






在当今的深度学习领域,神经网络已经成为解决各种复杂问题的强大工具。本文将通过一个实际案例——对Yelp餐厅评论进行情感分类,来介绍如何使用PyTorch构建和训练一个简单的神经网络模型。我们将逐步讲解神经网络的基础概念,如激活函数、损失函数和优化器,并最终实现一个完整的情感分类器。
一、 神经网络基础
在现代人工智能和机器学习领域,神经网络已经成为解决各种复杂问题的核心技术。它们能够模拟人脑的某些特性,通过大量的数据训练和优化,自动从数据中提取特征并进行预测或分类。本文将通过介绍神经网络的基础概念,帮助读者理解其工作原理。
1.1 感知器:最简单的神经网络单元
感知器是最简单的神经网络单元,通常被认为是构建复杂神经网络的基础。感知器模型模仿了生物神经元的工作机制,包含输入、权重、偏置和激活函数四个基本元素。
1.1.1 感知器的组成部分
- 输入(Input):输入值,可以是多个特征值的组合。
- 权重(Weight):每个输入值对应一个权重,用于衡量该输入在最终输出中的重要性。
- 偏置(Bias):一个额外的参数,用于调整输出结果,增加模型的灵活性。
- 激活函数(Activation Function):将线性组合的结果转换为非线性输出,从而引入复杂性,使得神经网络能够拟合复杂的数据模式。
1.1.2 感知器的工作原理
感知器通过对输入值进行加权求和,再加上偏置,得到一个线性组合结果。然后,激活函数将这个线性组合结果转换为最终输出。其数学表达式如下:
其中:
- x 是输入向量
- w是权重向量
- b 是偏置
- f 是激活函数
感知器的输出 yyy 是一个通过激活函数处理后的值,用于二分类任务时,通常是一个0到1之间的概率值。
感知器结构图
下面的图示展示了一个简单感知器的结构:
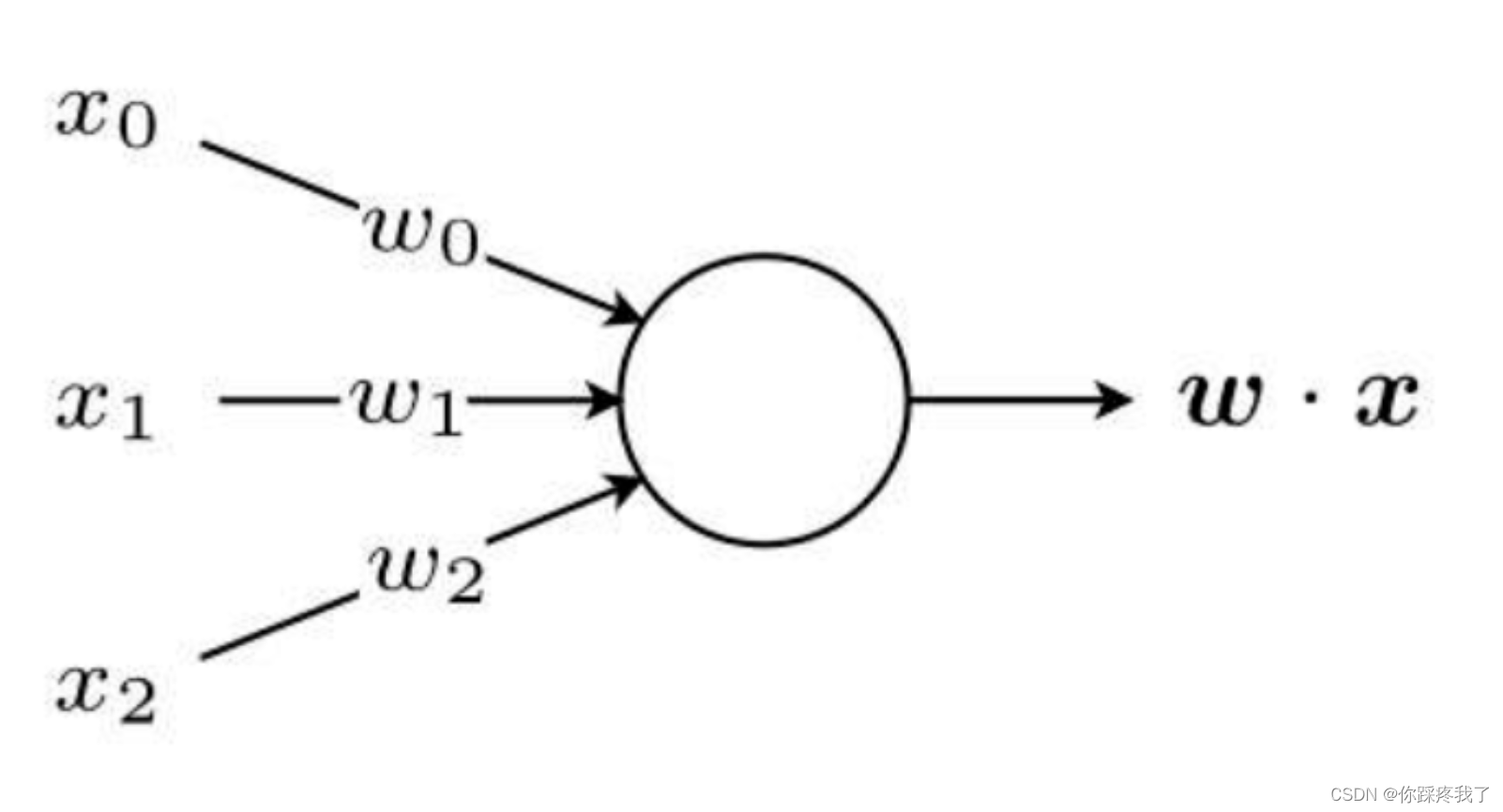
1.1.3 PyTorch中的感知器实现
PyTorch是一个强大的深度学习框架,提供了丰富的工具用于构建和训练神经网络。以下是使用PyTorch实现一个简单感知器的示例代码
import torch
import torch.nn as nn
class Perceptron(nn.Module):
def __init__(self, input_dim):
super(Perceptron, self).__init__()
self.fc1 = nn.Linear(input_dim, 1) # 定义一个线性层
def forward(self, x_in, apply_sigmoid=False):
y_out = self.fc1(x_in).squeeze() # 计算线性组合
if apply_sigmoid:
y_out = torch.sigmoid(y_out) # 应用sigmoid激活函数
return y_out
在上述代码中,我们定义了一个包含单个线性层的感知器模型,并可选择性地使用sigmoid函数作为激活函数。
1.2 激活函数
激活函数是神经网络中引入非线性的关键组件,它能够使神经网络捕捉到数据中的复杂模式。如果没有激活函数,神经网络的输出将只是输入的线性组合,无法解决复杂的非线性问题。常见的激活函数包括Sigmoid、Tanh和ReLU。
1.2.1 Sigmoid 函数
Sigmoid函数将输入值映射到0和1之间,常用于二分类任务的输出层。其数学表达式为:
Sigmoid函数具有平滑且连续的特性,可以解释为输入属于某一类的概率。它的缺点是当输入值很大或很小时,梯度会变得非常小,导致训练速度变慢,甚至出现梯度消失的问题。
Sigmoid 函数图示
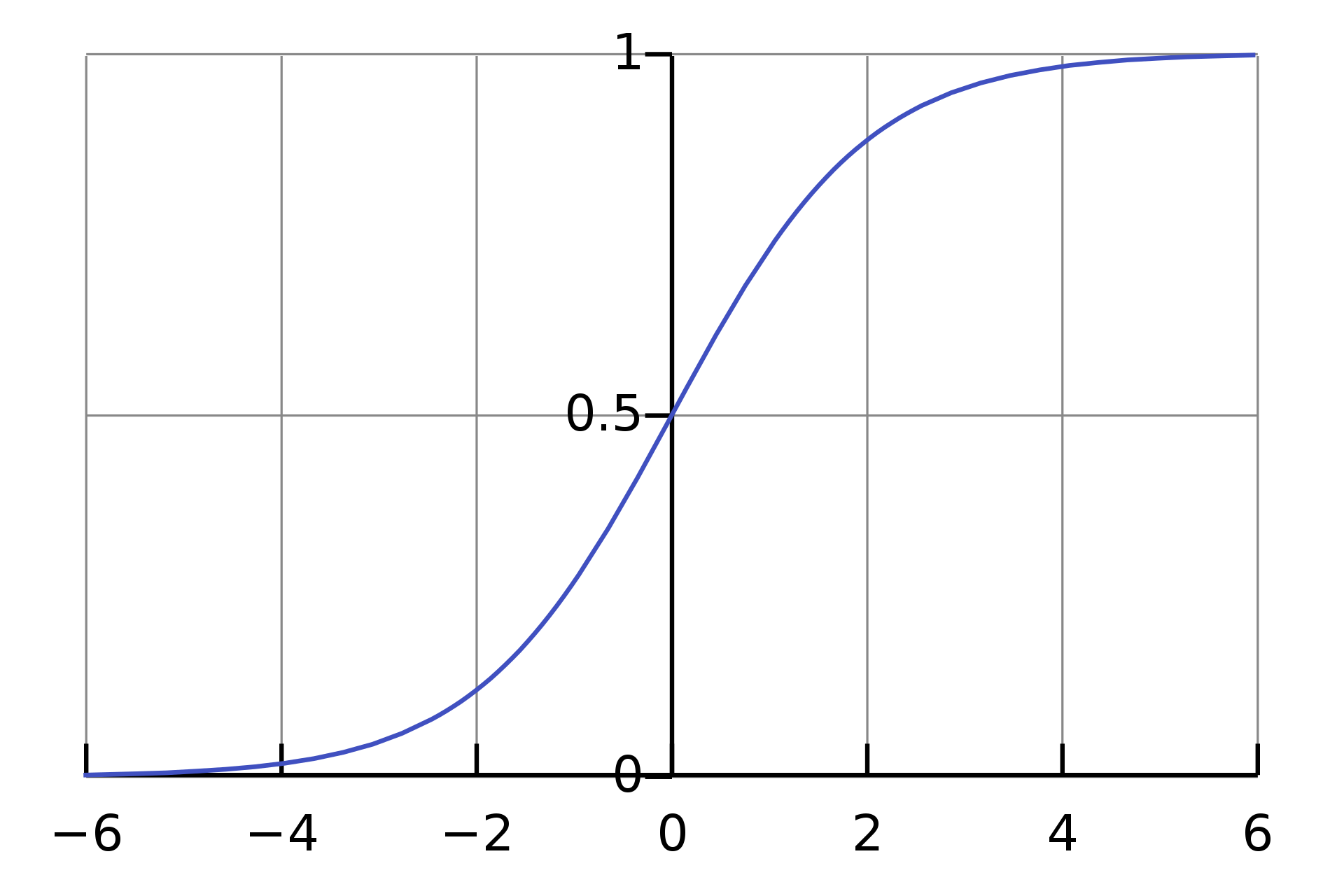
以下是使用PyTorch绘制Sigmoid函数的代码:
import torch
import matplotlib.pyplot as plt
# 创建输入张量,从-5到5,步长为0.1
x = torch.arange(-5., 5., 0.1)
# 计算Sigmoid函数的输出
y = torch.sigmoid(x)
# 绘制Sigmoid函数图像
plt.plot(x.numpy(), y.numpy())
plt.title("Sigmoid Activation Function")
plt.xlabel("Input")
plt.ylabel("Output")
plt.show()
1.2.2 Tanh 函数
Tanh(双曲正切)函数是Sigmoid函数的变体,将输入值映射到-1和1之间。其数学表达式为:
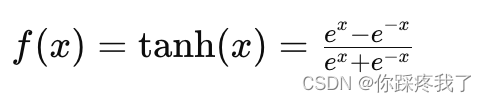
Tanh函数的输出值中心在0,这意味着它的输出分布更均匀,适合处理有正负值的输入。然而,它也存在梯度消失的问题。
Tanh 函数图示
