






MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
MapReduce是一种计算方式模型,主要用于搜索领域,解决海量的数据计算问题。
MapReduce有两个阶段组成:Map和Reduce,用户主要需要实现Map()和Reduce()两个函数,就能实现分布式计算。
MapReduce简称MR,MR的执行流程如下:
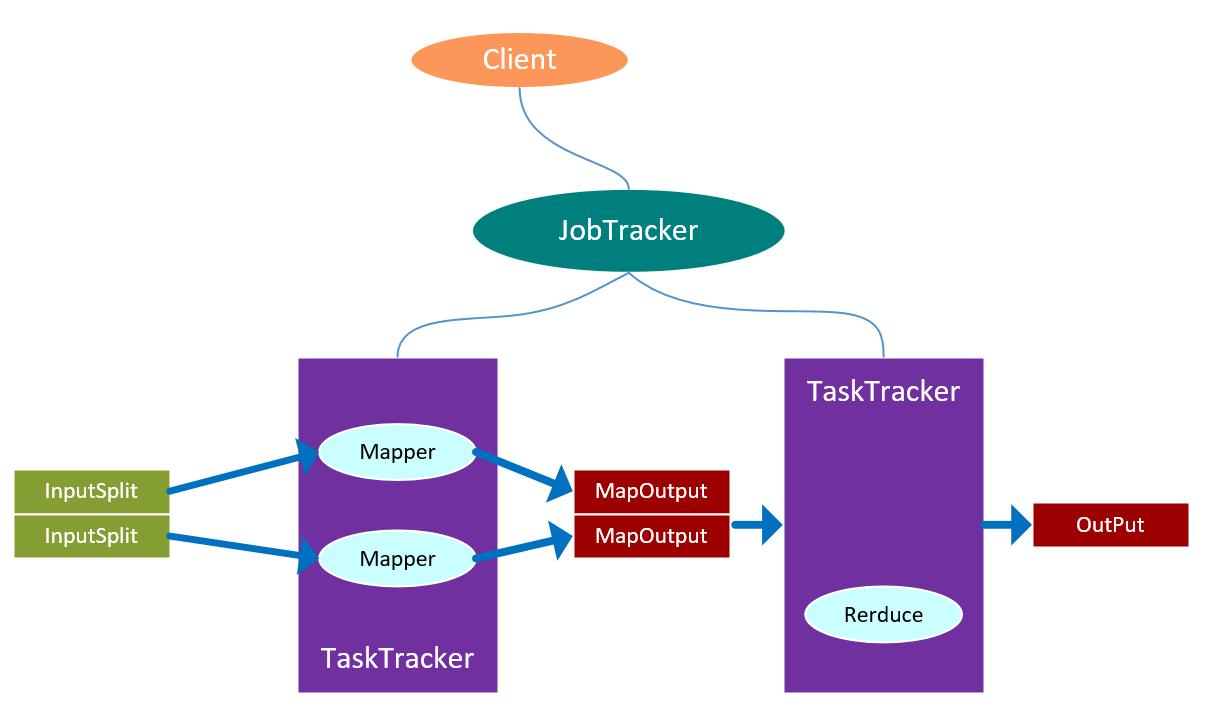
Map任务处理:
1.读取HDFS文件,按行解析成<K,V>,每一行都调用一次map函数,形成一个键值对;
2.覆盖map函数,接收到步骤1输入的<K,V>,按照实际的业务需求进行处理,转换成新的<K,V>输出;
3.对步骤2输出的<K,V>进行分区,默认为一个分区;
4.对不同分区的数据按照K进行排序、分组,分组指的是相同的K的value放到一个集合中:
排序后:<hello,1>,<hello,1>,<me,1>,<you,1>
分组后:<hell,{1,1}>,<me,{1}>,<you,{1}>
5.(可选)对分组后的数据进行规约。
Reduce任务处理:
1.多个map任务的输出,按照不同的分区,通过网络copy到不同的节点上;
