







1.查看读入数据的基本情况
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
print(order.info())
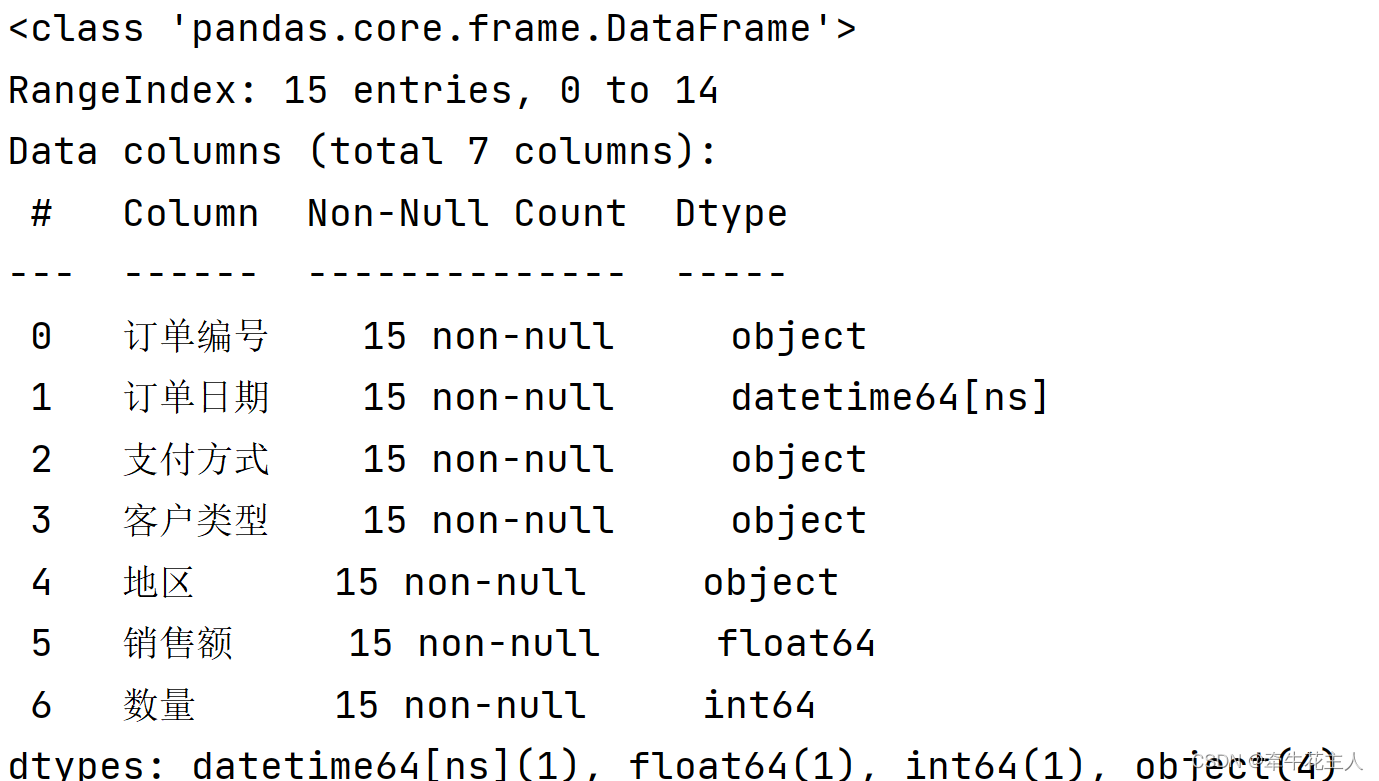
2. 预览数据
当数据量较大时,无法展示所有数据,可以适用head(n)、tail(n)方法查看数据前n行,后n行数据,n值默认为5,该方法对DataFrame和Series都适用。
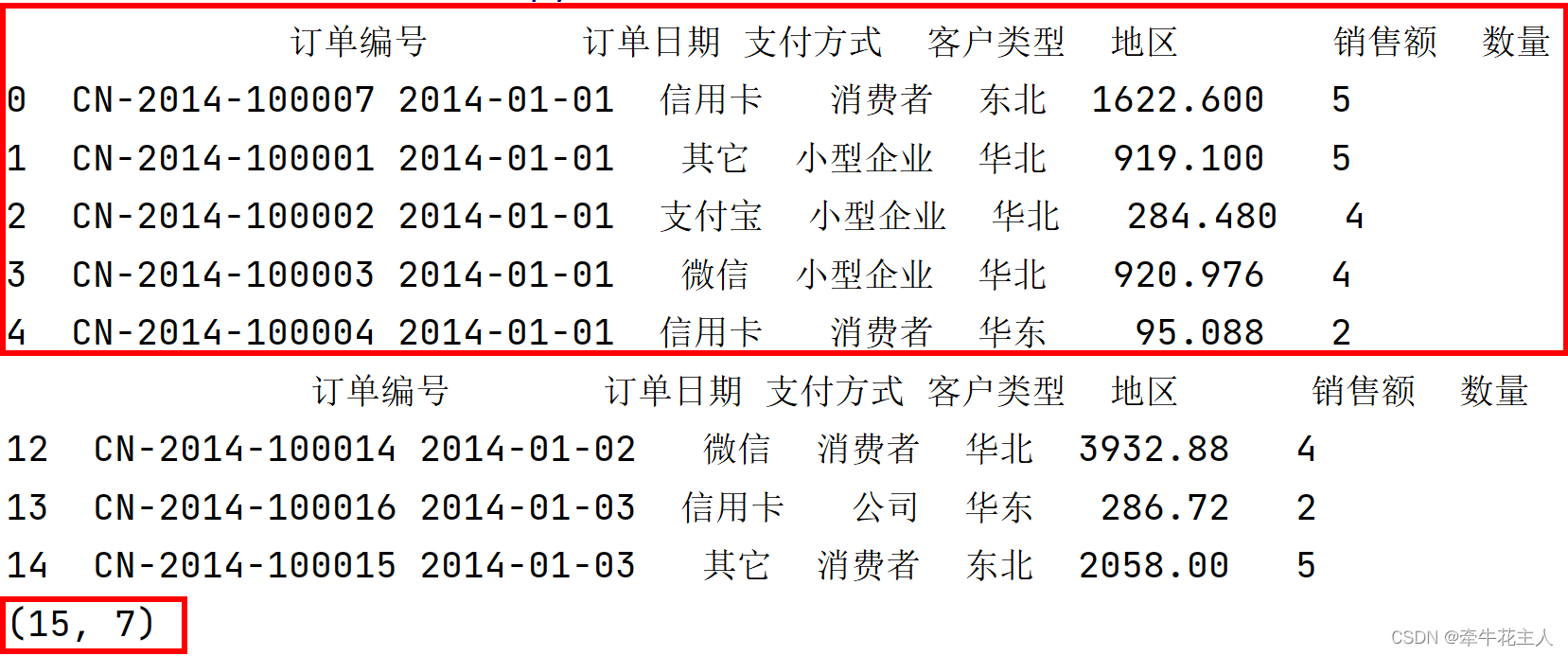
print(order.head())
print(order.tail(3))
print(order.shape)
3. 数据类型转换
3.1 转换单个数据类型
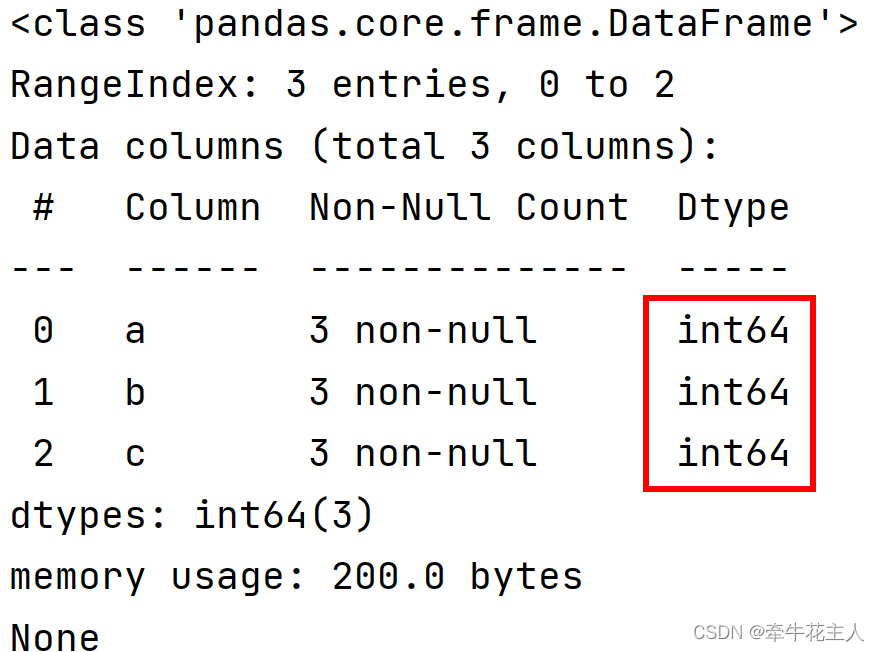
dft = pd.DataFrame({"a": [1, 2, 3], "b": [4, 5, 6], "c": [7, 8, 9]})
print(dft.info())
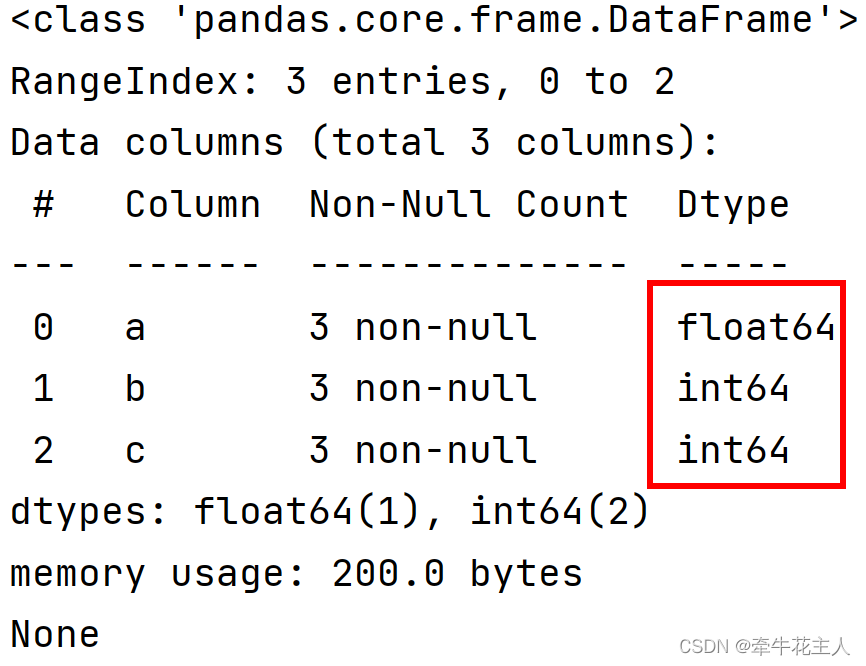
dft['a'] = dft['a'].astype('float64')
print(dft.info())
3.2 同时转换多个列数据类型:使用字典
dft = dft.astype({'a':'float64','c':'object'})
print(dft.info())
