明度。 此外,在图分类数据集上对模型进行了实证评估,并表明它具有很强的性能。
介绍
虽然近几年提出了许多GNN变体,但它们中的大多数都有相同的基本思想,可以重新制定为一个单一的共同框架,即所谓的消息传递神经网络(MPNNs)。这些模型使用消息传递过程来聚合顶点的局部信息。对于与图相关的任务,MPNN通常将一些置换不变函数应用于顶点表示,以产生整个图的表示。常见的readout 函数将每个图视为一组顶点表示,从而忽略了顶点之间的相互作用。注:这些相互作用被隐式编码到消息传递过程产生的学习顶点表示中。 然而,由于图结构与特征信息相结合带来的透明度不足,这一点很难得到验证。
在深度学习出现之前,图核graph kernels已经成为在图上执行机器学习任务的标准方法。图核是在图的空间上定义的对称正半定函数。核方法的复杂度,神经网络模型可以学习对特定任务有用的表示,使得核方法在很大程度上被GNN所掩盖。不同于核函数直接比较图模型,MPNNs首先通过聚合其顶点的表示将图转换为向量,然后将一些函数(多层感知器)应用于这些图表示。GNN模型对学到内容的缺乏解释性,理想情况下,希望有一个模型,它直接将某些函数应用于输入图,而不首先将它们转换为向量。
论文中,提出了随机游走图神经网络(RWNN)。 该模型包含许多可训练的“隐藏图”,并使用随机游走核比较输入图与这些图。然后将核值传递给产生输出的完全连接的神经网络。 所使用的随机游走核是可微的,因此可以在训练过程中用反向传播来更新“隐藏图”。所提出的神经网络是端到端可训练的。该方法保留了核方法应用于结构化数据的灵活性,也学习任务相关的特征,而不需要特征工程。
贡献
-
提出了一种新的图神经网络架构:该论文引入了一种名为Random Walk Graph Neural Network(RWNN)的新型图神经网络架构。RWNN采用随机游走核函数比较可训练的“隐藏图”与输入图,以生成图的表示。这种架构相对于传统的消息传递神经网络(MPNNs)更直观和透明。
-
引入可微分的随机游走核函数:RWNN使用可微分的随机游走核函数来比较隐藏图和输入图。这种核函数的可微性使得RWNN能够进行端到端的训练,从而可以通过梯度下降等优化算法有效地学习模型参数。
-
模型透明性的提升:RWNN架构在处理合成数据集时展示了其模型的透明性。相对于传统的图神经网络,RWNN的模型结构更易理解和解释,有助于揭示模型如何处理图结构数据以及如何编码感兴趣的信息。
-
实证评估与竞争性性能:论文对RWNN进行了实证评估,并在图分类数据集上进行了实验。结果表明,RWNN在这些数据集上取得了有竞争力的性能,展示了其在图数据分析任务中的潜力和优势。
总结起来就是,提出了一种新颖的图神经网络架构(RWNN),引入了可微分的随机游走核函数,并展示了其在模型透明性和图分类任务中的优越性能。
相关工作
在相关工作这块,作者主要回顾了与论文主题相关的研究工作,包括图核方法、图神经网络(GNNs)、图表示学习等方面。
-
图核方法:图核方法在图分类任务中占据主导地位。图核是对称正半定核函数,使得核方法能够应用于图领域的任务。图核方法比较输入图中不同类型的子结构,例如随机游走、最短路径、子树、图片段等。
-
图神经网络(GNNs):GNNs在过去几年引起了广泛关注。论文介绍了一些经典的GNN模型和方法,包括基于图拉普拉斯矩阵的卷积操作、使用切比雪夫多项式表示谱滤波器等。此外,论文指出这些模型都可以归结为一个简单的消息传递框架(MPNNs),并列举了一些最近提出的GNNs模型。
-
图表示学习:论文回顾了一些图表示学习的方法和技术,例如DeepWalk、Node2Vec、GraphSAGE等。这些方法旨在学习节点或图的低维表示,以捕捉图的结构和特征。