2.对多个map的输出进行合并、排序,覆盖reduce函数,接受到的是分组后数据,实现自己的业务逻 辑,<hello,2>,<me,1>,<you,1>处理完成后,产生新的<K,V>输出;
3.对reduce输出的<K,V>写入到HDFS中;
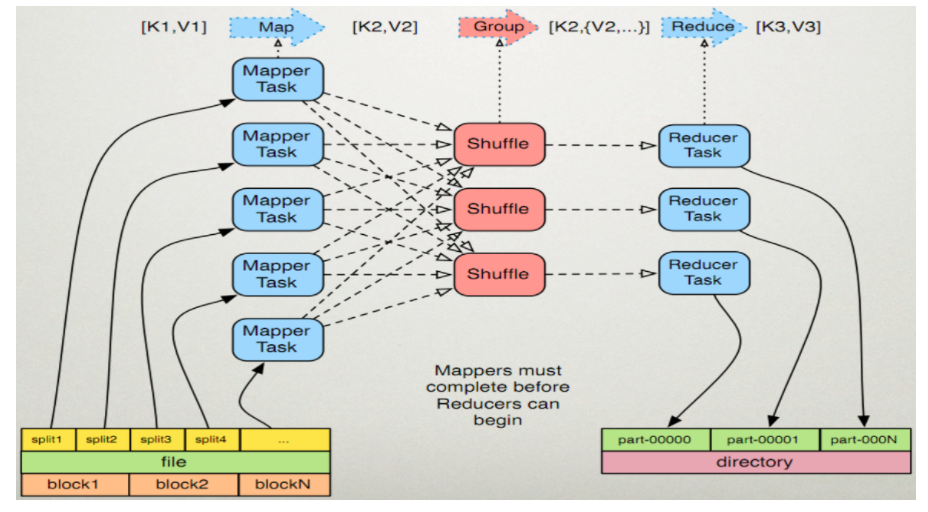
MR的原理如下:
代码实现部分:
Map函数
public class WordMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException {
String line = value.toString() ;
String[] words = line.split(" ");
for (String word:words) {
context.write(new Text(word),new IntWritable(1));
}
}
}Reduce函数
public class WordReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
Integer count = 0 ;
for (IntWritable value:values) {
count += value.get() ;
}