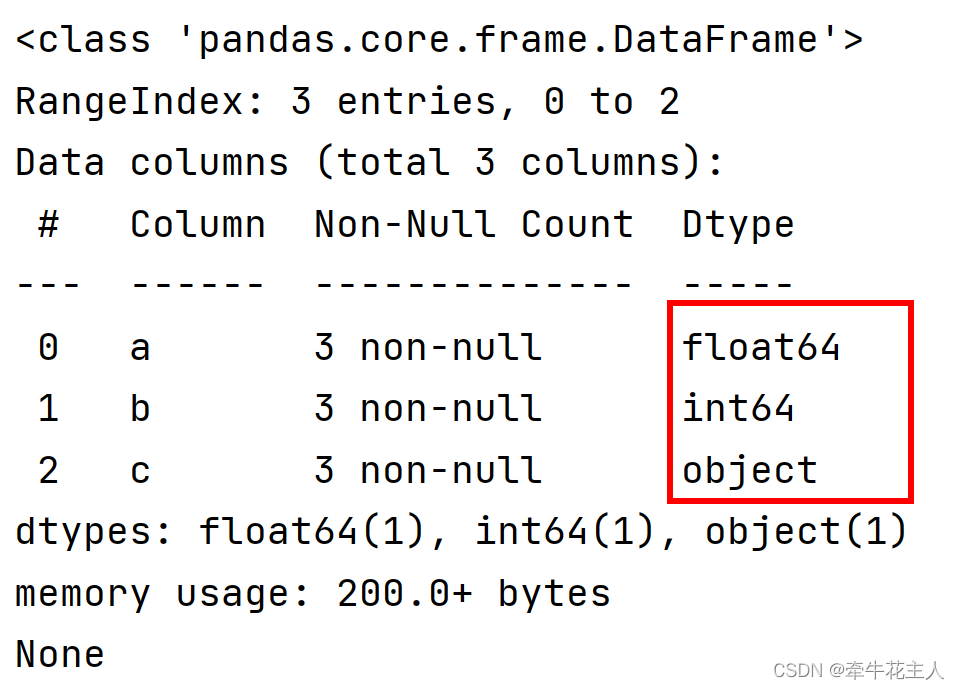
可以统一起来,均使用字典进行数据类型的转变
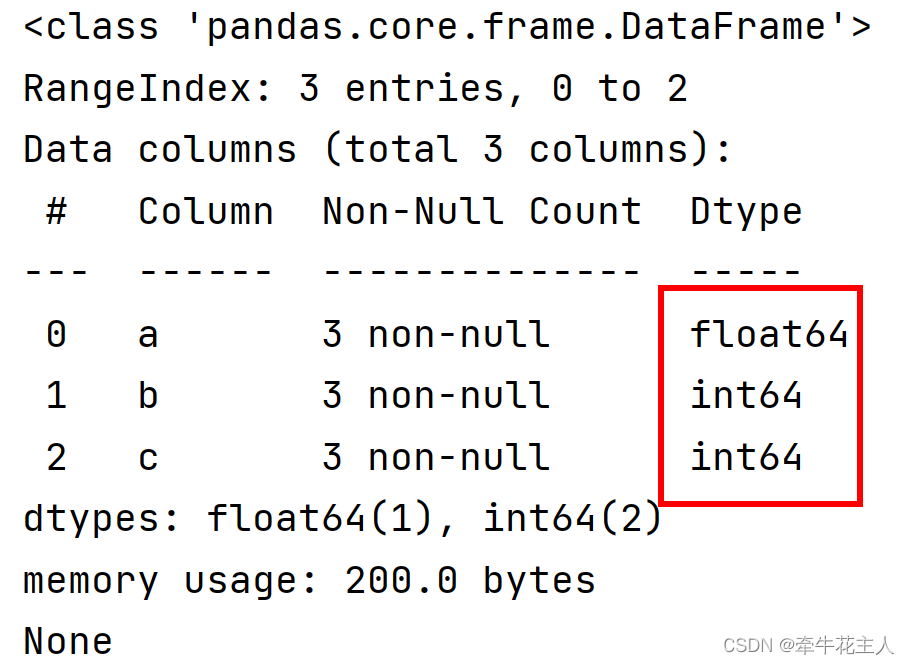
dft = dft.astype({'a' : 'float64'})
print(dft.info())
4. 简要描述性统计函数
df = pd.DataFrame(
{"one": pd.Series(np.random.randn(3), index=["a", "b", "c"]),
"two": pd.Series(np.random.randn(4), index=["a", "b", "c", "d"]),
"three": pd.Series(np.random.randn(3), index=["b", "c", "d"]),
})
# print(df)
print(df.describe())
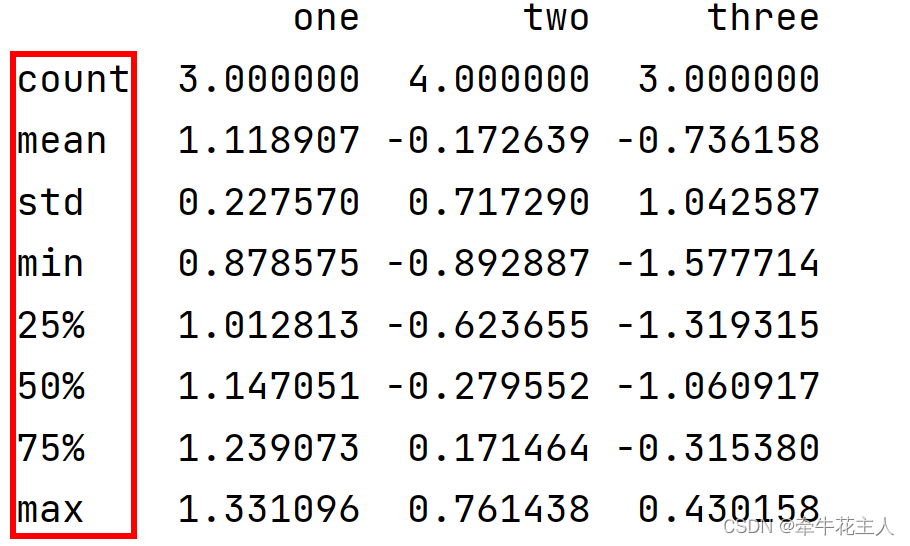
注意:count()方法的计数,统计的是非空数值的个数
5. DataFrame常用属性总结
以下DatFrame简写为df
| 属性 | 含义 |
|---|---|
| df.index | 获取df的行索引 |
| df.colums | 获取df的列名 |
| df.dtypes | 获取df每列的数据类型,返回值为Series,返回的Series索引为原df的列名 |
| df.info() | 获取df的简要摘要:非空值的数量、数据类型 |
