







3.11-3.18
1.阅读ACL文献并记录
2.查找相关资料学习在阿里云部署ChatGLM3-6B
参考:https://blog.csdn.net/H66778899/article/details/135630030
# 运行
streamlit run /mnt/workspace/ChatGLM3/conposite_demo/main.py
可以得到:
3.学习如何微调
首先需对下载的医疗公开数据集进行处理,选择处理的是内科数据集,大概三万多条数据,70%用作训练集,30%用作验证集/测试集.
用作处理的代码如下,使用智普清言写的:
import pandas as pd
import json
# 加载CSV文件
# 1. 读取CSV文件
df = pd.read_csv('internal.csv')
# 2. 数据预处理
# 这里可以根据需要对数据进行清洗和处理
# 例如,去除重复项:
df.drop_duplicates(inplace=True)
# 处理缺失值:
df.fillna(method='ffill', inplace=True)
# 划分数据集
train_size = int(0.7 * len(df))
train_df = df[:train_size]
dev_df = df[train_size:]
# 转换为JSON格式
def to_json_format(df):
data = []
for _, row in df.iterrows():
conversation = [
{"role": "system", "content": "你是一名"+row['department']+"医生"},
{"role": "user", "content": row['title']},
{"role": "assistant", "content": row['answer']}
# ... 根据你的数据结构添加更多回合
]
data.append({"conversations": conversation})
return data
train_data = to_json_format(train_df)
dev_data = to_json_format(dev_df)
# 保存为JSON文件
with open('train.json', 'w', encoding='utf-8') as f:
json.dump(train_data, f, ensure_ascii=False, indent=4)
with open('dev.json', 'w', encoding='utf-8') as f:
json.dump(dev_data, f, ensure_ascii=False, indent=4)
数据集的问答存在的问题为:有些回答包含无意义内容,有些回答的语句不通顺,先作为保留问题,等跑通了再做处理
官方微调文档:https://github.com/THUDM/ChatGLM3/blob/main/finetune_demo/README.md
使用阿里云DSW微调ChatGLM3-6B:https://blog.csdn.net/a131529/article/details/134895649
这个gpu占用率真令人心塞!dream一个奇迹!
微调前:
微调后:
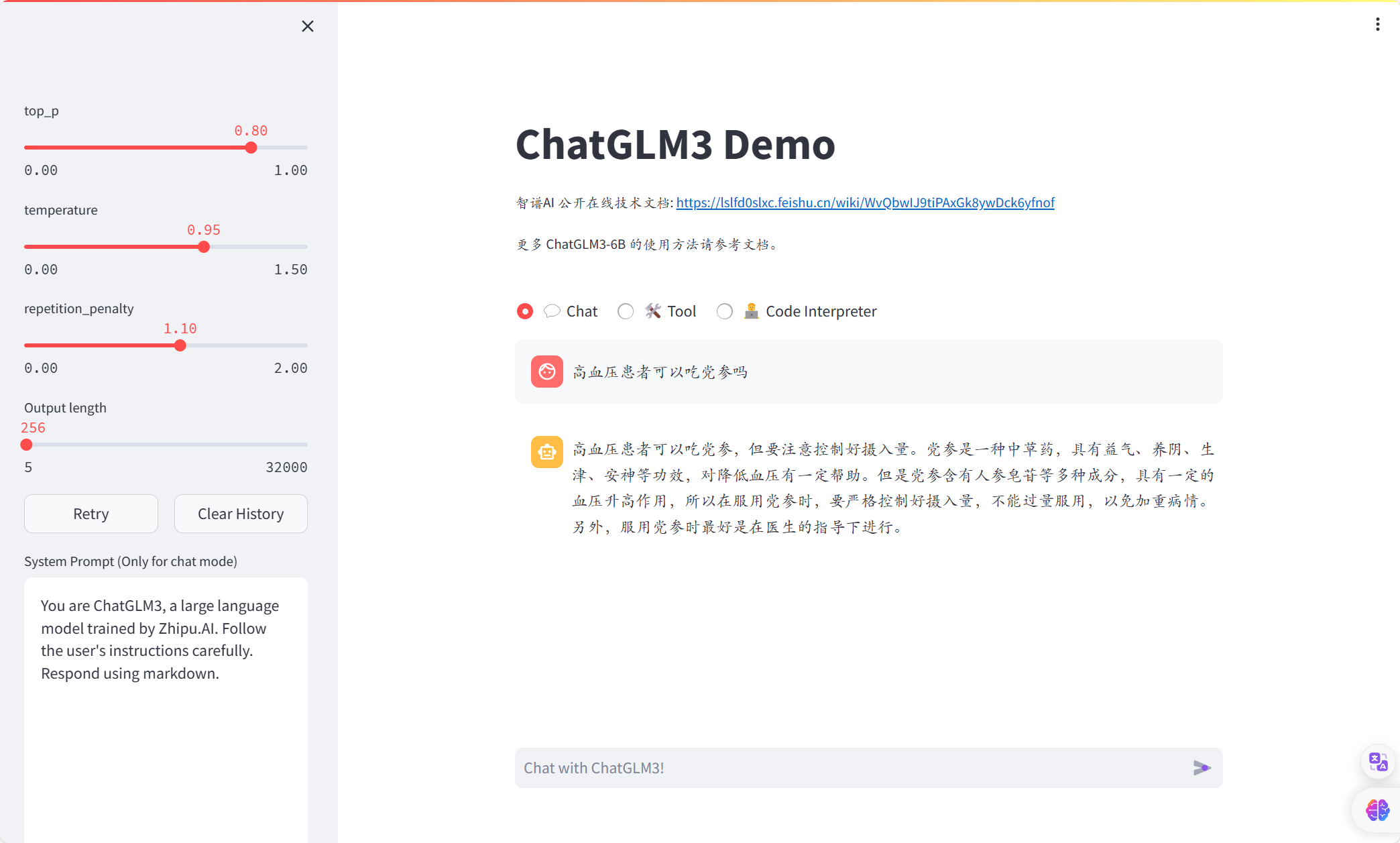
看起来是有那么一点点效果,但是现在的问题是整个过程没有我自己的东西,微调用的人家自带的代码,数据集是公开的,数据处理的代码是AI写的。

3.19-4.1
