






Hadoop分布式部署
环境:rhel6.5 selinux and iptables disabled, sshd enabled
主机: 192.168.2.1 master
192.168.0.137 slave
192.168.0.187 slave
192.168.0.151 slave
软件:hadoop.apache.org

主节点包括名称节点、从属名称节点和 jobtracker 守护进程(即所谓的主守护进程)以及管理
集群所用的实用程序和浏览器。从节点包括 tasktracker 和数据节点(从属守护进程)。两种设
置的不同之处在于,主节点包括提供 Hadoop 集群管理和协调的守护进程,而从节点包括实现
Hadoop 文件系统(HDFS)存储功能和 MapReduce 功能(数据处理功能)的守护进程。
每个守护进程在 Hadoop 框架中的作用。namenode 是 Hadoop 中的主服务器,它管理文件系
统名称空间和对集群中存储的文件的访问。还有一个 secondary namenode,它不是namenode 的冗余守护进程,而是提供周期检查点和清理任务。在每个 Hadoop 集群中可以找到一个 namenode 和一个 secondary namenode。
datanode 管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一
个 datanode 守护进程。每个集群有一个 jobtracker,它负责调度 datanode 上的工作。每个 datanode 有一个tasktracker,它们执行实际工作。jobtracker 和 tasktracker 采用主-从形式,jobtracker 跨datanode 分发工作,而tasktracker 执行任务。jobtracker 还检查请求的工作,如果一个datanode 由于某种原因失败,jobtracker 会重新调度以前的任务。
Hadoop文件系统(HDFS)存储功能
下载包hadoop-1.2.1.tar.gz
tar zxf hadoop-1.2.1.tar.gz
首先设置ssh无密钥连接
在节点机创建一个普通用户,useradd -u 800 hadoop
把软件考到hadoop家目录cp hadoop-1.2.1 /home/hadoop
加权限 chown -R hadoop.hadoop hadoop-1.2.1/
切换到hadoop用户 su - hadoop
设置ssh无密钥连接
下载java平台jdk-6u32-linux-x64.bin
sh jdk-6u32-linux-x64.bin
mv jdk1.6.0_32/ hadoop-1.2.1/ #便于移动
cd hadoop-1.2.1/
ln -s ./jdk1.6.0_32/ jdk #建立软链接
cd conf/
vim hadoop-env.sh
export JAVA_HOME=/home/hadoop/hadoop/jdk #设置java环境变量
ln -s ./hadoop-1.2.1/ hadoop #建立软链接,保证jdk路径为/home/hadoop/hadoop/jdk
cd /home/hadoop/hadoop
mkdir input
cp conf/* input/
bin/hadoop jar hadoop-examples-1.2.1.jar #运行发行版提供的示例程序:
bin/hadoop jar hadoop-examples-1.2.1.jar wordcount input output #不用提前创建output
cd output
cat *
伪分布式存储
namenode和datanode用作数据存储
jobtracker和tasktracker用作数据处理
$ cd hadoop/conf/
$ pwd
/home/hadoop/hadoop/conf
$ vim hadoop-env.sh
export JAVA_HOME=/home/hadoop/hadoop/jdk
vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
vim mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
[hadoop@node1 ~]$ cd hadoop/
$bin/hadoop namenode -format #格式化一个新的分布式文件系统
$ bin/start-all.sh #开启守护进程
$ cd
mkdir bin
$ ln -s /home/hadoop/hadoop/jdk/bin/jps ~/bin/
jps #查看
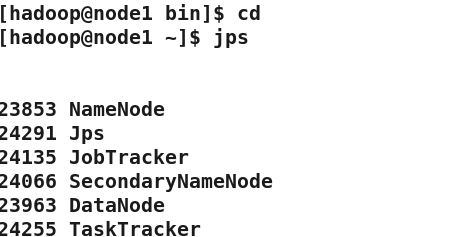
浏览 NameNode和 JobTracker的网络接口,它们的地址默认为:
NameNode – http://192.168.0.106:50070/
JobTracker – http://192.168.0.106:50030/
网页访问192.168.0.106:50030