| df.values | 获取df中的值,行列标签会被去除,推荐使用df.to_numpy方法 |
| df.axes | 获取行标签、列名信息,返回值为行索引和 |
| df.ndim | 获取df的维度值 |
| df.size | 获取df的元素总量 |
| df.shape | 获取df的形状,值为元组(m,n) |
| df.empty | 鉴定df是否为空 |
print('1. order.index: \n',order.index)
print('2. order.columns:\n',order.columns)
print('3. order.dtypes:\n',order.dtypes)
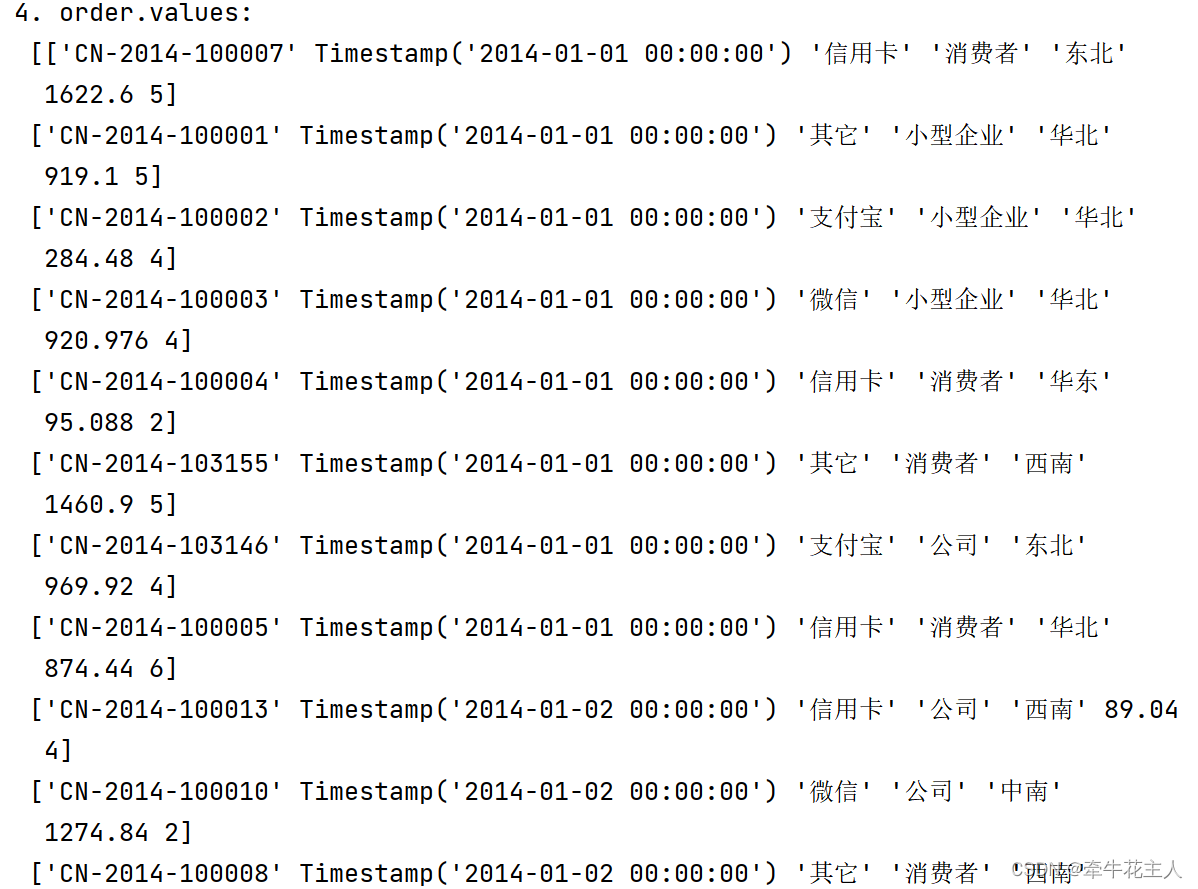
print('4. order.values:\n',order.values)
print('5. order.axes:\n',order.axes)
print('6. order.ndim:',order.ndim)
print('7. order.size:',order.size)
print('8. order.shape:',order.shape)
print('9. order.empty:',order.empty)


6. 索引与迭代
| 参数 | 含义 |
|---|---|
| df.head(n=5) | 获取df的前n行,n的默认为值5,当n取负值:获取除最后n行外的其他行,相当于df[:n] |