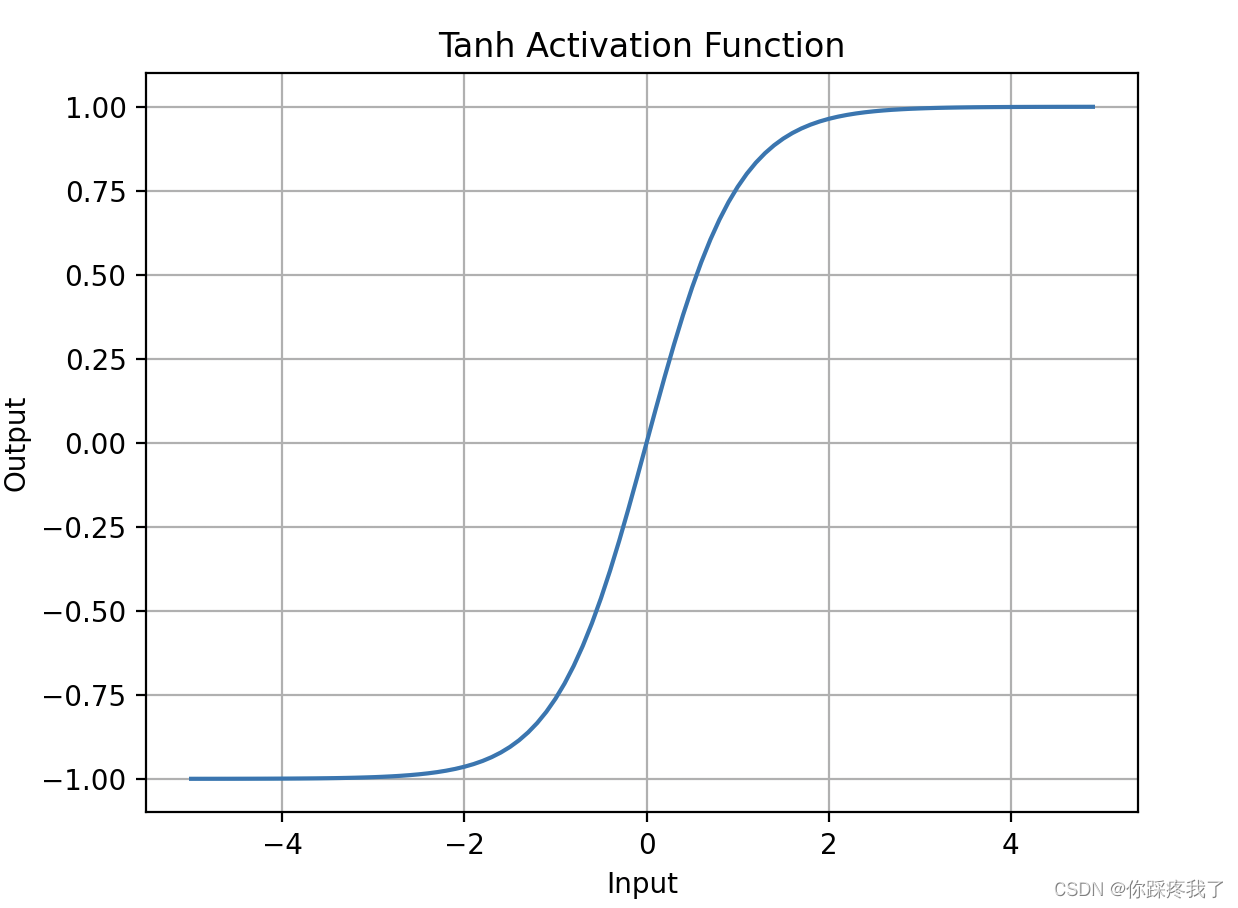
以下是使用PyTorch绘制Tanh函数的代码:
# 计算Tanh函数的输出
y = torch.tanh(x)
# 绘制Tanh函数图像
plt.plot(x.numpy(), y.numpy())
plt.title("Tanh Activation Function")
plt.xlabel("Input")
plt.ylabel("Output")
plt.show()
1.2.3 ReLU 函数
ReLU(Rectified Linear Unit)函数是目前使用最广泛的激活函数之一。它将输入的负值裁剪为零,正值保持不变。其数学表达式为:
ReLU函数的优点是计算简单且有效,能够加速训练过程,并缓解梯度消失问题。然而,ReLU也存在一个问题,即在训练过程中,某些神经元可能会因为梯度为零而永远不被激活,这被称为“神经元死亡”问题。
ReLU 函数图示:
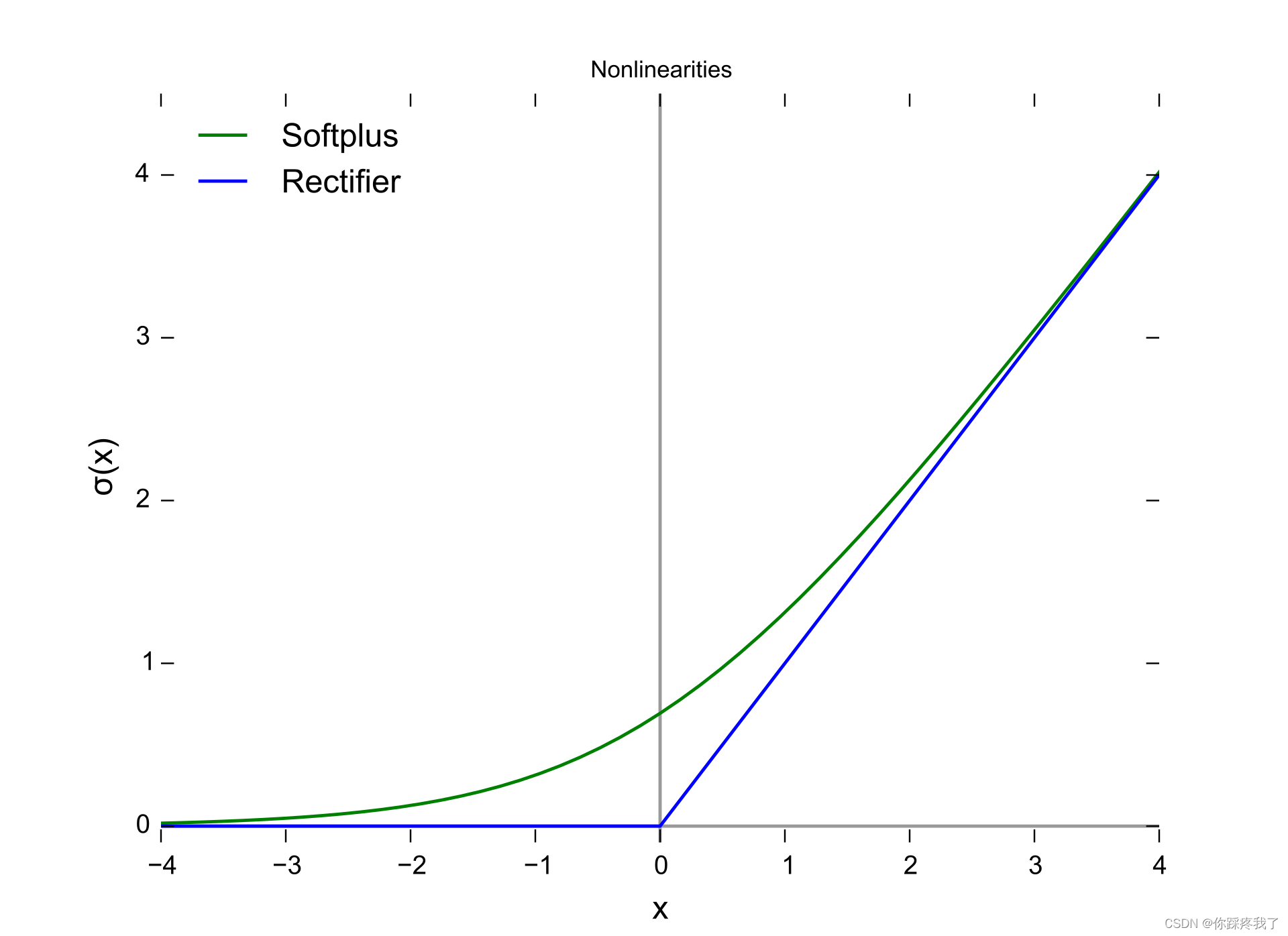
以下是使用PyTorch绘制ReLU函数的代码:
# 定义ReLU激活函数
relu = torch.nn.ReLU()
# 计算ReLU函数的输出
y = relu(x)
# 绘制ReLU函数图像
plt.plot(x.numpy(), y.numpy())
plt.title("ReLU Activation Function")
plt.xlabel("Input")
plt.ylabel("Output")
plt.show()
1.3 为什么需要非线性?
激活函数的引入使得神经网络可以捕获复杂的非线性关系。如果没有激活函数(即使用线性激活函数),无论网络有多少层,其输出都是输入的线性组合,无法处理复杂问题。通过使用非线性激活函数,网络能够在每一层中引入非线性变换,从而能够逼近任何复杂的函数关系,这就是著名的“通用逼近定理”。
通过上述激活函数的介绍,我们可以看到每种激活函数都有其优缺点,在实际应用中需要根据具体问题选择合适的激活函数。
二、 损失函数和优化器
在构建和训练神经网络时,损失函数和优化器是两个关键组件。损失函数用于衡量模型预测与真实值之间的误差,而优化器则根据损失函数提供的误差信号来调整模型的参数,以逐步减小误差。
2.1 损失函数
损失函数(也称为目标函数或代价函数)是衡量模型预测值与真实值之间差距的函数。损失函数的选择直接影响到模型的训练效果和收敛速度。常见的损失函数包括均方误差损失(MSE)、交叉熵损失等。
2.1.1 均方误差损失(MSE)
均方误差损失主要用于回归问题,它计算预测值与真实值之间差值的平方和的平均值。其数学表达式为:
其中,y 是真实值,y^ 是预测值,n是样本数量。
使用 PyTorch 实现 MSE 损失函数的代码如下:
import torch
import torch.nn as nn
# 定义MSE损失函数
mse_loss = nn.MSELoss()
# 创建预测值和真实值的张量
outputs = torch.randn(3, 5, requires_grad=True)
targets = torch.randn(3, 5)
# 计算损失值
loss = mse_loss(outputs, targets)
print(f'MSE Loss: {loss.item()}')
输出:MSE Loss: 3.1874008178710938
代码说明:
- 首先,我们定义了一个
MSELoss对象mse_loss。 - 然后,我们创建了两个随机张量
outputs和targets,分别代表预测值和真实值。 - 使用
mse_loss计算这两个张量之间的均方误差,并打印结果。
2.1.2 交叉熵损失(Cross-Entropy Loss)
交叉熵损失常用于分类问题,特别是多类分类。它衡量的是预测的概率分布与真实标签分布之间的差异。其数学表达式为:
![]()
其中,y 是真实标签的概率分布,y^ 是预测的概率分布。
使用 PyTorch 实现交叉熵损失的代码如下:
import torch
import torch.nn as nn
# 定义交叉熵损失函数
ce_loss = nn.CrossEntropyLoss()
# 创建预测值和真实标签的张量
outputs = torch.randn(3, 5, requires_grad=True)
targets = torch.tensor([1, 0, 3], dtype=torch.int64)
# 计算损失值
loss = ce_loss(outputs, targets)
print(f'Cross-Entropy Loss: {loss.item()}')
输出:Cross-Entropy Loss: 1.6887081861495972
代码说明:
- 首先,我们定义了一个
CrossEntropyLoss对象ce_loss。 - 然后,我们创建了一个随机张量
outputs作为预测值,以及一个整数张量targets作为真实标签。 - 使用
ce_loss计算交叉熵损失,并打印结果。
2.2 优化器
优化器是用于根据损失函数的梯度更新模型参数的算法。在训练神经网络时,优化器通过迭代调整模型参数,使得损失函数的值逐渐减小,进而提高模型的性能。常见的优化器包括随机梯度下降(SGD)、Adam等。
2.2.1 随机梯度下降(SGD)
随机梯度下降是一种简单而有效的优化算法。它通过计算每个小批量样本的损失梯度,逐步更新模型参数。其参数更新公式为:
![]()
其中,θ 是模型参数,η是学习率,∇J(θ) 是损失函数的梯度。
使用 PyTorch 实现 SGD 优化器的代码如下:
import torch.optim as optim
# 定义模型参数
params = torch.randn(2, 2, requires_grad=True)
# 定义SGD优化器
optimizer = optim.SGD([params], lr=0.01)
# 前向传播计算损失
loss = torch.mean(params ** 2)
# 反向传播计算梯度
loss.backward()
# 更新模型参数
optimizer.step()
代码说明:
- 首先,我们定义了一个模型参数
params,并启用梯度计算。 - 然后,我们定义了一个 SGD 优化器
optimizer,学习率设置为 0.01。 - 计算模型参数的均方误差
loss。 - 调用
loss.backward()计算梯度。 - 最后,调用
optimizer.step()更新模型参数。
2.2.2 Adam
Adam(Adaptive Moment Estimation)是目前最受欢迎的优化算法之一。它结合了动量方法和自适应学习率方法,能够更快地收敛到全局最优解。其参数更新公式较为复杂,包含一阶矩估计和二阶矩估计。
使用 PyTorch 实现 Adam 优化器的代码如下:
# 定义Adam优化器
optimizer = optim.Adam([params], lr=0.001)
# 前向传播计算损失
loss = torch.mean(params ** 2)
# 反向传播计算梯度
loss.backward()
# 更新模型参数
optimizer.step()
代码说明:
- 首先,我们定义了一个 Adam 优化器
optimizer,学习率设置为 0.001。 - 计算模型参数的均方误差
loss。 - 调用
loss.backward()计算梯度。 - 最后,调用
optimizer.step()更新模型参数。
通过合理选择损失函数和优化器,可以有效地指导神经网络的训练过程,使模型更快地收敛并获得更好的性能。这种精细的调整不仅能提高模型的准确性,还能增强其在新数据上的泛化能力,从而在实际应用中表现更为出色。在下一部分中,我们将深入探讨如何实现训练循环,包括如何加载数据、训练模型以及评估模型性能等内容。通过这些步骤,您将全面掌握构建和训练神经网络的核心技术。
三、深入监督学习
在这一部分,我们将通过一个简单的玩具示例,深入探索监督学习的基本概念和实现步骤。这不仅能帮助我们理解算法的运作,还能为构建复杂的模型打下坚实的基础。
3.1 监督学习中的基本概念
监督学习是机器学习中的一种核心方法,主要用于分类和回归任务。在监督学习中,模型通过学习已知的输入输出对进行训练,从而在给定新的输入时预测相应的输出。
3.2 构建玩具数据
为了更好地理解算法,我们通常会创建一些易于理解的合成数据。在本节中,我们将生成二维点数据,并将其分类为两个类。我们从xy平面的两个不同区域采样点,为模型创建一个易于学习的环境。
下图展示了这一过程:
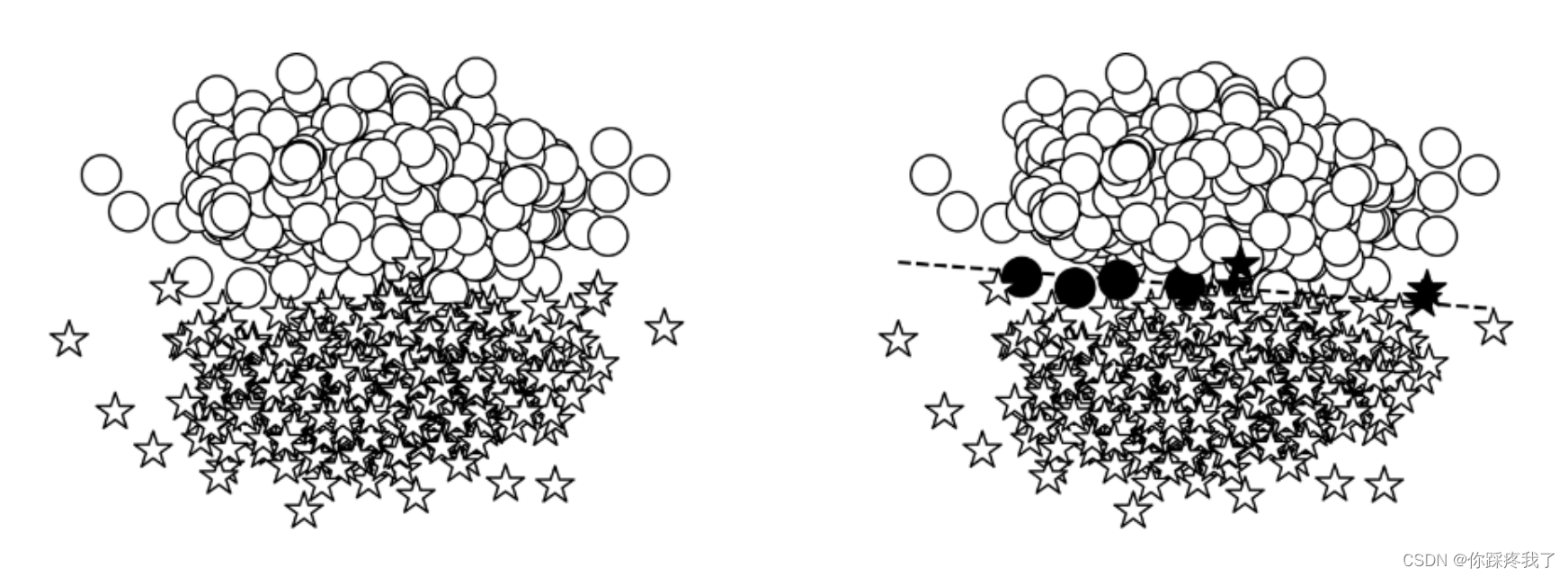
模型的目标是将星星(⋆)作为一个类,(◯)作为另一个类。这可以在图的右边看到,线上面的东西和线下面的东西分类不同。生成数据的代码位于本实验附带的 Python notebook 中名为get_toy_data()的函数中。
创建数据集的步骤:
- 选择数据点中心:选择两个中心点,分别代表两个类别的数据点。
- 从正态分布采样:围绕这两个中心点,从正态分布中采样数据点。
- 分配标签:将不同中心点的采样数据点分配不同的标签。
import numpy as np
import torch
def get_toy_data(batch_size, left_center=(2, 2), right_center=(8, 8)):
x_data = []
y_data = []
for _ in range(batch_size):
if np.random.random() > 0.5:
x_data.append(np.random.normal(loc=left_center, scale=1))
y_data.append(0)
else:
x_data.append(np.random.normal(loc=right_center, scale=1))
y_data.append(1)
return torch.tensor(x_data, dtype=torch.float32), torch.tensor(y_data, dtype=torch.float32)
x_data, y_data = get_toy_data(batch_size=100)
print(x_data[:5], y_data[:5])
输出:
代码解释:
get_toy_data函数生成二维数据点,分别从两个不同的正态分布中采样,并分配不同的标签。batch_size参数控制生成数据的数量。left_center和right_center分别表示两个类的中心。
3.3 选择模型
我们在这里使用的模型是在本实验开头介绍的:感知器。感知器是灵活的,因为它允许任何大小的输入。在典型的建模情况下,输入大小由任务和数据决定。在这个玩具示例中,输入大小为2,因为我们显式地将数据构造为二维平面。对于这个两类问题,我们为类指定一个数字索引:0 和 1。字符串的映射标签 ⋆ 和 ◯ 类指数是任意的,只要它在数据预处理是一致的,培训,评估和测试。该模型的另一个重要属性是其输出的性质。由于感知器的激活函数是一个 sigmoid,感知器的输出为数据点 (x) 为 class 1 的概率;即P(y=1|x)
感知器模型的特点:
- 输入层:接收输入数据。
- 输出层:计算线性组合,并通过激活函数转换为概率值。
- 激活函数:sigmoid 函数将输出值压缩在0到1之间,表示概率。
import torch.nn as nn
class Perceptron(nn.Module):
def __init__(self, input_dim):
super(Perceptron, self).__init__()
self.fc1 = nn.Linear(input_dim, 1)
def forward(self, x_in, apply_sigmoid=False):
y_out = self.fc1(x_in).squeeze()
if apply_sigmoid:
y_out = torch.sigmoid(y_out)
return y_out
model = Perceptron(input_dim=2)
print(model)
输出:

代码解释:
Perceptron类继承自nn.Module,定义了一个简单的线性层。forward方法中,如果apply_sigmoid为True,则应用 sigmoid 激活函数。
3.4 选择损失函数
选择合适的损失函数是监督学习中的关键步骤。在二元分类任务中,最合适的损失函数是二元交叉熵损失(BCELoss)。为了提高数值稳定性,我们使用 BCEWithLogitsLoss,它将 sigmoid 激活和 BCELoss 合并在一起。
损失函数的选择:
- 二元交叉熵损失:适用于二元分类问题。
- 数值稳定性:
BCEWithLogitsLoss内部包含了 sigmoid 函数,避免了数值不稳定问题。
criterion = nn.BCEWithLogitsLoss()
3.5 选择优化器
优化器是控制模型参数更新的算法。在本示例中,我们使用 Adam 优化器。Adam 是一种自适应学习率优化器,通常在许多情况下表现出色。
优化器的选择:
- SGD(随机梯度下降):经典优化算法,但在复杂问题上可能收敛较慢。
- Adam(自适应矩估计):结合了动量和自适应学习率,在大多数情况下效果更好。
import torch.optim as optim
optimizer = optim.Adam(model.parameters(), lr=0.001)
3.6 训练模型
训练模型包括前向传播、损失计算、反向传播和参数更新等步骤。我们将在每个 epoch 中重复这些步骤,直到模型收敛。
训练过程:
- 前向传播:通过模型计算预测值。
- 计算损失:根据预测值和真实值计算损失。
- 反向传播:计算损失函数的梯度。
- 参数更新:优化器根据梯度更新模型参数。
from tqdm import tqdm
# 生成数据的函数
def get_toy_data(batch_size, left_center=(2, 2), right_center=(8, 8)):
x_data = []
y_targets = np.zeros(batch_size)
for batch_i in range(batch_size):
if np.random.random() > 0.5:
x_data.append(np.random.normal(loc=left_center))
else:
x_data.append(np.random.normal(loc=right_center))
y_targets[batch_i] = 1
return torch.tensor(x_data, dtype=torch.float32), torch.tensor(y_targets, dtype=torch.float32)
# 定义中心点
LEFT_CENTER = (3, 3)
RIGHT_CENTER = (3, -2)
# 超参数
lr = 0.01
input_dim = 2
batch_size = 1000
n_epochs = 12
n_batches = 5
seed = 1337
# 每个 epoch 代表对整个训练数据的完整遍历
for epoch_i in range(n_epochs):
for batch_i in tqdm(range(n_batches), desc=f'Epoch{epoch_i + 1:2d}/{n_epochs}'):
x_data, y_target = get_toy_data(batch_size)
perceptron.zero_grad()
y_pred = perceptron(x_data, apply_sigmoid=True)
loss = bce_loss(y_pred, y_target)
loss.backward()
optimizer.step()

代码解释:
- 通过循环遍历数据集,执行前向传播、计算损失、反向传播和参数更新。
tqdm库用于显示训练进度。
通过合理选择损失函数和优化器,可以更好地训练神经网络,提高模型的准确性和泛化能力。
3.7 模型评估
评估模型的性能是机器学习过程中至关重要的一步。准确评估模型可以帮助我们了解其泛化能力,即模型在训练数据之外的新数据上的表现。通常,我们使用多个指标来评估模型的性能,以确保其适用于不同的任务和数据集。在本小节中,我们将讨论几种常见的评估指标及其在自然语言处理(NLP)中的应用。
3.7.1评价指标
在监督训练循环之外,最重要的部分是使用模型从未训练过的数据来客观衡量性能。模型使用一个或多个评估指标进行评估。在自然语言处理(NLP)中,常见的评估指标包括准确率、精确率、召回率和 F1 分数。我们在本实验中主要使用准确率来评估模型。
以下是几种常见的评估指标:
1、准确率(Accuracy):这是最常用的评估指标之一,定义为正确预测的样本数占总样本数的比例。对于二分类问题,准确率的计算公式为:
![]()
尽管准确率直观且易于理解,但在处理类别不平衡的数据集时,它可能并不适用。例如,在一个类别占绝大多数的情况下,高准确率可能只是因为模型倾向于预测占多数的类别。
2、精确率(Precision):精确率衡量的是模型在所有预测为正类的样本中,实际为正类的比例。其计算公式为:
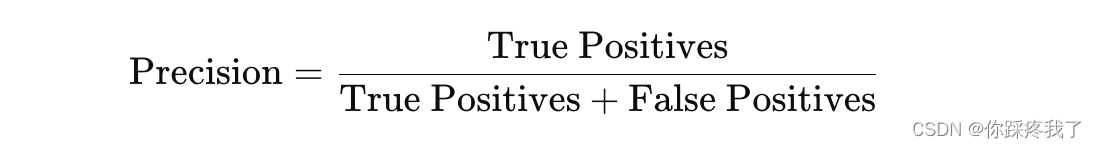
3、召回率(Recall):召回率衡量的是模型在所有实际为正类的样本中,正确预测为正类的比例。其计算公式为:
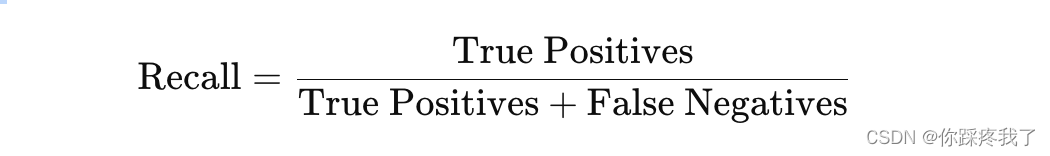
召回率适用于关注漏报较少的应用场景。
4、 F1 分数(F1 Score):F1 分数是精确率和召回率的调和平均数,综合考虑了两者的影响。其计算公式为:

F1 分数适用于需要平衡精确率和召回率的应用场景。
3.7.2 数据集划分
为了确保模型能够很好地概括数据的真实分布,我们通常将数据集分为三个部分:训练集、验证集和测试集。常见的划分比例是70%用于训练,15%用于验证,15%用于测试。在某些情况下,我们可能会使用交叉验证技术,如 k 折交叉验证,以更全面地评估模型的性能。
数据集的分割:
- 训练集:用于训练模型。
- 验证集:用于调参和选择模型。
- 测试集:用于评估模型的最终性能。
from sklearn.model_selection import train_test_split
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.2, random_state=42)
3.7.3 何时停止训练:早停法
在训练过程中,我们需要知道何时停止训练。最常用的方法是早停法(early stopping),通过监测验证集上的性能,如果性能不再改进,则停止训练。这可以防止模型过拟合,并节省计算资源。以下代码示例展示了如何实现早停法:
# 早停法实现示例
best_val_loss = float('inf')
patience = 5
trigger_times = 0
for epoch in range(n_epochs):