论文还提到了其他与图核和GNNs相关的工作,如使用图核预训练GNNs、将图核提取的特征传递给卷积神经网络等。最后,论文指出与他们提出的模型最相关的工作是[23],该工作提出了一类生成表示的GNNs,这些表示与随机游走核或WL核相关。然而,与他们的模型不同的是,他们的参数与图的邻接矩阵和特征矩阵相对应。
Preliminaries部分
这部分作者主要讲了一些预备知识,方便我们读后续的内容。
图形分类问题
形式上给定一组图形
{
G
1
,
,
,
,
,
,
G
N
}
⊆
G
\{G_{1},,,,,,G_{N}\} ⊆ G
{G1,,,,,,GN}⊆G
和他们的分类标签
y
1
,
…
,
y
N
⊆
Y
{ y_{1} , … , y_{N} } ⊆ Y
y1,…,yN⊆Y,目标学习一个特征向量
h
G
h G
hG ,可以预测图形
G
G
G标签
y
G
y G
yG
=
f
(
h
G
)
= f ( h G )
=f(hG)。该模型还可以处理其他与图形相关的任务,如图形回归问题。
设 G = ( V , E ) G = ( V , E ) G=(V,E)表示无向图,顶点数为n,边数为m,邻接矩阵 A ∈ R n ∗ n A ∈ R^{n*n} A∈Rn∗n是一个对称(通常是稀疏)矩阵,用于在图中编码边缘信息。对于节点分布图,图中的每个节点都与特征向量相关联。节点的特征 X ∈ R n × d X ∈ R ^{n × d} X∈Rn×d,第i行是第i个节点的特征。
给定两个图
[
G
=
(
V
,
E
)
]
[G=(V,E)]
[G=(V,E)]和
[
G
’
=
(
V
’
,
E
’
)
]
[G’=(V’,E’)]
[G’=(V’,E’)],它们的直接积 G × = ( V × , E × ) 是一个图有顶点集合 $V × = { ( v , v ′ ) : v ∈ V ∧ v ′ ∈ V ′ } $和边集
E
×
=
(
v
,
v
′
)
,
(
u
,
u
′
)
:
v
,
u
∈
E
∧
v
′
,
u
′
∈
E
′
E × = { { ( v , v ′ ) , ( u , u ′ ) } : { v , u } ∈ E ∧ { v ′ , u ′ } ∈ E ′ }
E×=(v,v′),(u,u′):v,u∈E∧v′,u′∈E′
**
比如:
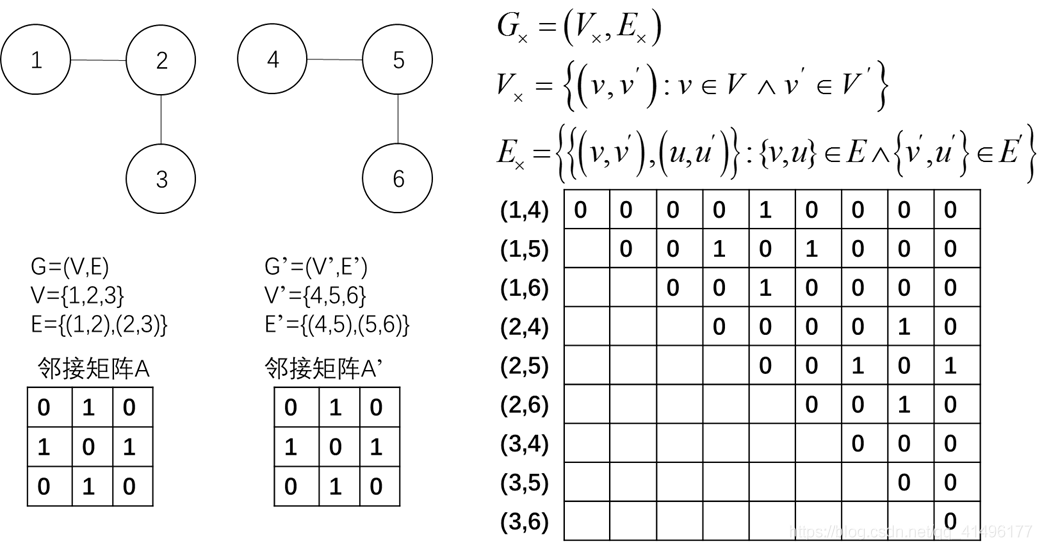
随机游走GNNs
图的神经网络设计的主要挑战之一是如何处理置换不变性。图的顶点的任何排列都会产生一个结构相同的图。因此,无论图的顶点排序如何,GNN的输出都是相同的。图通常由其邻接矩阵表示,也可能由包含其顶点属性的矩阵表示。给定一个图G的邻接矩阵A,该模型对于所有矩阵 P A P ⊤ P A P ^{⊤} PAP⊤产生相同的输出是必要的,其中 P ∈ Π P∈Π P∈Π, Π Π Π表示 n × n n×n n×n个置换矩阵的集合。大多数MPNN是通过将一些置换不变函数应用于顶点表示来实现的(函数例如,和,最大,平均算子)。其他GNN通常使用一些启发式方法,通过对图的顶点施加排序来实现不变性。 在本文中,提出了一种不同的方法来获得图形表示。利用图核中已建立的概念,并利用函数来比较对其输入顶点排列不变的图。