context.write(key,new IntWritable(count));
}
}主函数:
public class WordMapReduce {
public static void main(String[] args) throws Exception{
Configuration cfg = new Configuration() ;
Job job = Job.getInstance(cfg, "wordcount");
job.setJarByClass(WordMapReduce.class);
job.setMapperClass(WordMapper.class);
job.setReducerClass(WordReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean b = job.waitForCompletion(true);
}
}最后打包(示例项目是一个maven项目,需要打成jar,开发工具是IDEA)
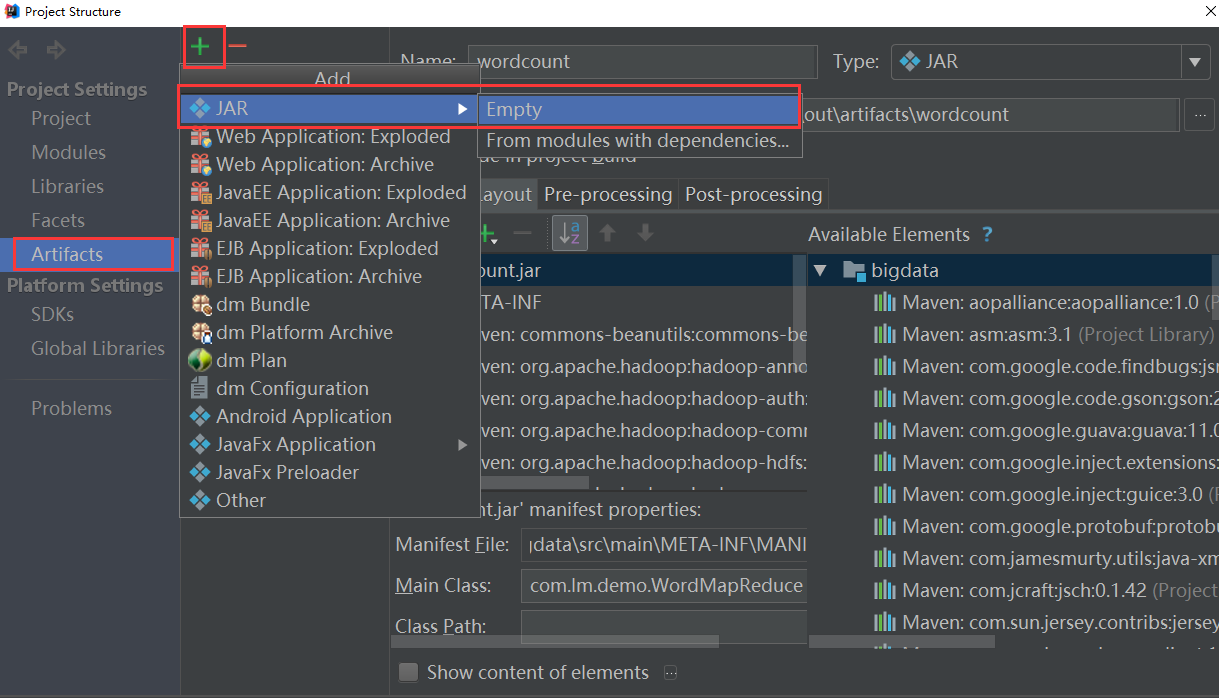
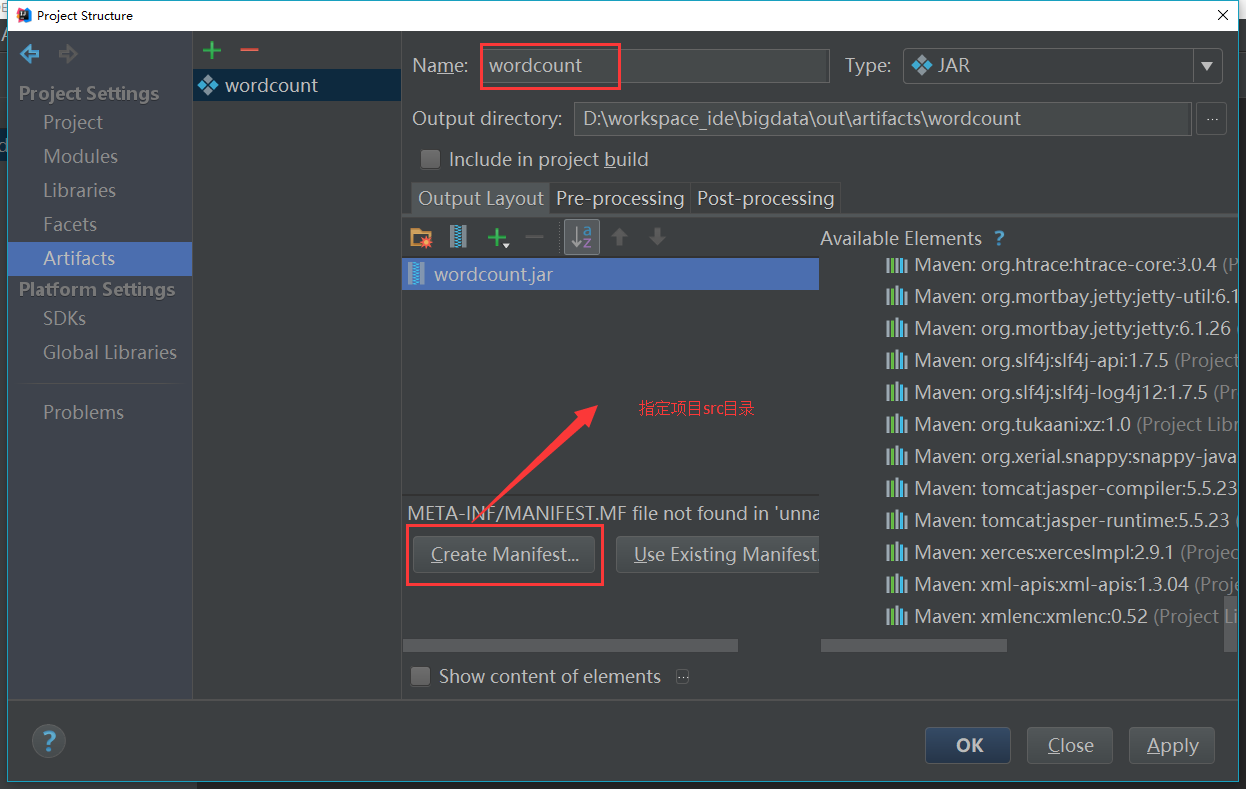
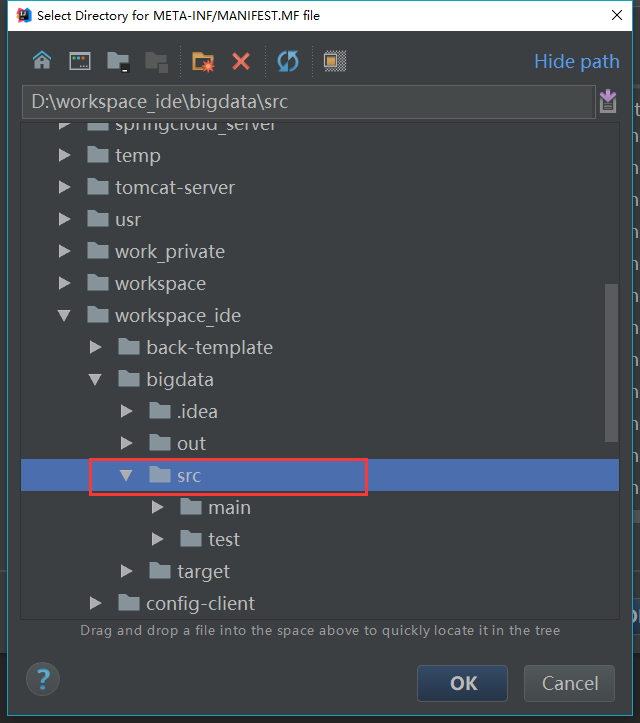