# 训练代码省略...
# 验证步骤
model.eval()
with torch.no_grad():
val_pred = model(x_val, apply_sigmoid=True)
val_loss = loss_fn(val_pred, y_val)
# 早停判断
if val_loss < best_val_loss:
best_val_loss = val_loss
trigger_times = 0
else:
trigger_times += 1
if trigger_times >= patience:
print("Early stopping at epoch:", epoch)
break
代码解释:
best_val_loss用于记录验证集上的最佳损失。patience表示在没有改进的情况下允许的最大连续 epoch 数。trigger_times用于记录连续没有改进的 epoch 数。
3.7.4 正则化
正则化是防止模型过拟合的重要技术。
正则化的概念来源于数值优化理论。回想一下,大多数机器学习算法都在优化损失函数,以找到最可能解释观测结果(即,产生的损失最少)。对于大多数数据集和任务,这个优化问题可能有多个解决方案(可能的模型)。那么我们(或优化器)应该选择哪一个呢?为了形成直观的理解,请思考下图通过一组点拟合曲线的任务:
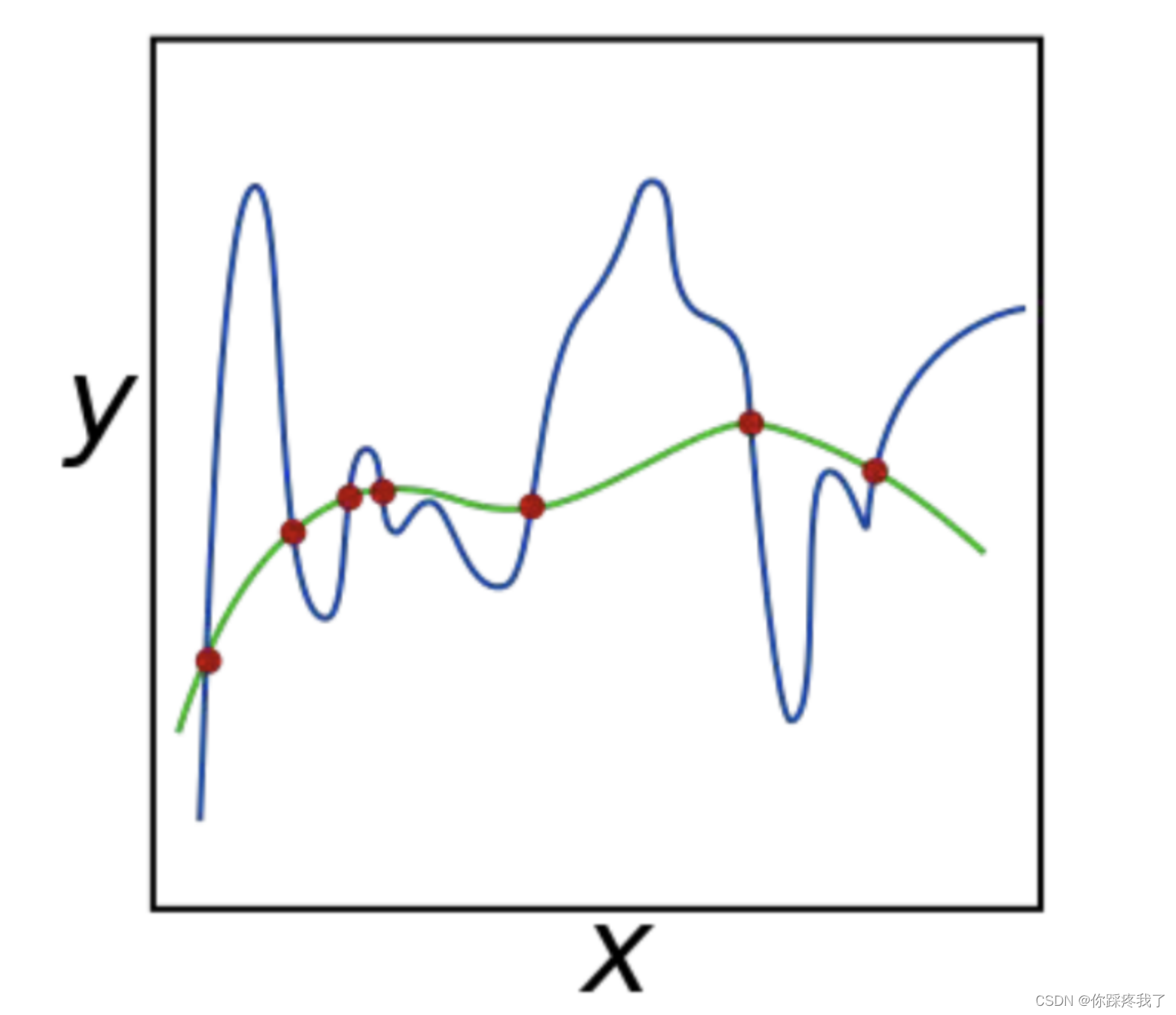
两条曲线都“fit”这些点,但哪一条是不太可能的解释呢?通过求助于奥卡姆剃刀,我们凭直觉知道一个简单的解释比复杂的解释更好。这种机器学习中的平滑约束称为 L2 正则化。在 PyTorch 中,可以通过在优化器中设置 weight_decay 参数来控制这一点。weight_decay 值越大,优化器选择的解释就越流畅;也就是说,L2 正则化越强。
在 PyTorch 中,我们可以通过在优化器中设置 weight_decay 参数来应用 L2 正则化。此外,我们还可以使用 dropout 技术,随机丢弃一些神经元以提高模型的泛化能力。以下代码示例展示了如何应用 L2 正则化和 dropout 技术:
# 使用 L2 正则化的 Adam 优化器
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=0.01)
# Dropout 示例
class Perceptron(nn.Module):
def __init__(self, input_dim):
super(Perceptron, self).__init__()
self.fc1 = nn.Linear(input_dim, 1)
self.dropout = nn.Dropout(p=0.5)
def forward(self, x_in, apply_sigmoid=False):
x_in = self.dropout(x_in)
y_out = self.fc1(x_in).squeeze()
if apply_sigmoid:
y_out = torch.sigmoid(y_out)
return y_out
四、餐厅评论的情感分类示例
4.1 Yelp 评论数据集
2015年,Yelp 举办了一场竞赛,要求参与者根据评论预测餐厅的评级。同年,Zhang, Zhao 和 Lecun(2015)简化了数据集,将 1 星和 2 星评级转换为“消极”情绪类,将 3 星和 4 星评级转换为“积极”情绪类。这个数据集包含 56 万个训练样本和 3.8 万个测试样本。在本节中,我们将介绍如何最小化数据清理并导出最终数据集的过程,并展示如何利用 PyTorch 的数据集类实现数据集的处理。
4.1.1 数据集简介
在这个例子中,我们使用的是简化版的 Yelp 数据集。这有两个细微的区别:首先,我们使用的是数据集的“轻量级”版本,这个版本是通过选择 10% 的训练样本派生出来的。这样做有两个好处:一是使用小数据集可以加快训练和测试循环,使我们能够快速进行实验;二是生成的模型精度可能低于使用完整数据集,但这并不是主要问题,因为可以用从较小数据集中获得的知识对整个数据集进行重新训练。
4.1.2 数据集划分
我们将数据集分为三个部分:训练集、验证集和测试集。虽然原始数据集只有两个部分,但验证集的作用非常重要。在机器学习中,我们通常在训练集上训练模型,需要一个独立的验证集来评估模型的性能。如果模型决策基于验证集,那么模型可能会偏向于在验证集上的表现。为了避免这个问题,我们使用第三个部分(测试集)来进行最终评估。
我们将通过以下步骤划分数据集:
- 读取数据:首先读取原始的 Yelp 评论数据集。
- 分组和抽样:按评分分组,并从每组中抽取子集数据。
- 数据划分:将数据集划分为训练集、验证集和测试集。
4.1.3 数据预处理与清洗
在数据预处理中,我们将文本转换为小写,并去除不必要的标点符号。以下是实现这一过程的代码示例:
import collections
import numpy as np
import pandas as pd
import re
from argparse import Namespace
# 定义命名空间对象,存储各种参数
args = Namespace(
raw_train_dataset_csv="data/yelp/raw_train.csv", # 训练数据集的原始 CSV 文件路径
raw_test_dataset_csv="data/yelp/raw_test.csv", # 测试数据集的原始 CSV 文件路径
proportion_subset_of_train=0.1, # 训练集子集的比例,表示从原始训练集中抽取10%的数据
train_proportion=0.7, # 训练数据在总数据中的比例
val_proportion=0.15, # 验证数据在总数据中的比例
test_proportion=0.15, # 测试数据在总数据中的比例
output_munged_csv="data/yelp/reviews_with_splits_lite.csv", # 处理后的数据保存的 CSV 文件路径
seed=1337 # 随机种子,用于确保数据划分的可重复性
)
# 读取原始训练数据
train_reviews = pd.read_csv(args.raw_train_dataset_csv, header=None, names=['rating', 'review'])
# 将数据按评分分组
by_rating = collections.defaultdict(list)
for _, row in train_reviews.iterrows():
by_rating[row.rating].append(row.to_dict())
# 初始化一个列表用于存储子集数据
review_subset = []
# 按评分排序并遍历每组数据
for _, item_list in sorted(by_rating.items()):
n_total = len(item_list)
n_subset = int(args.proportion_subset_of_train * n_total)
review_subset.extend(item_list[:n_subset])
# 将子集数据转换为 DataFrame
review_subset = pd.DataFrame(review_subset)
# 按评分分组子集数据
by_rating = collections.defaultdict(list)
for _, row in review_subset.iterrows():
by_rating[row.rating].append(row.to_dict())
final_list = []
np.random.seed(args.seed)
for _, item_list in sorted(by_rating.items()):
np.random.shuffle(item_list)
n_total = len(item_list)
n_train = int(args.train_proportion * n_total)
n_val = int(args.val_proportion * n_total)
n_test = int(args.test_proportion * n_total)
for item in item_list[:n_train]:
item['split'] = 'train'
for item in item_list[n_train:n_train+n_val]:
item['split'] = 'val'
for item in item_list[n_train+n_val:n_train+n_val+n_test]:
item['split'] = 'test'
final_list.extend(item_list)
# 创建划分后的数据
final_reviews = pd.DataFrame(final_list)
# 定义文本预处理函数
def preprocess_text(text):
text = text.lower()
text = re.sub(r"([.,!?])", r" \1 ", text)
text = re.sub(r"[^a-zA-Z.,!?]+", r" ", text)
return text
final_reviews.review = final_reviews.review.apply(preprocess_text)
# 将处理后的数据保存到 CSV 文件中
final_reviews.to_csv(args.output_munged_csv, index=False)
通过上述步骤,我们成功地将原始 Yelp 评论数据集进行了清洗和划分,并为后续的模型训练和评估做好了准备。在接下来的部分中,我们将详细介绍如何构建和训练情感分类模型。
4.2 理解 PyTorch 的数据集表示
在这一部分,我们将深入探讨 PyTorch 中的数据集表示方式。我们将介绍如何创建自定义数据集类,以及如何使用 PyTorch 的数据加载器来处理和管理数据集。
4.2.1数据集类的定义