作者把提出的RWNN模型将输入图与许多“隐藏图”进行比较,即图的邻接矩阵和属性矩阵是可训练的。提出的模型中包含N个隐藏图,这些图的定点数目(图的大小)不尽相同。这些图可以是未标记的,也可以用连续的多维特征注释它们的顶点。这些“隐藏图”的结构和顶点属性(若存在)是可训练的,即大小为n的“隐藏图”Gi的邻接矩阵由可训练矩阵 W i ∈ R n × n W i ∈ R ^{n × n} Wi∈Rn×n*表示,而顶点属性包含在另一个可训练矩阵 Z i ∈ R n × d Z i ∈ R^{ n × d} Zi∈Rn×d*的行中。注,“隐藏图”可以是带或不带自循环的加权有向或无向图。在实验中,将其约束为无向图,且不需要自循环(n(n-1)/2个可训练参数)。由于“隐藏图”的结构适合于手头的任务,因此所提出的模型具有很高的可解释性。通过可视化训练阶段结束时“隐藏图”的结构,可以更直观地理解所考虑的问题。这些图将学习允许模型区分可用类的结构。
与现有的方法相比,本文将输入图映射到向量,将它们与模型的N个“隐藏图”进行比较。注,图比较算法需要是可微的,才能使网络达到端到端的训练。否则,“隐藏图”的结构和属性无法在反向传播训练期间学习(大多比较图的算法都是不可微的)。对于不可微图比较算法,在训练过程中,“隐藏图”可以保持不变。然而,这将大大限制模型的表现力。在本文中,提出了一个可微函数,用于比较图之间的关系,属于随机游走核族。一般来说,随机游走核根据两个图中常见游走的数量来量化两个图的相似性。在随机游走核的众多变化中,本文重点研究了P步随机游走核,它比较了两个图中长度为P的随机游走。
在两个图 G G G和 G ’ G’ G’的直接积 G × G× G×(在第3节中引入)上执行随机游走相当于在两个图 G G G和 G ’ G’ G’上同时执行随机游走。 G × G× G×的邻接矩阵为 A × A× A×。如上所述,随机游走内核计数 G G G和 G G G’上的所有匹配游走对。假设在 G G G和 G 0 G0 G0的顶点上的开始和停止概率为均匀分布,通过积图 G × G× G×的邻接矩阵 A × A× A×可以得到匹配步数。给定一些 P ∈ N P∈N P∈N,将两个图 G G G和 G ’ G’ G’之间的 P P P步随机游走核定义为:
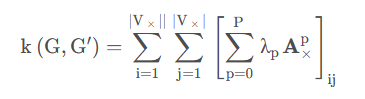
所提出的RWNN模型计算了P步随机游走核的一个轻微变体,它计算了两个图 G G G和 G ’ G’ G’之间的公共长度步数:
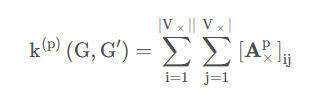
(邻接矩阵的p次方,即随机走p步后的邻接矩阵)。对于不同的p可以得到不同的核值。这些核值可以被认为是输入图的特征。因此,给定两个集合 P = 0 , 1 , . . . , P P = {0, 1, . . . , P } P=0,1,...,P 和 G h = G 1 , G 2 , . . . , G N Gh = {G1, G2, . . . , GN } Gh=G1,G2,...,GN,其中 G 1 , G 2 , . . . , G N G1, G2, . . . , GN G1,G2,...,GN 表示 N 个"隐藏图",我们可以为 P × G h P × Gh P×Gh的每个元素计算一个特征。对于每个输入图 G,我们可以构建一个矩阵 H ∈ R N × P H ∈ RN ×P H∈RN×P,其中 H i j = k ( j − 1 ) ( G , G i ) Hij = k(j−1)(G, Gi) Hij=k(j−1)(G,Gi)。然后,将矩阵 H 展平并输入到一个全连接神经网络中以产生输出。
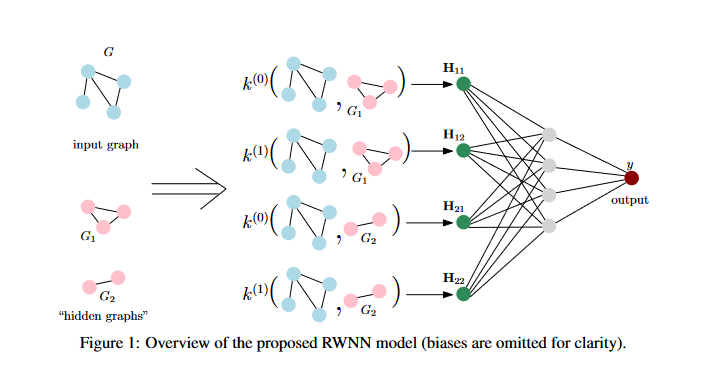