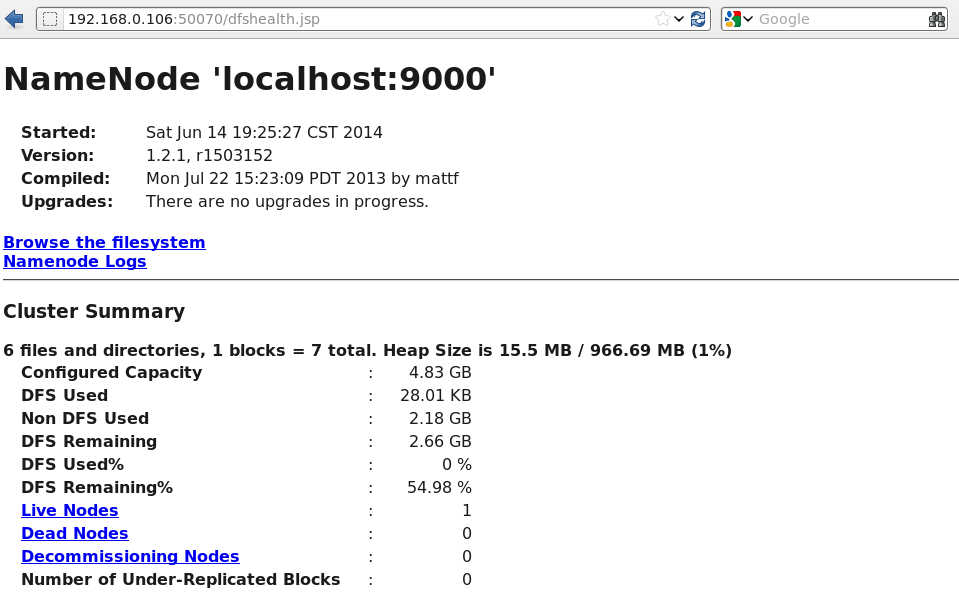
网页访问192.168.0.106:50070
$ bin/hadoop fs -ls
$ bin/hadoop fs -mkdir input
将输入文件拷贝到分布式文件系统:
$ bin/hadoop fs -put conf input
查看输出文件:
将输出文件从分布式文件系统拷贝到本地文件系统查看:
$ bin/hadoop fs -get output output
$ cat output/*
完全分布式存储
master(namenode):192.168.2.1
slave(datanode):192.168.2.2
slave(datanode):192.168.2.10 注意每个节点机都要有解析,selinux,火墙全部关掉。
设置无密钥连接,master到两个slave无密码。
在两个slave节点机上都添加hadoop用户,并设置密码一致。
master节点上:
$scp -r .ssh/ node2. example.com:
$scp -r .ssh/ server1. example.com:
node1 ssh连接node2和server1,验证是否无需密钥
cd conf/
$ vim masters
node1.example.com
$ vim slaves
node2.example.com
server1.example.com
$ vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node1.example.com:9000</value>
</property>
</configuration>
$ vim mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>node1.example.com:9001</value>
</property>
</configuration>
$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
scp -r hadoop-1.2.1/ node2.example.com:
scp -r hadoop-1.2.1/ server1.example.com:
node2和server1上:
$ln -s hadoop-1.2.1/ hadoop
$ ls
$ mkdir bin
$ ln -s /home/hadoop/hadoop/jdk/bin/jps bin/
$ cd bin/
主节点上:
$ bin/hadoop namenode -format #格式化
$ bin/start-all.sh #开启所有服务(在所有节点)
##### bin/hadoop-daemon.sh stop tasktracker 关闭当前节点的单个服务 tasktracker
$ jps #查看节点上的服务