PyTorch 提供了一个数据集类,它是一个抽象的迭代器,用于迭代和管理数据。在使用新数据集时,通常需要从数据集类继承并实现 __getitem__ 和 __len__ 方法。通过实现这两个方法,我们可以定义一个自定义数据集类,使其与 PyTorch 的其他工具(如数据加载器)兼容。
4.2.2 ReviewDataset 类
在这个例子中,我们创建了一个 ReviewDataset 类,用于处理 Yelp 评论数据集。这个类继承自 PyTorch 的 Dataset 类,并实现了 __getitem__ 和 __len__ 方法。以下是具体的实现:
from torch.utils.data import Dataset
import pandas as pd
class ReviewDataset(Dataset):
def __init__(self, review_df, vectorizer):
"""
Args:
review_df (pandas.DataFrame): 数据集的 DataFrame 格式
vectorizer (ReviewVectorizer): 从数据集中实例化的向量化器
"""
self.review_df = review_df
self._vectorizer = vectorizer
self.train_df = self.review_df[self.review_df.split == 'train']
self.train_size = len(self.train_df)
self.val_df = self.review_df[self.review_df.split == 'val']
self.validation_size = len(self.val_df)
self.test_df = self.review_df[self.review_df.split == 'test']
self.test_size = len(self.test_df)
self._lookup_dict = {
'train': (self.train_df, self.train_size),
'val': (self.val_df, self.validation_size),
'test': (self.test_df, self.test_size)
}
self.set_split('train')
@classmethod
def load_dataset_and_make_vectorizer(cls, review_csv):
"""加载数据集并从头开始创建一个新的向量化器
Args:
review_csv (str): 数据集的位置
Returns:
一个 ReviewDataset 的实例
"""
review_df = pd.read_csv(review_csv)
return cls(review_df, ReviewVectorizer.from_dataframe(review_df))
def get_vectorizer(self):
"""返回向量化器"""
return self._vectorizer
def set_split(self, split="train"):
"""选择数据集中的分割部分
Args:
split (str): "train", "val" 或 "test" 之一
"""
self._target_split = split
self._target_df, self._target_size = self._lookup_dict[split]
def __len__(self):
return self._target_size
def __getitem__(self, index):
"""PyTorch 数据集的主要入口方法
Args:
index (int): 数据点的索引
Returns:
一个包含数据点特征 (x_data) 和标签 (y_target) 的字典
"""
row = self._target_df.iloc[index]
review_vector = self._vectorizer.vectorize(row.review)
rating_index = self._vectorizer.rating_vocab.lookup_token(row.rating)
return {'x_data': review_vector, 'y_target': rating_index}
def get_num_batches(self, batch_size):
"""给定批大小,返回数据集中的批数量
Args:
batch_size (int)
Returns:
数据集中的批数量
"""
return len(self) // batch_size
4.2.3 ReviewVectorizer 类
ReviewVectorizer 类用于将文本数据转换为数值向量。神经网络只能处理数值数据,因此必须通过向量化步骤将文本数据转换为向量。以下是 ReviewVectorizer 类的实现:
from collections import Counter
import numpy as np
import string
class ReviewVectorizer(object):
"""协调词汇表并将其投入使用的向量化器"""
def __init__(self, review_vocab, rating_vocab):
"""
Args:
review_vocab (Vocabulary): 将单词映射到整数的词汇表
rating_vocab (Vocabulary): 将类别标签映射到整数的词汇表
"""
self.review_vocab = review_vocab
self.rating_vocab = rating_vocab
def vectorize(self, review):
"""为评论创建一个独热向量
Args:
review (str): 评论文本
Returns:
one_hot (np.ndarray): 独热编码
"""
one_hot = np.zeros(len(self.review_vocab), dtype=np.float32)
for token in review.split(" "):
if token not in string.punctuation:
one_hot[self.review_vocab.lookup_token(token)] = 1
return one_hot
@classmethod
def from_dataframe(cls, review_df, cutoff=25):
"""从数据框中实例化向量化器
Args:
review_df (pandas.DataFrame): 评论数据集
cutoff (int): 基于频率过滤的参数
Returns:
ReviewVectorizer 的实例
"""
review_vocab = Vocabulary(add_unk=True)
rating_vocab = Vocabulary(add_unk=False)
# 添加评级
for rating in sorted(set(review_df.rating)):
rating_vocab.add_token(rating)
# 添加频率大于指定值的常用单词
word_counts = Counter()
for review in review_df.review:
for word in review.split(" "):
if word not in string.punctuation:
word_counts[word] += 1
for word, count in word_counts.items():
if count > cutoff:
review_vocab.add_token(word)
return cls(review_vocab, rating_vocab)
@classmethod
def from_serializable(cls, contents):
"""从可序列化的字典中实例化 ReviewVectorizer
Args:
contents (dict): 可序列化字典
Returns:
ReviewVectorizer 类的实例
"""
review_vocab = Vocabulary.from_serializable(contents['review_vocab'])
rating_vocab = Vocabulary.from_serializable(contents['rating_vocab'])
return cls(review_vocab=review_vocab, rating_vocab=rating_vocab)
def to_serializable(self):
"""创建用于缓存的可序列化字典
Returns:
contents (dict): 可序列化字典
"""
return {'review_vocab': self.review_vocab.to_serializable(),
'rating_vocab': self.rating_vocab.to_serializable()}
4.2.4总结
通过定义 ReviewDataset 和 ReviewVectorizer 类,我们能够创建一个强大且灵活的框架来处理和管理 Yelp 评论数据集。利用 PyTorch 的数据集和数据加载器功能,我们可以轻松地对数据进行预处理、划分并向量化,为后续的神经网络模型训练和评估做好准备。接下来,我们将介绍如何使用这些类进行数据加载和批处理。
4.3 词汇表、向量化器和数据加载器
词汇表、向量化器和 DataLoader 是文本处理和神经网络模型训练过程中不可或缺的组件。在本节中,我们将深入探讨这三个组件,了解它们如何协同工作,将原始文本数据转换为模型可以处理的小批量向量化数据。
4.3.1 词汇表 (Vocabulary)
词汇表类的主要功能是将每个令牌 (tokens) 映射到一个数字版本。在 Python 中,这个映射可以通过两个字典来实现,一个字典将令牌映射到索引,另一个字典将索引映射回令牌。词汇表类不仅管理这种双向映射,还处理一个特殊的 "UNK" 令牌,用于表示未知的令牌。
以下是 Vocabulary 类的实现:
class Vocabulary(object):