ok,已经过去了两周,让我们看看这个女人这周做了些什么:
1.微调的问题
微调前是这样回答的:

微调后是这样:
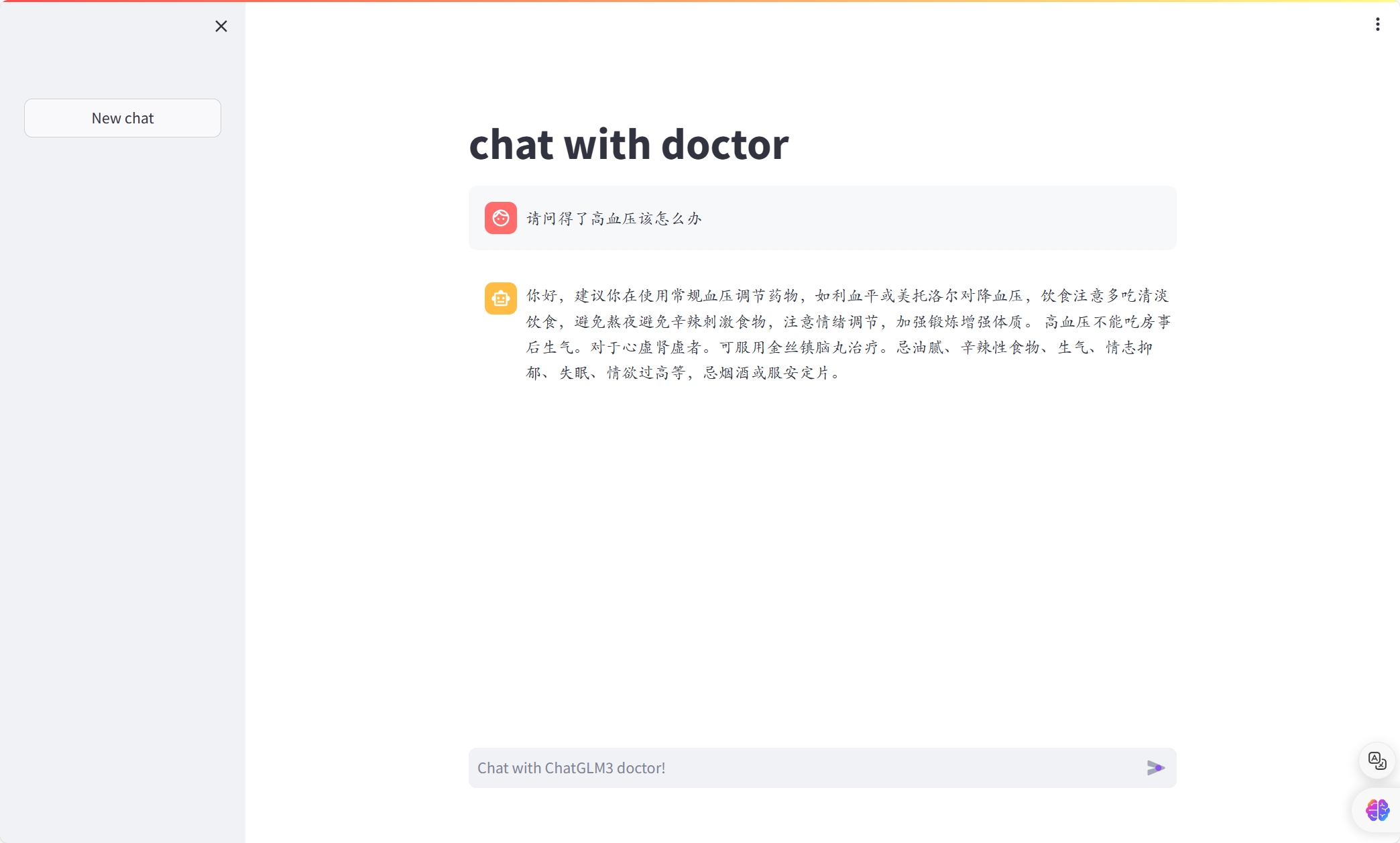
然后过了一段时间再问是这样:
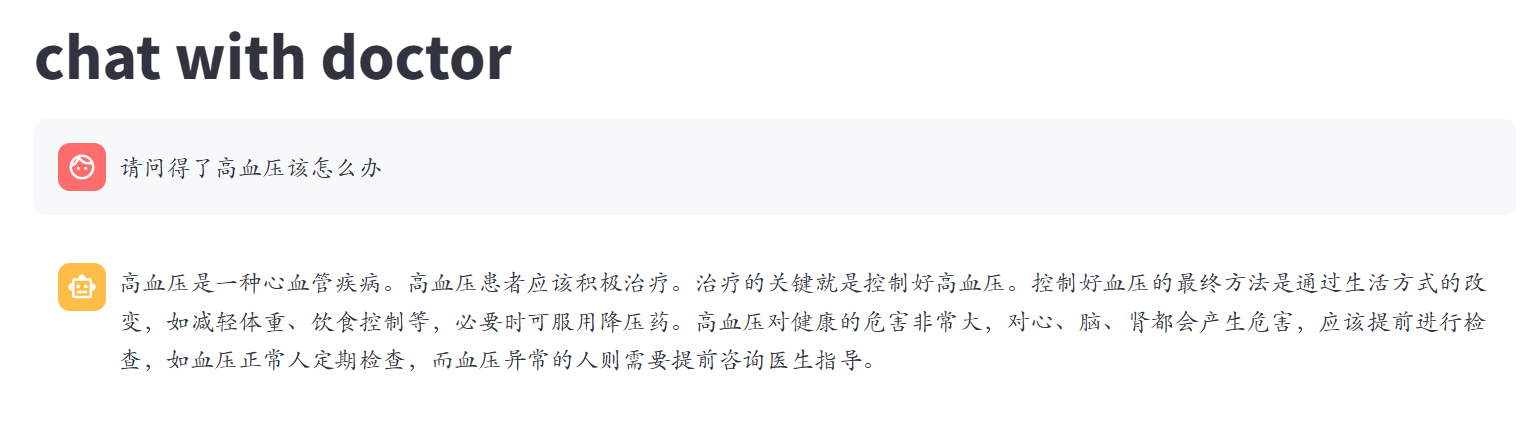
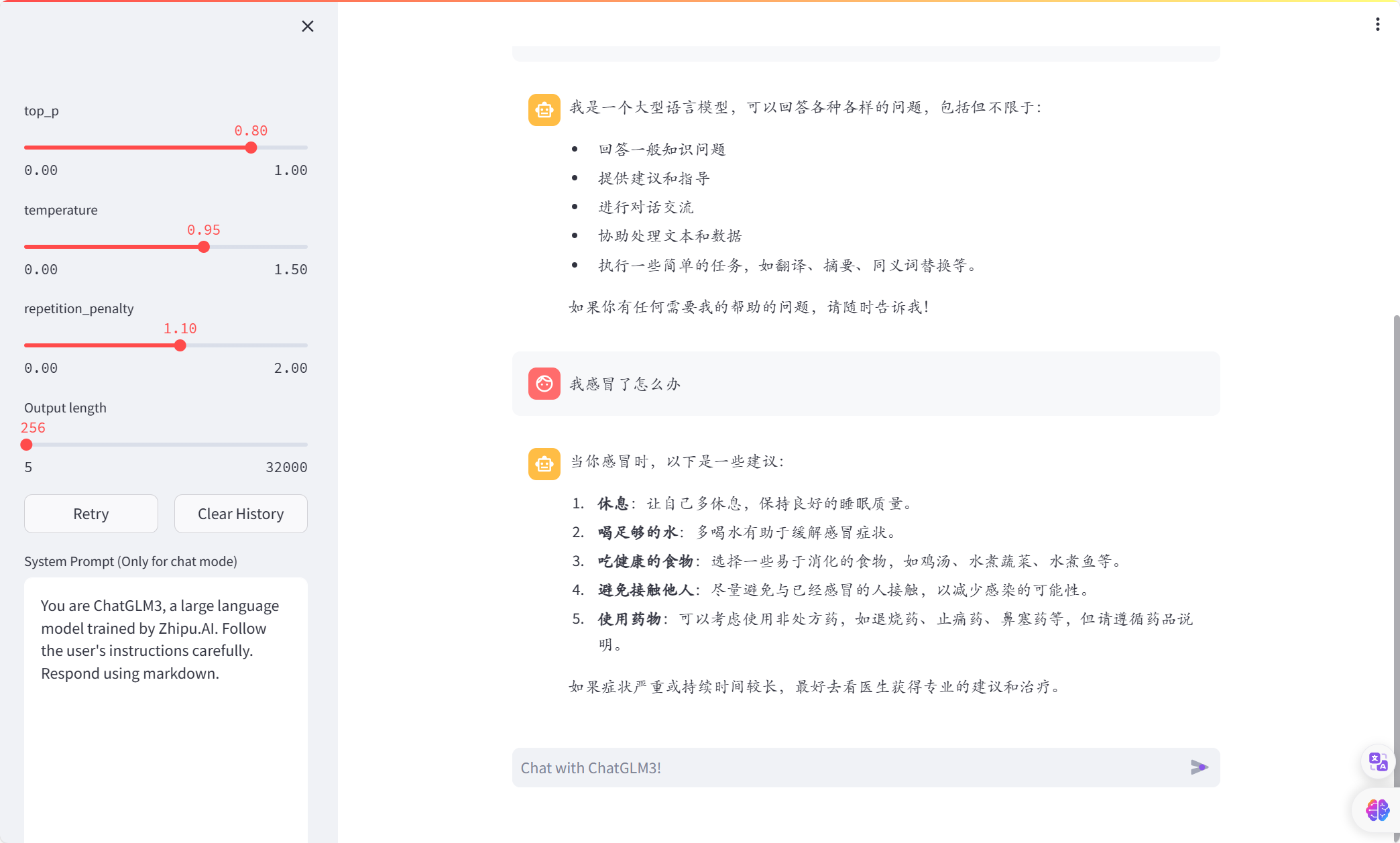
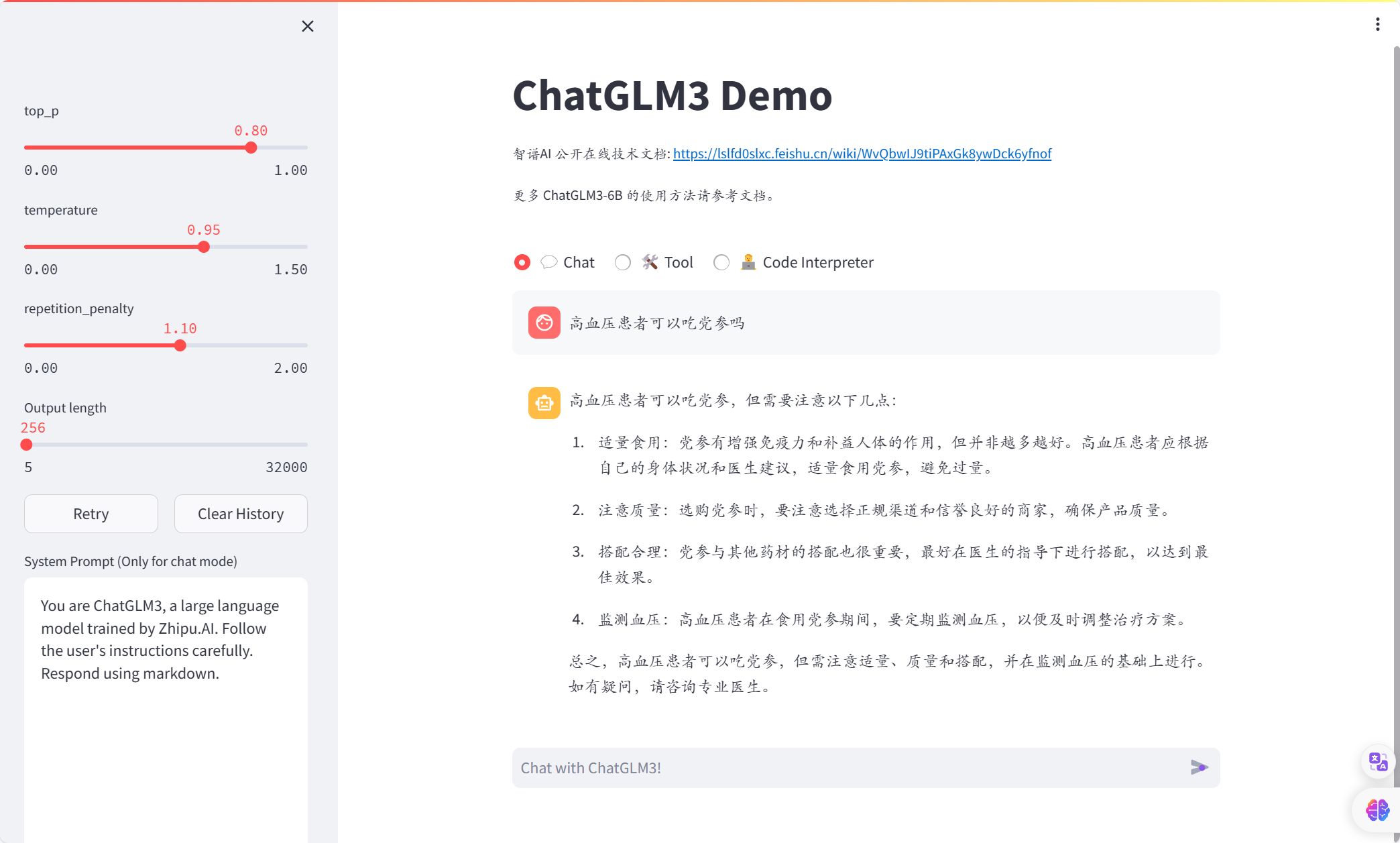
对于感冒问题的回答:
微调前:

微调后:
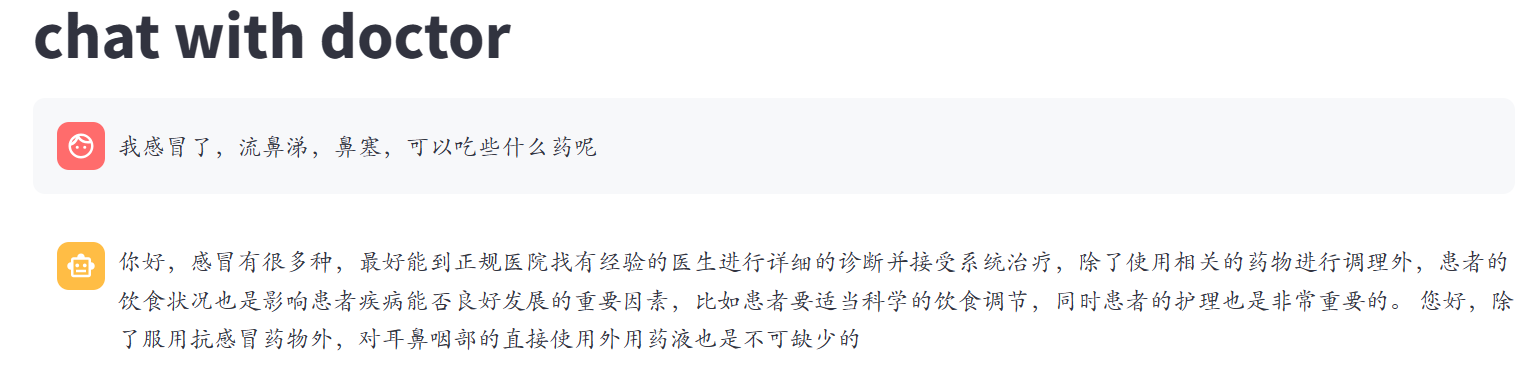
很明显可以看到微调前后,模型回答虽然减少了无意义的内容,回答更加简约,变得专业了一些,但是语言却存在不通顺、胡言乱语的情况,而且,对于训练数据较少的情况,比如上述对待感冒的问题的回答,微调后的模型甚至不如微调前,总而言之,通过微调实现模型在垂直领域的专业回答是不太可行的,用于微调的数据集必须足够的大且覆盖范围较广,并且对数据的质量要求极高,如果数据出现语句不通顺的情况,微调后的模型也极大可能会出现语句不通顺、甚至胡言乱语的状况,此外,使用大规模数据微调模型花费的时间和硬件资源也是巨大的,在本次微调中使用lora微调,数据集仅仅有3万多条数据,但是却花费将近一天时间才完成微调过程,而微调结果却不尽人意。