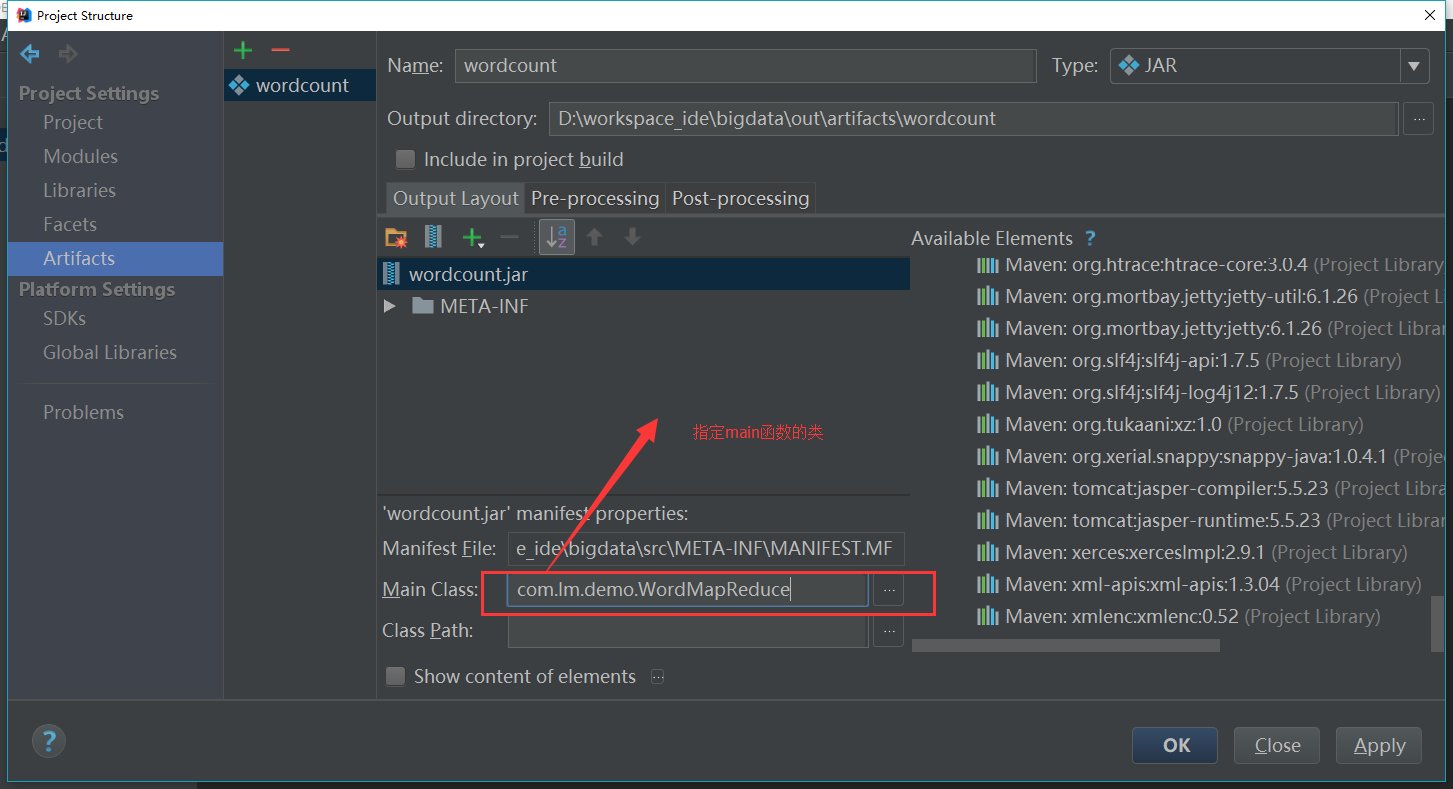
最后一步将需要使用的jar包导入:
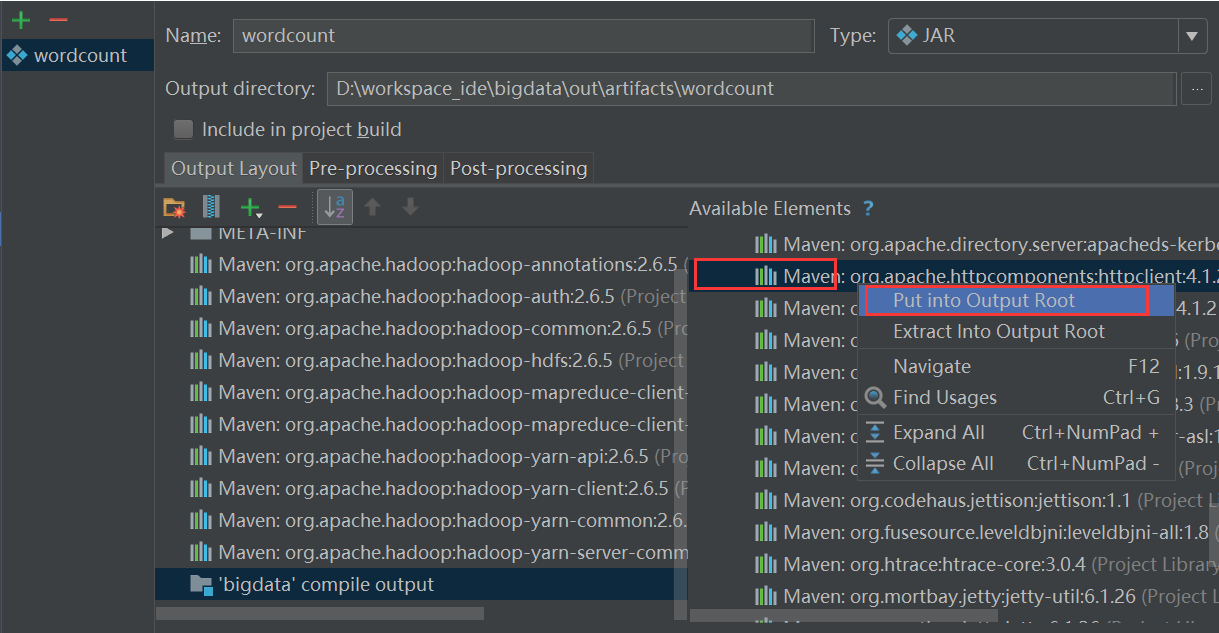
先选中一个jar,右键选择PutIntoOutputRoot即可,
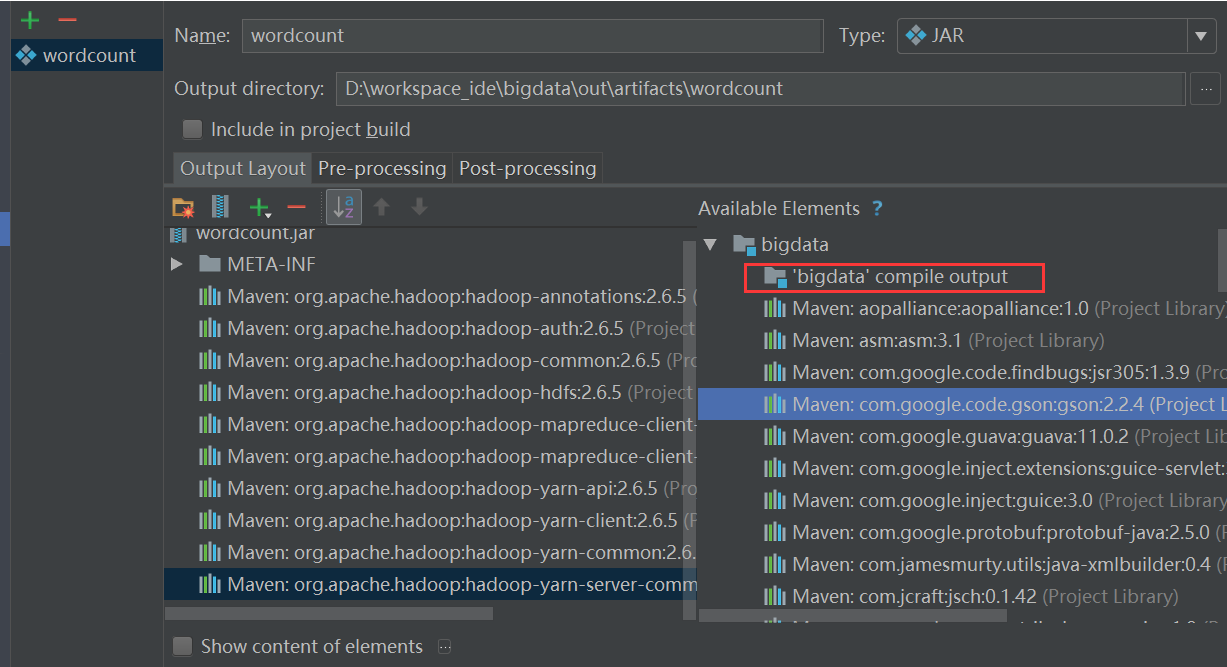
其中这个好像也要放过去,否则会有问题(待确认)。
最后执行build:


打包完成:
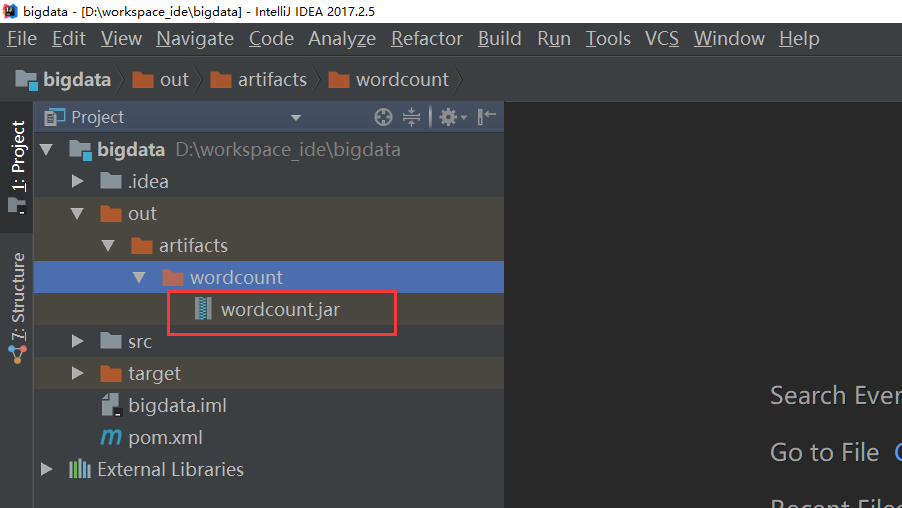
将jar包上传到hadoop的服务器:
执行以下命令:
hadoop jar wordcount.jar /input /out
此处配置了Hadoop的环境,类似jdk配置。
执行过程:
17/12/29 10:25:10 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
17/12/29 10:25:11 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
17/12/29 10:25:12 INFO input.FileInputFormat: Total input paths to process : 1