但是,上面提出的体系结构不能处理顶点被实值多维顶点属性注释的图。接下来,将上述函数推广到包含此类顶点属性的图。首先,我们定义矩阵 A ∈ R n c × n c A ∈ Rnc×nc A∈Rnc×nc为一个对角矩阵,其中对角线上的元素 Aii 表示第 i 个隐藏图和输入图 G 之间共同路径长度为 p 的数量。我们进一步定义矩阵 B ∈ R n c × n c B ∈ Rnc×nc B∈Rnc×nc 为一个对角矩阵,其中对角线上的元素 Bii 表示第 i 个隐藏图和输入图 G 之间共同路径长度小于等于 p 的数量。然后,我们可以通过计算矩阵 A 和矩阵 B 的差值来得到两个图之间共同路径长度恰好为 p 的核值。具体而言,我们定义矩阵 C ∈ R n c × n c C ∈ Rnc×nc C∈Rnc×nc为 C = A − B C = A - B C=A−B。矩阵 C 的(i, j)元素表示第 i 个隐藏图和输入图 G 之间共同路径长度恰好为 p 的数量减去共同路径长度小于等于 p 的数量。最后,我们将矩阵 C 展平为一个向量,并将其作为输入传递给一个全连接神经网络,以产生最终的输出。
总体来说,就是给定输入图 G 和一组隐藏图 Gh = {G1, G2, . . . , GN},我们可以使用矩阵运算和全连接神经网络来计算两个图之间共同路径长度恰好为 p 的核值,并生成最终的输出。
实验评估
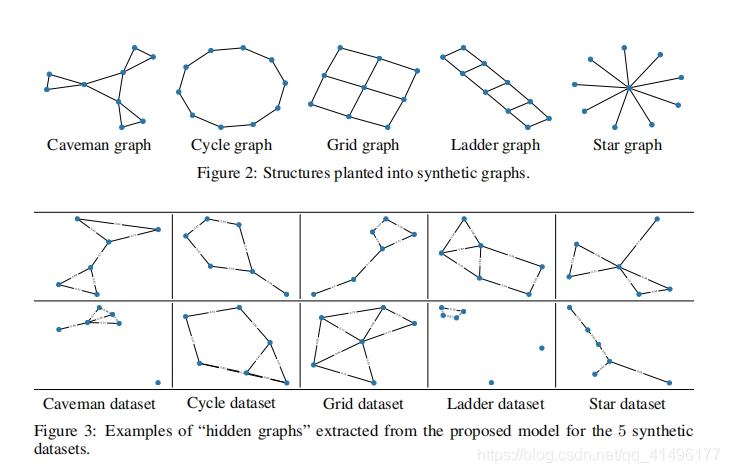
数据集:创建了5个二分类数据集,每个数据集具有1000个合成图。
结果:图3显示了5个数据集中的每个数据集的两个“隐藏图”。 “隐藏图”及其相应的基序具有一些相似的性质。
总结
本文提出了一种新的RWNN神经网络结构,用于在图上执行机器学习任务。 该模型通过一组可训练的“隐藏图”对输入图生成图形表示,使用P步随机游走核的变体。所进行的实验突出了所提出的模型的高可解释性及其在公开数据集上的有效性。
另外,看论文的同时有些不懂的查资料后记的如下:
置换不变函数:
置换不变函数是指在给定集合上的函数,对于集合中的任意两个元素进行置换(交换位置)操作后,函数的取值不发生变化。
具体来说,设集合为X,函数为f:X → Y,其中X是一个集合,Y是一个集合。对于X中的任意两个元素x1和x2,如果对x1和x2进行置换得到新的集合X’,且有 f(x1) = f(x2) 且 f(x1’) = f(x2’) 对于所有x1’和x2’属于X’成立,那么函数f被称为置换不变函数。
换句话说,对于任意的置换操作,函数f的输出结果保持不变。
例如,假设X是一个集合{1, 2, 3, 4},Y是一个集合{a, b, c, d},并且定义函数f如下:f(1) = a ,f(2) = b ,f(3) = c ,f(4) = d。对于任意的置换操作,例如将1和2进行置换,得到新的集合X’={2, 1, 3, 4},函数f的输出结果保持不变:f(2’) = f(1) = a, f(1’) = f(2) = b, f(3’) = f(3) = c ,f(4’) = f(4) = d,因此,函数f是置换不变函数。
图核:
图核(Graph Kernels)是用于度量和比较图形数据相似性的一类函数。图核可以将两个或多个图形作为输入,并计算它们之间的相似度或距离。它们是一种将图形转化为向量空间中的距离或内积的方法,从而可以应用常见的机器学习算法进行图形分类、聚类和回归等任务。
图核的设计旨在捕捉图形的结构信息和拓扑特征,使得相似的图形在向量空间中距离较近,而不相似的图形距离较远。常见的图核方法基于子结构比较,即比较图形中的子图或子结构的相似性。
常见的图核方法包括:
-
子图核(Subgraph Kernels):比较两个图形中相同类型的子图的出现频率或相似性。
-
随机游走核(Random Walk Kernels):基于图形中随机游走的路径,计算路径之间的相似性。
-
图谱核(Spectrum Kernels):基于图形的谱信息,例如图拉普拉斯矩阵的特征值,来度量图形之间的相似性。
-