我期待大模型能够在医疗领域给出专业的回答,不要包含无意义的内容,通过查阅资料,通过外挂知识库或许能够达到预期,实现思路如下:创建医疗知识图谱,将医疗数据存储在neo4j中,使用langchain框架,用户输入问题后,对用户问题进行处理,识别病症等,在知识图谱中检索相关知识,将检索得到的知识与用户问题一起输入到大模型,由大模型生成专业回答输出给用户,以实现在垂直领域的专业回答。
我在langchain_openai_api.py中对代码进行了修改,添加了一个knowledge,将knowledge与user_input一起输入到大模型,可以看到大模型给出的回答确实运用到了knowledge

我在本地电脑部署了neo4j,并且用网上公开数据集创建了一个知识图谱,如下
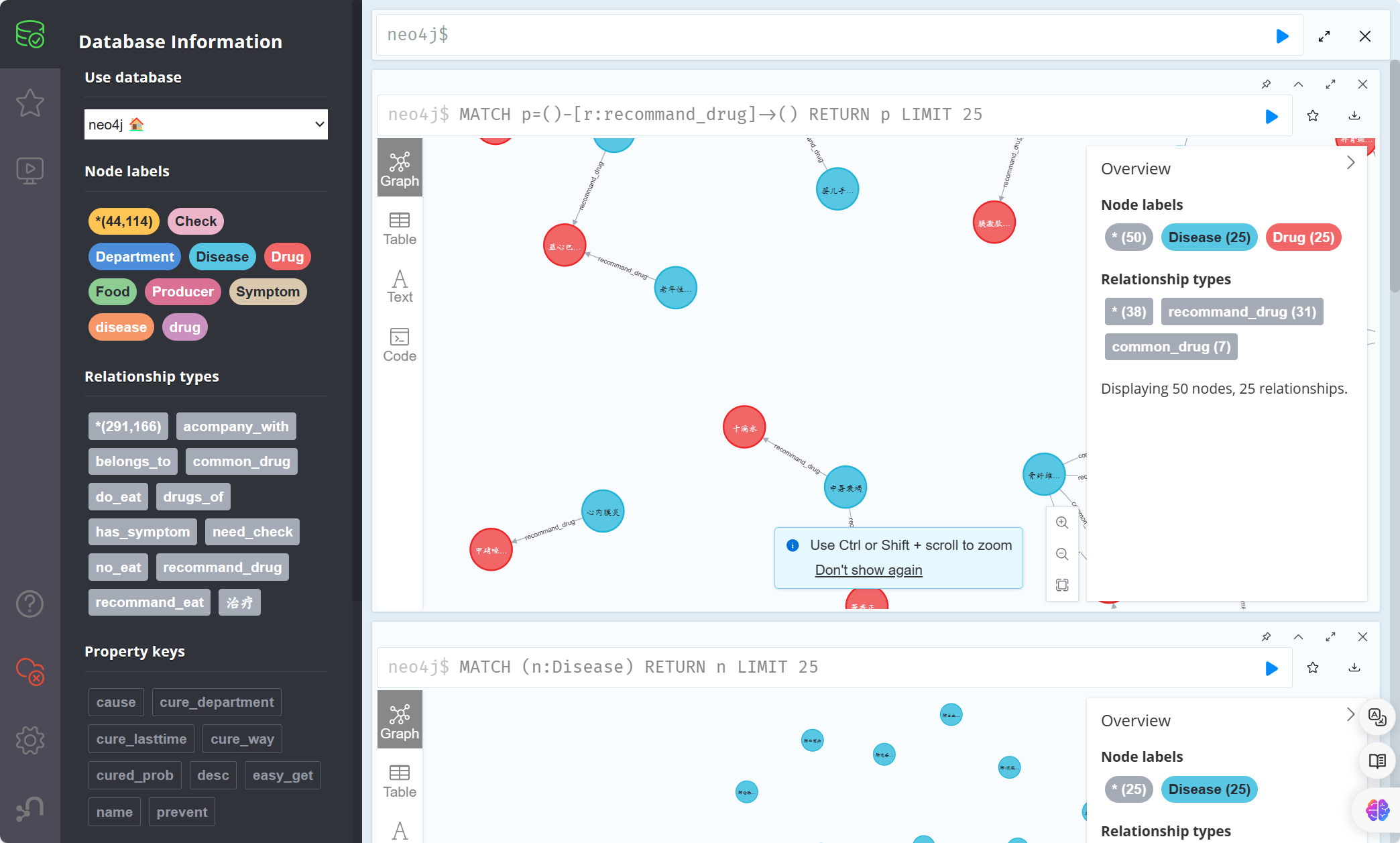
当知识图谱创建成功后,我心中充满了希望,因为这意味着我接下来只需完成 用户输入的处理、知识图谱的检索、将得到知识进行处理后与用户问题一起输送给大模型就ok了!