开启了namenode jobtracker
slave节点:
$ jps

开启了datanode tasktracker
主节点:
$ bin/hadoop fs -put conf input #将输入文件拷贝到分布式文件系统
$ bin/hadoop fs -ls input #查看分布式文件,也可网页查看。
查看输出文件:(2种方式)
$ bin/hadoop fs -get output test #将输出文件从分布式文件系统拷贝到本地文件系统查看
$ cat test/*
或者
$ bin/hadoop fs -cat test/* #在分布式文件系统上查看输出文件:
hadoop 在线添加节点:
node1上:
dd if=/dev/zero of=bigfile bs=1M count=300
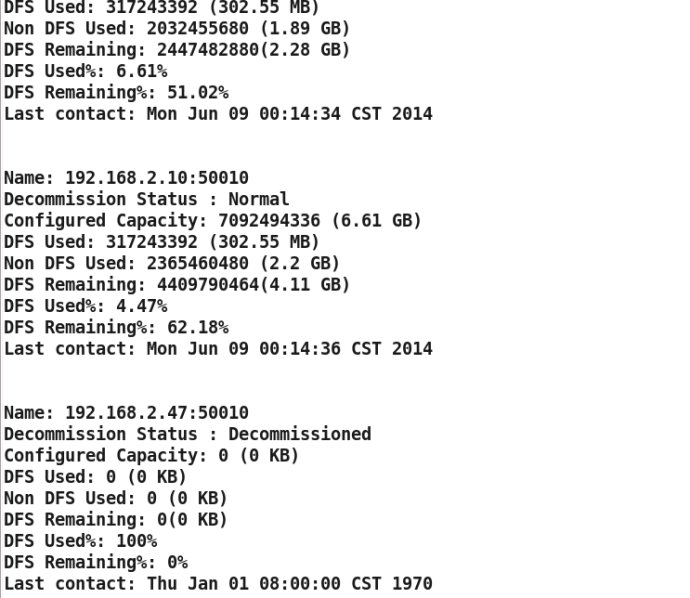
bin/hadoop dfsadmin -report #查看datanode状态
bin/hadoop fs -put ~/bigfile
bin/hadoop fs -mkdir files
bin/hadoop fs -put ~/bigfile files
bin/hadoop dfsadmin -report
scp -r .ssh/ server2.example.com:
scp -r hadoop-1.2.1/ server2.example.com:
1. 在新增节点上安装 jdk,并创建相同的 hadoop 用户,uid 等保持一致
2. 在 conf/slaves 文件中添加新增节点的 ip
3. 同步 master 上 hadoop 所有数据到新增节点上,路径保持一致
ln -s hadoop-1.2.1/ hadoop
mkdir bin
ln -s ~/hadoop/jdk/bin/jps bin/
4. 在新增节点上启动服务:
$ bin/hadoop-daemon.sh start datanode
$ bin/hadoop-daemon.sh start tasktracker
5. 均衡数据:
$ bin/start-balancer.sh
1)如果不执行均衡,那么 cluster 会把新的数据都存放在新的 datanode 上,这样会降低 mapred
的工作效率
2)设置平衡阈值,默认是 10%,值越低各节点越平衡,但消耗时间也更长
$ bin/start-balancer.sh -threshold 5
hadoop 在线删除 datanode 节点:
1. 在 master 上修改 conf/mapred-site.xml
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/hadoop/conf/datanode-excludes</value>
</property>
2. 创建 datanode-excludes 文件,并添加需要删除的主机,一行一个
server2.example.com
3. 在 master 上在线刷新节点
$ bin/hadoop dfsadmin -refreshNodes
此操作会在后台迁移数据,等此节点的状态显示为 Decommissioned,就可以安全关闭了。
4. 你可以通过以下命令在node1上查看 datanode 状态
$ bin/hadoop dfsadmin -report
在做数据迁移时,此节点不要参与 tasktracker,否则会出现异常。















 2915
2915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