| df.loc | 返回给定标签的行、列值,主要以标签为主 |
| df.iloc | 返回给定整数索引的行、列值,以整数索引为主 |
| df.insert() | 指定位置插入列 |
| df.items | 返回列名和列中内容组成的Series |
| df.keys() | 获取df的列名 |
| df.pop(item) | 从df中删除列item,返回的是要删除的Series:item |
| df.tali(n=5) | 获取最后n行的值,默认n=5 |
6.1 df.loc[]
6.1.1 指定行
通过标签或者布尔型数组返回df指定的行和列
df.loc[]中可以接收的常用输入有:
1. 单个标签,如:‘a'或5,需要注意此处的5是作为索引标签出现,而不是数字5
2. 标签数组或列表,如:['a','b','c']
3. 标签切片,需要注意与Python切片不同,.loc中此处的切片同时包含开始值和结束值。
4. 与df索引Index长度相同的布尔型数组
5. 布尔型Series
6. 条件表达式
df = pd.DataFrame({'a': np.arange(0, 10, 2),
'b': np.random.randint(90, 100, 5),
'c': np.random.rand(5)}, index=list('stpkg'))
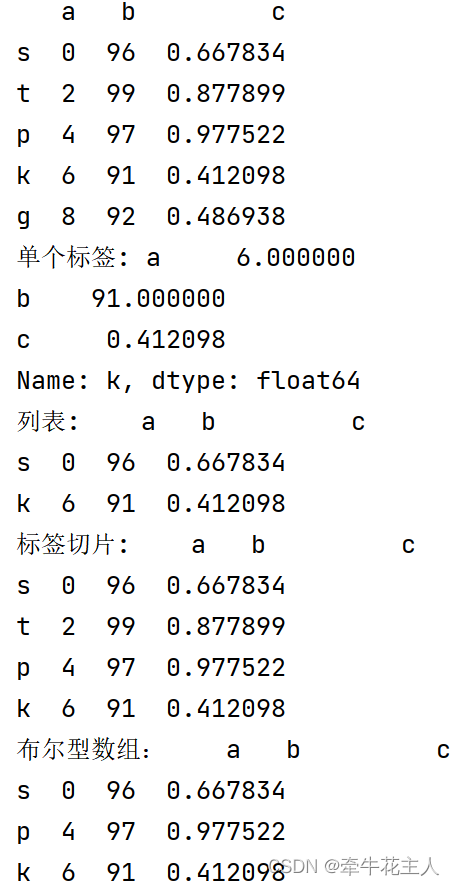
print(df)
print('单个标签:', df.loc['k'])
print('列表:', df.loc[['s', 'k']])