然而,天不遂人愿!在DSW实例中安装neo4j后,却无法连接,我尝试尽了各种办法,修改neo4j.conf文件、尝试远程连接本地电脑的知识图谱、尝试远程连接dsw的知识图谱,结果通通不行,当我在dsw实例的终端中运行成功了neo4j,然后尝试连接neo4j后,它只会显示

yes, 我不能连接neo4j,无法访问neo4j网页,我尝试在终端中使用命令行修改连接neo4j的初始用户密码,但是它显示拒绝连接,我严重怀疑DSW实例无法联网,绝望!真正的绝望!查遍了网上的解决办法,然而每一个是这样情况的,毕竟谁会闲着没事去dsw实例中部署一个neo4j数据库呢,除了我这个被逼疯了的毕设人!
ok! 既然我本地电脑能访问neo4j,那我就在我本地电脑上部署大模型好了(当初没在本地部署的原因是cuda版本有点低,无意中发现cuda版本可以升级),于是我升级了cuda版本,安装了pytorch,安装了git ,然后开始部署模型,一切还算顺利,成功部署了,也能够运行,进行问答,但是回答生成的速度真的很慢!严重影响效率,然后我试着运行了api_server.py,发现根本运行不了,电脑显存不够,跑不起来,为什么我不自己写一个langchain集成知识图谱的py呢,因为不会,hhhhhh, 发疯 没有参考我真的写不出来,我只能运行api_server.py,然后运行langchain_openai_api.py,在官方现成的代码上做修改,跑起来,在本地运行生成回答太慢,还是决定回到dsw中做,然而,neo4j的问题解决不了,卡在了这里了,现在就是一种想死的状态!明天又要开组会了!
现在还有一个问题是,在dsw中部署的应用和api,外界是无法用的,我再次怀疑这是个单机平台,外界无法用就无法用吧,我现在只期望我能够顺利给大模型外挂上知识库,在这个平台内能用就Ok,不知道明天老师能给我怎样的指导!

4.2-4.7
今天进行了组会汇报,老师是有点魔力在的,她让我找学长问问,然后我就在学长工位的电脑上登了dsw,然后神奇的事情发生了,死活连不上的neo4j,它居然能连上了,ok,回到了宿舍发现还是能连上,只不过不能访问neo4j网页罢了,现在在创建知识图谱了,终于可以进行下一步了,唉,困扰了我那么多天的问题就这么解决了,然后我还不知道它是怎么解决的,感觉可能是因为neo4j.conf的原因,想哭,只希望顺利毕业
毕设取得阶段性进展!
我构造了一个查询知识图谱的函数,在这个函数里,依次调用 问题预处理、问题解析为cypher语句、cypher语句搜索类完成知识图谱的查询,将知识图谱查询结果与用户问题构造成一个prompt一起输入到大模型生成回答,结果如下:

终端打印出了知识图谱查询的结果,我们可以看到模型的确运用到了知识图谱的知识

下一步,我要完成的任务是 数据集质量上的提升,既然模型可以利用知识图谱知识为用户生成专业的问答,那么知识图谱中存储知识的专业性就成了决定模型问答质量的关键性因素
在知识图谱方面,我需要做的是以下几个模块:
1.高质量医疗数据集的收集处理
2.知识图谱的构建,或许可以利用大模型来辅助知识图谱的构建
3.知识图谱的查询:要根据用户输入问题在知识图谱中查询知识,要求对用户问题进行意图识别,需要问题预处理、问题解析为cypher语句,cypher语句查询得到知识三部分,我尝试了使用模型来分析用户意图,生成cypher语句,但是模型的生成并不可靠,几乎难以生成准确、正确的cypher语句,因此生成cypher语句这一部分暂时很难使用模型来辅助
4.7-4.18
爬取了*大夫和**健康网的疾病数据,*大夫:4575条,**健康网:9615条数据
(这些数据仅用于毕设学习)
import requests
from bs4 import BeautifulSoup
from lxml import etree
import pandas as pd
# *大夫爬取代码:
base_url = 'https://www.haodf.com'
headers = {
'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/81.0.4044.129 Safari/537.36",
}
# 要爬取的网页地址
url = 'https://www.haodf.com/citiao/list-jibing.html?from=zhishi'
# 发送请求获取网页内容
response = requests.get(url, headers=headers)
html_content = response.text
# 解析HTML内容
tree = etree.HTML(html_content)
# 获取所有大类科室的链接和名字
Depart_urls = tree.xpath('//div[@class="kstl"]/a/@href')
Depart_names = tree.xpath('//div[@class="kstl"]/a/text()')
# 创建一个空的DataFrame来存储所有疾病信息
all_diseases = pd.DataFrame(
columns=['科室', '疾病名称', '疾病介绍', '发病原因', '症状', '如何预防', '检查', '治疗方式', '营养与饮食',
'注意事项', '预后'])
# 遍历所有大类科室的链接
for i, (department_name, department_url) in enumerate(zip(Depart_names, Depart_urls)):
department_response = requests.get(base_url + department_url, headers=headers)
department_html_content = department_response.text
depart_tree = etree.HTML(department_html_content)
# 获取所有子类科室的链接
departments_url = depart_tree.xpath('//div[@class="ksbd"]/ul/li/a/@href')
for depart_url in departments_url:
departments_response = requests.get(base_url + depart_url, headers=headers)
content = departments_response.text
departs_tree = etree.HTML(content)
# 获取当前科室下的疾病名称和链接
disease_names = departs_tree.xpath('//div[@class="m_ctt_green"]/ul/li/a/text()')
disease_urls = departs_tree.xpath('//div[@class="m_ctt_green"]/ul/li/a/@href')
for i, (name, url) in enumerate(zip(disease_names, disease_urls)):
# 发送请求到达每个疾病详情页
disease_response = requests.get(base_url + url, headers=headers)
disease_html_content = disease_response.text
disease_tree = etree.HTML(disease_html_content)
# 获取介绍页的URL
tab_items = disease_tree.xpath('//section[@class="tab"]/a[@class="tab-item"]/@href')
introduction_url = [item for item in tab_items if "jieshao.html" in item][0]
intro_response = requests.get(introduction_url, headers=headers)
intro_content = intro_response.text
# intro_tree = etree.HTML(intro_content)
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(intro_content, 'html.parser')
# 提取每个疾病的详细信息
disease_info = {'科室': department_name, '疾病名称': name}
# 提取“介绍”部分的内容
desc_div = soup.find('div', {'data-key': '介绍'})
if desc_div:
desc = desc_div.find('div', class_='l-c-text').get_text()