图编辑距离核(Graph Edit Distance Kernels):通过计算将一个图形转换为另一个图形所需的最小编辑操作(如插入、删除和替换节点等)的次数来比较图形之间的相似性。
-
核矩阵合并(Kernel Matrix Combination):将不同类型的核函数结合起来,以获得更全面的图形相似性度量。
代码学习
建模,Pandas代码学习
合并Concat:Pandas 提供了多种将 Series、DataFrame 对象组合在一起的功能,用索引与关联代数功能的多种设置逻辑可执行连接(join)与合并(merge)操作。
concat()用于连接 Pandas 对象:
In [73]: df = pd.DataFrame(np.random.randn(10, 4))
In [74]: df
Out[74]:
0 1 2 3
0 -0.548702 1.467327 -1.015962 -0.483075
1 1.637550 -1.217659 -0.291519 -1.745505
2 -0.263952 0.991460 -0.919069 0.266046
3 -0.709661 1.669052 1.037882 -1.705775
4 -0.919854 -0.042379 1.247642 -0.009920
5 0.290213 0.495767 0.362949 1.548106
6 -1.131345 -0.089329 0.337863 -0.945867
7 -0.932132 1.956030 0.017587 -0.016692
8 -0.575247 0.254161 -1.143704 0.215897
9 1.193555 -0.077118 -0.408530 -0.862495
# 分解为多组
In [75]: pieces = [df[:3], df[3:7], df[7:]]
In [76]: pd.concat(pieces)
Out[76]:
0 1 2 3
0 -0.548702 1.467327 -1.015962 -0.483075
1 1.637550 -1.217659 -0.291519 -1.745505
2 -0.263952 0.991460 -0.919069 0.266046
3 -0.709661 1.669052 1.037882 -1.705775
4 -0.919854 -0.042379 1.247642 -0.009920
5 0.290213 0.495767 0.362949 1.548106
6 -1.131345 -0.089329 0.337863 -0.945867
7 -0.932132 1.956030 0.017587 -0.016692
8 -0.575247 0.254161 -1.143704 0.215897
9 1.193555 -0.077118 -0.408530 -0.862495
## 连接
In [82]: left = pd.DataFrame({'key': ['foo', 'bar'], 'lval': [1, 2]})
In [83]: right = pd.DataFrame({'key': ['foo', 'bar'], 'rval': [4, 5]})
In [84]: left
Out[84]:
key lval
0 foo 1
1 bar 2
In [85]: right
Out[85]:
key rval
0 foo 4
1 bar 5
In [86]: pd.merge(left, right, on='key')
Out[86]:
key lval rval
0 foo 1 4
1 bar 2 5
- 按位置选择:
## 整数位置选择
In [32]: df.iloc[3]