print('标签切片:', df.loc['s':'k'])
print('布尔型数组:', df.loc[[True, False, True, True, False]])
输入函数
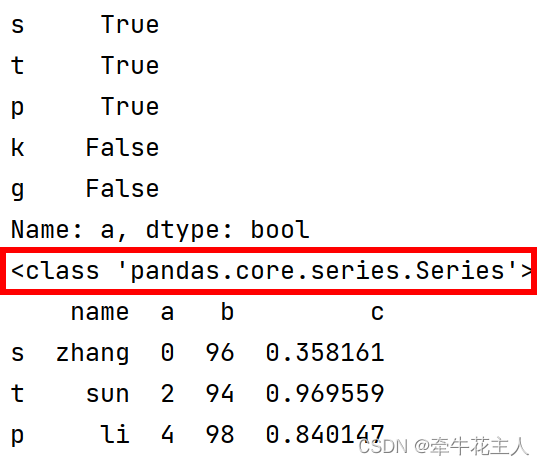
print(df['a'] < 5)
print(type(df['a'] < 5))
print(df.loc[df['a'] < 5])
6.1.2 指定行和列
df = pd.DataFrame({'a': np.arange(0, 10, 2),
'b': np.random.randint(90, 100, 5),
'c': np.random.rand(5)}, index=list('stpkg'))
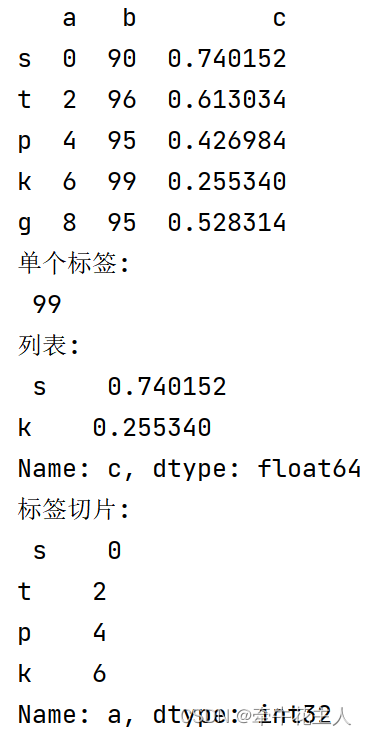
print(df)
print('单个标签:\n', df.loc['k','b'])
print('列表:\n', df.loc[['s', 'k'],'c'])
print('标签切片:\n', df.loc['s':'k','a'])
6.1.3 修改df指定位置的值
df = pd.DataFrame({'a': np.arange(0, 10, 2),
'b': np.random.randint(90, 100, 5),
'c': np.random.rand(5)}, index=list('stpkg'))