if desc:
disease_info['疾病介绍'] = desc
# 提取“发病原因”部分的内容
cause_div = soup.find('div', {'data-key': '发病原因'})
if cause_div:
cause = cause_div.find('div', class_='l-c-text').get_text()
if cause:
disease_info['发病原因'] = cause
# 提取“症状表现”部分的内容
symptoms_div = soup.find('div', {'data-key': '症状表现'})
if symptoms_div:
symptom = symptoms_div.find('div', class_='l-c-text').get_text()
if symptom:
disease_info['症状'] = symptom
# 提取如何预防
prevention_div = soup.find('div', {'data-key': '如何预防'})
if prevention_div:
prevention = prevention_div.find('div', class_='l-c-text').get_text()
if prevention:
disease_info['如何预防'] = prevention
# 提取 检查
check_div = soup.find('div', {'data-key': '检查'})
if check_div:
check = check_div.find('div', class_='l-c-text').get_text()
if check:
disease_info['检查'] = check
# 提取治疗方式
treatment_div = soup.find('div', {'data-key': '治疗方式'})
if treatment_div:
treatment = treatment_div.find('div', class_='l-c-text').get_text()
if treatment:
disease_info['治疗方式'] = treatment
# 提取营养与饮食
food_div = soup.find('div', {'data-key': '营养与饮食'})
if food_div:
food = food_div.find('div', class_='l-c-text').get_text()
if food:
disease_info['营养与饮食'] = food
# 提取注意事项
precautions_div = soup.find('div', {'data-key': '注意事项'})
if precautions_div:
precaution = precautions_div.find('div', class_='l-c-text').get_text()
if precaution:
disease_info['注意事项'] = precaution
# 提取 预后
prognosis_div = soup.find('div', {'data-key': '预后'})
if prognosis_div:
prognosis = prognosis_div.find('div', class_='l-c-text').get_text()
if prognosis:
disease_info['预后'] = prognosis
# 将当前疾病的详细信息添加到DataFrame中
all_diseases = pd.concat([all_diseases, pd.DataFrame([disease_info])], ignore_index=True)
# 保存到Excel文件
excel_file = 'diseases.xlsx'
all_diseases.to_excel(excel_file, index=False)
# 输出数据总量
total_diseases = len(all_diseases)
print(f"总共爬取到 {total_diseases} 种疾病信息,并已保存到 {excel_file} 文件中。")
import requests
from bs4 import BeautifulSoup
from lxml import etree
import pandas as pd
#**健康网爬取代码
base_url = 'https://jbk.39.net'
headers = {
'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/81.0.4044.129 Safari/537.36",
}
# 要爬取的网页地址
url = 'https://jbk.39.net/bw/'
# 发送请求获取网页内容
response = requests.get(url, headers=headers)
html_content = response.text
# 解析HTML内容
tree = etree.HTML(html_content)
# 获取所有大类科室的链接和名字
Depart_urls = tree.xpath('//div[@class="lookup_department lookup_cur"]/div/ul/li/a/@href')
Depart_names = tree.xpath('//div[@class="lookup_department lookup_cur"]/div/ul/li/a/text()')
# 创建一个空的DataFrame来存储所有疾病信息
all_diseases = pd.DataFrame(
columns=['科室', '疾病名称', '疾病介绍', '是否医保', '传染性', '治疗方式', '治愈率', '多发人群', '症状', '检查',
'并发症', '药物', '宜吃食物', '忌吃食物'])
# 遍历所有大类科室的链接
for i, (department_name, department_url) in enumerate(zip(Depart_names[1:], Depart_urls[1:])):
department_response = requests.get(base_url + department_url, headers=headers)
department_html_content = department_response.text
depart_tree = etree.HTML(department_html_content)
# 获取每个科室下疾病模块的链接
departments_url = depart_tree.xpath('//div[@class="disease_box"]/ul/li[2]/a/@href')
for depart_url in departments_url:
departments_response = requests.get(base_url + depart_url, headers=headers)
content = departments_response.text
departs_tree = etree.HTML(content)
# 获取分页信息
pagination = departs_tree.xpath('//ul[@class="result_item_dots"]/li/span[position() = last() - 1]/a/text()')
if pagination:
last_page_number = int(pagination[0])
else:
last_page_number = 0
depart_url = depart_url.replace('_t1/', '_t1_p1/')
# 遍历每一页
for page_number in range(1, last_page_number + 1):
page_url = depart_url.replace('_p1/', f'_p{page_number}/')
print(base_url + page_url)
page_response = requests.get(base_url + page_url, headers=headers)
content = page_response.text
page_tree = etree.HTML(content)
# 获取疾病名称和链接
disease_names = page_tree.xpath('//p[@class="result_item_top_l"]/a/text()')