Out[32]:
A 0.721555
B -0.706771
C -1.039575
D 0.271860
Name: 2013-01-04 00:00:00, dtype: float64
## 整数切片
In [33]: df.iloc[3:5, 0:2]
Out[33]:
A B
2013-01-04 0.721555 -0.706771
2013-01-05 -0.424972 0.567020
## 整数列表按位置切片
In [34]: df.iloc[[1, 2, 4], [0, 2]]
Out[34]:
A C
2013-01-02 1.212112 0.119209
2013-01-03 -0.861849 -0.494929
2013-01-05 -0.424972 0.276232
- 分组
In [91]: df = pd.DataFrame({'A': ['foo', 'bar', 'foo', 'bar',
....: 'foo', 'bar', 'foo', 'foo'],
....: 'B': ['one', 'one', 'two', 'three',
....: 'two', 'two', 'one', 'three'],
....: 'C': np.random.randn(8),
....: 'D': np.random.randn(8)})
....:
In [92]: df
Out[92]:
A B C D
0 foo one -1.202872 -0.055224
1 bar one -1.814470 2.395985
2 foo two 1.018601 1.552825
3 bar three -0.595447 0.166599
4 foo two 1.395433 0.047609
5 bar two -0.392670 -0.136473
6 foo one 0.007207 -0.561757
7 foo three 1.928123 -1.623033
模型搭建代码学习
主要根据前面学习的GNN结合LSTM找了一个Demo学模型的搭建。
这里采用GNN-LSTM搭建模型,先进行空间上的卷积,再进行时间上的卷积。
class GAT_LSTM(nn.Module):
def __init__(self, args, graph):
super(GAT_LSTM, self).__init__()
self.args = args
self.out_feats = 128
self.edge_index = graph.edge_index
self.gat = GAT(in_feats=args.seq_len, h_feats=64, out_feats=self.out_feats)
self.lstm = nn.LSTM(input_size=args.input_size, hidden_size=128,
num_layers=args.num_layers, batch_first=True, dropout=0.5)
self.fcs = nn.ModuleList()
self.graph = graph
for k in range(args.input_size):
self.fcs.append(nn.Sequential(
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, args.output_size)
))
def forward(self, data):
x, edge_index, batch = data.x, data.edge_index, data.batch