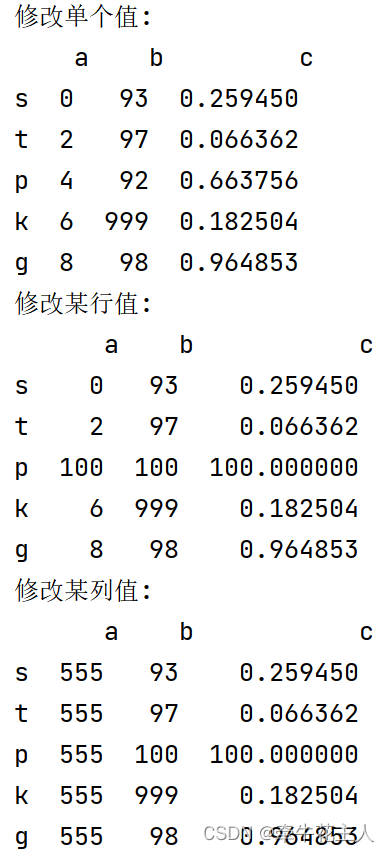
print(df)
df.loc['k','b']=999
print('修改单个值:\n', df)
df.loc[['p']]=100
print('修改某行值:\n', df)
df.loc[:,'a']=555
print('修改某列值:\n', df)
6.2 df.iloc[]
6.2.1 指定行
主要基于位置进行索引,也可传入布尔值索引
允许的输入有:
1.整数,如:5
2.整数组成的数组或者列表
3.整数的切片
4.布尔值数组
5.函数
6.行,列组成的元组
df = pd.DataFrame({'a': np.arange(0, 10, 2),
'b': np.random.randint(90, 100, 5),
'c': np.random.rand(5)}, index=list('stpkg')
)
print(df)
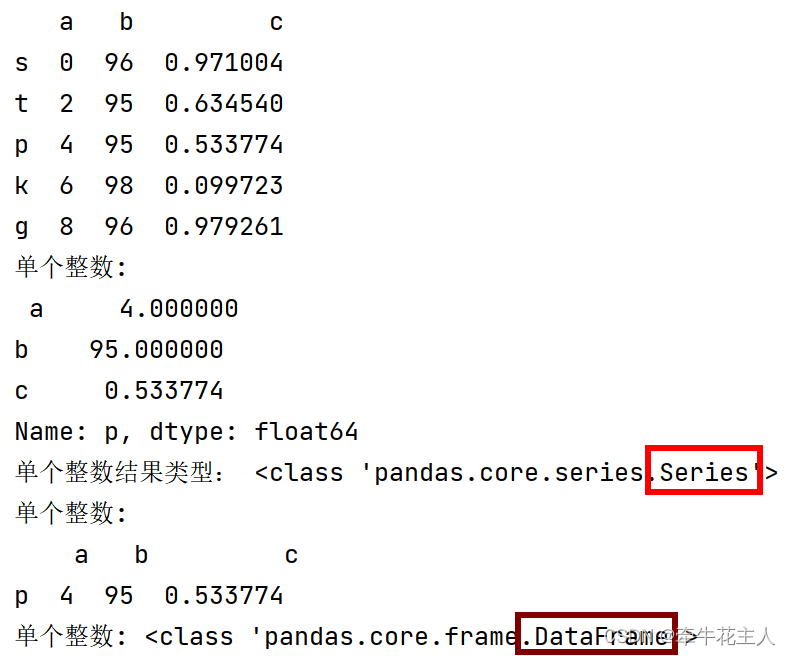
print('单个整数:\n', df.iloc[2])
print('单个整数结果类型:', type(df.iloc[2]))
print('单个整数:\n', df.iloc[[2]])
print('单个整数:', type(df.iloc[[2]]))
print('切片:\n', df.iloc[:2])
print('列表:\n', df.iloc[[1, 3]])
print('布尔型:\n', df.iloc[[True, False, True, True, False]])