disease_urls = page_tree.xpath('//p[@class="result_item_top_l"]/a/@href')
for i, (name, url) in enumerate(zip(disease_names, disease_urls)):
# 发送请求到达每个疾病详情页
disease_response = requests.get(url, headers=headers)
disease_html_content = disease_response.text
soup = BeautifulSoup(disease_html_content, 'html.parser')
# 提取每个疾病的详细信息
disease_info = {'科室': department_name, '疾病名称': name}
# 疾病介绍
desc = soup.find('p', class_='information_l').get_text()
disease_info['疾病介绍'] = desc
# 提取是否医保
medicare_li = soup.find('i', string=lambda text: text and '是否医保' in text)
is_medicare = medicare_li.next_sibling.next_sibling.get_text() if medicare_li else ""
disease_info['是否医保'] = is_medicare
# 提取传染性
contagiousness_li = soup.find('i', string=lambda text: text and '传染性' in text)
contagiousness = contagiousness_li.next_sibling.get_text() if contagiousness_li else ""
disease_info['传染性'] = contagiousness
# 提取治疗方法
treatment_methods_li = soup.find('i', string=lambda text: text and '治疗方法' in text)
treatment_methods = treatment_methods_li.next_sibling.get_text() if treatment_methods_li else None
disease_info['治疗方式'] = treatment_methods
# 提取治愈率
cure_rate_li = soup.find('i', string=lambda text: text and '治愈率' in text)
cure_rate = cure_rate_li.next_sibling.get_text() if cure_rate_li else ""
disease_info['治愈率'] = cure_rate
# 提取多发人群
high_risk_group_li = soup.find('i', string=lambda text: text and '多发人群' in text)
high_risk_group = high_risk_group_li.next_sibling.get_text() if high_risk_group_li else ""
disease_info['多发人群'] = high_risk_group
# 提取典型症状
typical_symptoms_li = soup.find('i', string=lambda text: text and '典型症状' in text)
typical_symptoms = typical_symptoms_li.next_sibling.next_sibling.get_text() if typical_symptoms_li else None
disease_info['症状'] = typical_symptoms
# 提取临床检查
clinical_examination_li = soup.find('i', string=lambda text: text and '临床检查' in text)
clinical_examination = clinical_examination_li.next_sibling.next_sibling.get_text() if clinical_examination_li else ""
disease_info['检查'] = clinical_examination
# 提取并发症
complications_li = soup.find('i', string=lambda text: text and '并发症' in text)
complications = complications_li.next_sibling.next_sibling.get_text() if complications_li else None
disease_info['并发症'] = complications
# 提取常用药品
common_medicines_li = soup.find('i', string=lambda text: text and '常用药品' in text)
common_medicines = common_medicines_li.next_sibling.next_sibling.get_text() if common_medicines_li else ""
disease_info['药物'] = common_medicines
# 获取饮食链接
navigation_a_tag = soup.find('a', string='饮食')
if navigation_a_tag:
diet_link = navigation_a_tag['href']
print(diet_link)
# 到达饮食页面
diet_response = requests.get(diet_link, headers=headers)
diet_html_content = diet_response.text
soup = BeautifulSoup(diet_html_content, 'html.parser')
yichifood_names = ""
jichifood_names = ""
if len(soup.find_all('table')) == 2:
# 提取宜吃食物名称
yichifood_trs = soup.find_all('table')[0].find_all('tr')[1:] # 跳过标题行
yichifood_names = [tr.find_all('td')[0].get_text().strip() for tr in yichifood_trs]
# 提取忌吃食物名称
jichifood_trs = soup.find_all('table')[1].find_all('tr')[1:] # 跳过标题行
jichifood_names = [tr.find_all('td')[0].get_text().strip() for tr in jichifood_trs]
# 将宜吃和忌吃食物信息添加到疾病信息中
disease_info['宜吃食物'] = yichifood_names
disease_info['忌吃食物'] = jichifood_names
# 将当前疾病的详细信息添加到DataFrame中
all_diseases = pd.concat([all_diseases, pd.DataFrame([disease_info])], ignore_index=True)
# 保存到Excel文件
excel_file = 'diseases_39.xlsx'
all_diseases.to_excel(excel_file, index=False)
# 输出数据总量
total_diseases = len(all_diseases)
print(f"总共爬取到 {total_diseases} 种疾病信息,并已保存到 {excel_file} 文件中。")
接下来需对爬取到的数据进行整理,构建知识图谱,另外,这两周新增了上传文件作为外接知识库,需考虑构建知识图谱或仿照langchain-chatchat项目

6.3下午
毕设彻底over 感觉做了一坨

写的也是一坨

但最后成绩是 优 hhhhhhhh
附上致谢



















 1065
1065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