batch_size = torch.max(batch).item() + 1
x = self.gat(x, edge_index) # 6656 128 = 512 * (13, 128) # y = 6656 1 = 512 * (13 1)
batch_list = batch.cpu().numpy()
# print(batch_list)
# split
xs = [[] for k in range(batch_size)]
ys = [[] for k in range(batch_size)]
for k in range(x.shape[0]):
xs[batch_list[k]].append(x[k, :])
ys[batch_list[k]].append(data.y[k, :])
xs = [torch.stack(x, dim=0) for x in xs]
ys = [torch.stack(x, dim=0) for x in ys]
x = torch.stack(xs, dim=0)
y = torch.stack(ys, dim=0)
x = x.permute(0, 2, 1)
x, _ = self.lstm(x)
x = x[:, -1, :]
preds = []
for fc in self.fcs:
preds.append(fc(x))
pred = torch.stack(preds, dim=0)
return pred, y
这里用到的注意力网络GAT在前面的周报中有学习过。
任意输出一个样本对应的图:
Data(x=[13, 24], edge_index=[2, 40], y=[13, 1])
输出loader中任意一个batch的图数据:
DataBatch(x=[3328, 24], edge_index=[2, 10240], y=[3328, 1], batch=[3328], ptr=[257])
可以看到此时图的特征依然是二维的,但这个图是256个样本对应的小图拼接得到的大图,3328=25613,10240=25640。此时我们可以将256个图拼接到一起送入GAT,大大提高了计算效率。利用GAT得到空间上的卷积结果的维度为(3328, 128),即256个图的输出,然后,我们将该输出进行拆分,以还原成256个输出:
xs = [[] for k in range(batch_size)]
for k in range(x.shape[0]):
xs[batch_list[k]].append(x[k, :])
xs = [torch.stack(x, dim=0) for x in xs]
ys = [torch.stack(x, dim=0) for x in ys]
x = torch.stack(xs, dim=0)
最终x=(batch_size=256, input_size=13, hidden_size=128),即我们对初始输入(batch_size=256, seq_len=24, input_size=13)中256个(13, 24)进行了卷积,得到了256个(13, 128)。
总结
本周的学习内容跟前几周一样,主要是看图神经网络的论文,特别是GNN的有些变体论文,阅读过程中很多地方看不懂,通过百度了解了一部分,但是还是有些难以理解的地方,比如这篇论文里面的核值计算就有很多地方看的很晦涩。其次,这两周学习了模型的搭建,主要还是根据别人的例子仿写,后面还需要加强代码的学习。















 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