17/12/29 10:25:12 INFO mapreduce.JobSubmitter: number of splits:1
17/12/29 10:25:12 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1514431706831_0003
17/12/29 10:25:13 INFO impl.YarnClientImpl: Submitted application application_1514431706831_0003
17/12/29 10:25:13 INFO mapreduce.Job: The url to track the job: http://hadoop01:8088/proxy/application_1514431706831_0003/
17/12/29 10:25:13 INFO mapreduce.Job: Running job: job_1514431706831_0003
17/12/29 10:25:24 INFO mapreduce.Job: Job job_1514431706831_0003 running in uber mode : false
17/12/29 10:25:24 INFO mapreduce.Job: map 0% reduce 0%
17/12/29 10:25:31 INFO mapreduce.Job: map 100% reduce 0%
17/12/29 10:25:39 INFO mapreduce.Job: map 100% reduce 100%
17/12/29 10:25:40 INFO mapreduce.Job: Job job_1514431706831_0003 completed successfully
17/12/29 10:25:40 INFO mapreduce.Job: Counters: 49
查看结果:
hadoop fs -ls /out
-rw-r--r-- 1 root supergroup 0 2017-12-29 10:25 /out/_SUCCESS
-rw-r--r-- 1 root supergroup 32 2017-12-29 10:25 /out/part-r-00000
hadoop fs -text /out/p*
hadoop 1
hbase 1
hello 3
java 1















 5952
5952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