6.2.2 指定行和列
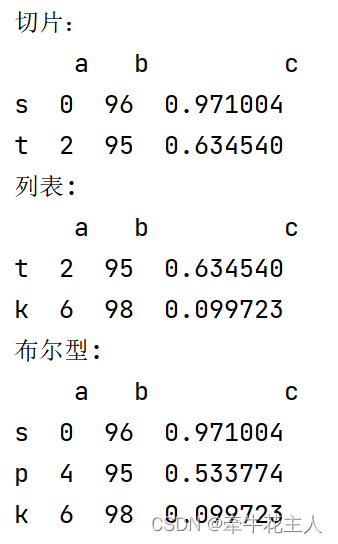
print('单个整数:\n', df.iloc[2,1])
print('单个整数结果类型:', type(df.iloc[2,1]))
print('单个整数:\n', df.iloc[[2,1]])
print('单个整数:', type(df.iloc[[2,1]]))
print('切片:\n', df.iloc[:2,2])
print('列表:\n', df.iloc[[1, 3],[1,2]])
print('布尔型:\n', df.iloc[[True, False, True, True, False],[True, False, True]])

6.3 df.insert()
在DataFrame中的指定位置插入列
6.3.1 函数语法
DataFrame.insert(loc, column, value, allow_duplicates=_NoDefault.no_default)
6.3.2 函数参数
| 参数 | 含义 |
|---|---|
| loc | 整数,插入列的位置 |
| column | 字符串,整数或者其他可哈希对象 |
| value | 插入的列值,可以是标量,Series,或者类数组 |
| allow_duplicates | 布尔值,可选参数,是否允许列名重复,默认取值为False:不允许 |
df = pd.DataFrame({'a': np.arange(0, 10, 2),
'b': np.random.randint(90, 100, 5),
'c': np.random.rand(5)}, index=list('stpkg')
)
print(df)
df.insert(0, 'name', ['zhang', 'sun', 'li', 'qiao', 'kang'])
print(df)
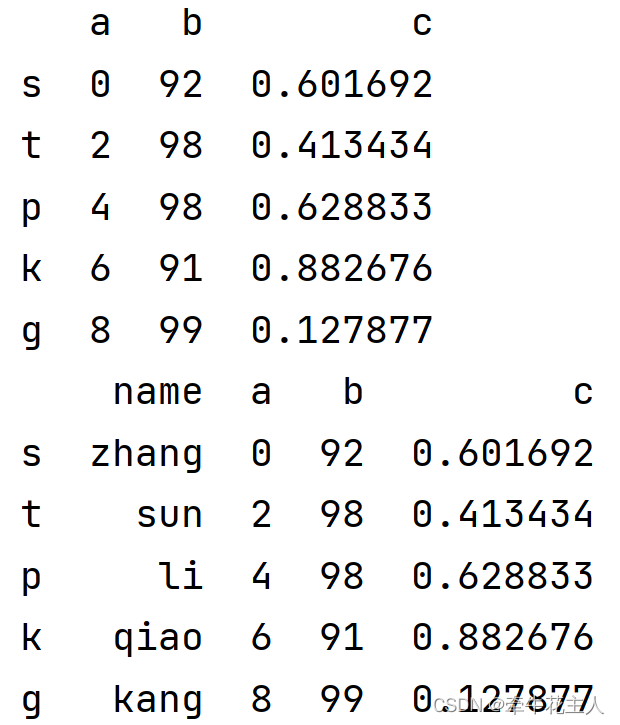
当设置allow_duplicates值为True时,列名允许重复
6.4 插入列,删除列
# df.items()
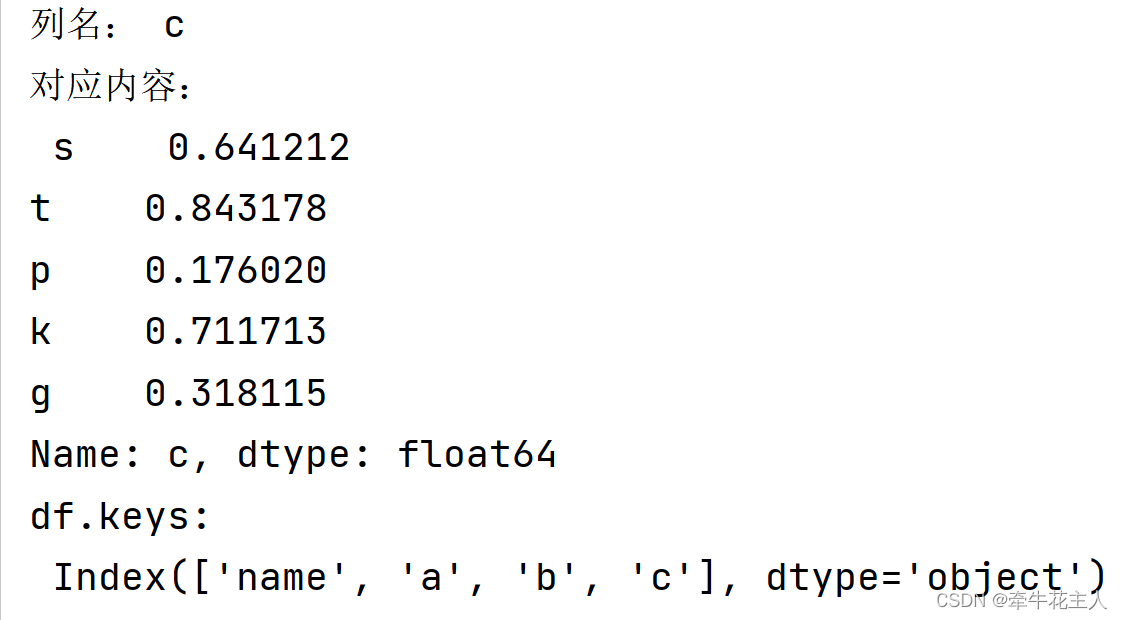
for col, cont in df.items():
print('列名:', col)
print('对应内容:\n', cont)
# df.keys()
print('df.keys: \n',df.keys())
# df.pop()
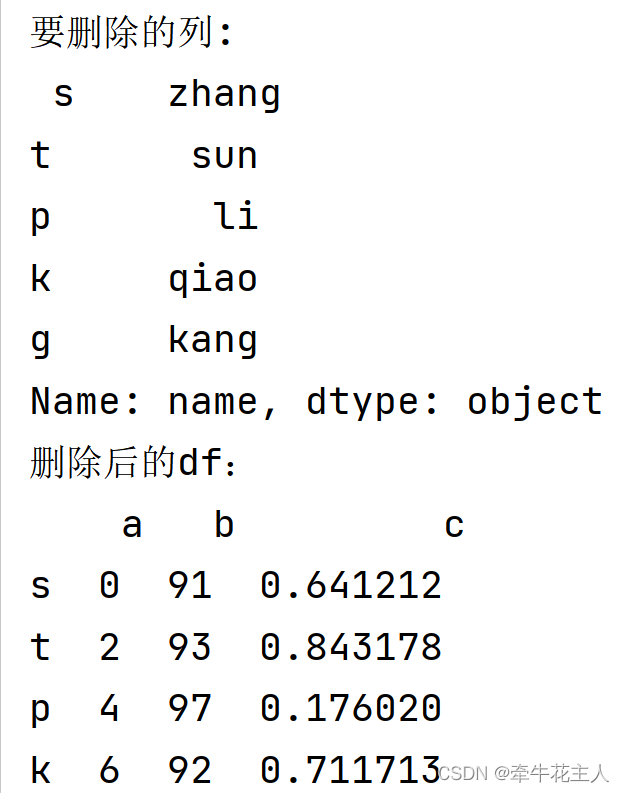
print('要删除的列: \n',df.pop('name'))
print('删除后的df:\n',df)
# df.tail()
print('df.tail:\n',df.tail(3))


















 6779
6779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