"""处理文本并提取词汇表以进行映射的类"""
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
"""
Args:
token_to_idx (dict): 令牌到索引的预先存在的映射
add_unk (bool): 是否添加 UNK 令牌的标志
unk_token (str): 要添加到词汇表中的 UNK 令牌
"""
if token_to_idx is None:
token_to_idx = {}
self._token_to_idx = token_to_idx
self._idx_to_token = {idx: token for token, idx in self._token_to_idx.items()}
self._add_unk = add_unk
self._unk_token = unk_token
self.unk_index = -1
if add_unk:
self.unk_index = self.add_token(unk_token)
def to_serializable(self):
"""返回可序列化的字典"""
return {'token_to_idx': self._token_to_idx,
'add_unk': self._add_unk,
'unk_token': self._unk_token}
@classmethod
def from_serializable(cls, contents):
"""从序列化字典实例化词汇表"""
return cls(**contents)
def add_token(self, token):
"""根据令牌更新映射字典
Args:
token (str): 要添加到词汇表中的项
Returns:
index (int): 对应令牌的整数
"""
if token in self._token_to_idx:
index = self._token_to_idx[token]
else:
index = len(self._token_to_idx)
self._token_to_idx[token] = index
self._idx_to_token[index] = token
return index
def lookup_token(self, token):
"""检索与令牌关联的索引
Args:
token (str): 要查找的令牌
Returns:
index (int): 与令牌对应的索引
Notes:
`unk_index` 需要大于等于0以实现 UNK 功能
"""
if self._add_unk:
return self._token_to_idx.get(token, self.unk_index)
else:
return self._token_to_idx[token]
def lookup_index(self, index):
"""返回与索引关联的令牌
Args:
index (int): 要查找的索引
Returns:
token (str): 与索引对应的令牌
Raises:
KeyError: 如果索引不在词汇表中
"""
if index not in self._idx_to_token:
raise KeyError(f"the index ({index}) is not in the Vocabulary")
return self._idx_to_token[index]
def __str__(self):
return f"<Vocabulary(size={len(self)})>"
def __len__(self):
return len(self._token_to_idx)
4.3.2 向量化器 (Vectorizer)
向量化器类的主要功能是将文本数据点的令牌转换为整数形式的向量。在本例中,我们使用折叠的 one-hot 表示,将评论中的每个单词映射到词汇表中的一个位置,并将该位置的值设为 1。以下是 ReviewVectorizer 类的实现:
from collections import Counter
import numpy as np
import string
class ReviewVectorizer(object):
"""协调词汇表并将其投入使用的向量化器"""
def __init__(self, review_vocab, rating_vocab):
"""
Args:
review_vocab (Vocabulary): 将单词映射到整数的词汇表
rating_vocab (Vocabulary): 将类别标签映射到整数的词汇表
"""
self.review_vocab = review_vocab
self.rating_vocab = rating_vocab
def vectorize(self, review):
"""为评论创建一个独热向量
Args:
review (str): 评论文本
Returns:
one_hot (np.ndarray): 折叠的独热编码
"""
one_hot = np.zeros(len(self.review_vocab), dtype=np.float32)
for token in review.split(" "):
if token not in string.punctuation:
one_hot[self.review_vocab.lookup_token(token)] = 1
return one_hot
@classmethod
def from_dataframe(cls, review_df, cutoff=25):
"""从数据框中实例化向量化器
Args:
review_df (pandas.DataFrame): 评论数据集
cutoff (int): 基于频率过滤的参数
Returns:
ReviewVectorizer 的实例
"""
review_vocab = Vocabulary(add_unk=True)
rating_vocab = Vocabulary(add_unk=False)
# 添加评级
for rating in sorted(set(review_df.rating)):
rating_vocab.add_token(rating)
# 添加频率大于指定值的常用单词
word_counts = Counter()
for review in review_df.review:
for word in review.split(" "):
if word not in string.punctuation:
word_counts[word] += 1
for word, count in word_counts.items():
if count > cutoff:
review_vocab.add_token(word)
return cls(review_vocab, rating_vocab)
@classmethod
def from_serializable(cls, contents):
"""从可序列化字典实例化 ReviewVectorizer
Args:
contents (dict): 可序列化字典
Returns:
ReviewVectorizer 类的实例
"""
review_vocab = Vocabulary.from_serializable(contents['review_vocab'])
rating_vocab = Vocabulary.from_serializable(contents['rating_vocab'])
return cls(review_vocab=review_vocab, rating_vocab=rating_vocab)
def to_serializable(self):
"""创建用于缓存的可序列化字典
Returns:
contents (dict): 可序列化字典
"""
return {'review_vocab': self.review_vocab.to_serializable(),
'rating_vocab': self.rating_vocab.to_serializable()}
4.3.3 数据加载器 (DataLoader)
数据加载器的作用是将向量化的数据点分组成小批量进行处理。PyTorch 提供了一个内置的 DataLoader 类来协调这个过程。以下是 generate_batches 函数的实现,该函数包装了 DataLoader 并用于生成小批量数据:
from torch.utils.data import DataLoader
def generate_batches(dataset, batch_size, shuffle=True, drop_last=True, device="cpu"):
"""
一个包装 PyTorch DataLoader 的生成器函数。它将确保每个张量位于正确的设备位置。
"""
dataloader = DataLoader(dataset=dataset, batch_size=batch_size, shuffle=shuffle, drop_last=drop_last)
for data_dict in dataloader:
out_data_dict = {}
for name, tensor in data_dict.items():
out_data_dict[name] = data_dict[name].to(device)
yield out_data_dict
通过 generate_batches 函数,我们可以轻松地在 CPU 和 GPU 之间切换数据,从而提高训练效率。
4.3.4 总结
通过定义词汇表、向量化器和数据加载器,我们成功地建立了一个完整的管道,将文本数据转换为模型可以处理的小批量向量化数据。这些组件协同工作,使得处理和管理大规模文本数据变得高效而灵活。在接下来的部分中,我们将介绍如何使用这些组件进行模型训练和评估。
4.4 感知器分类器
在这一节中,我们将重新实现我们在本实验开头展示的感知器模型。ReviewClassifier 类继承自 PyTorch 的 nn.Module 类,并创建了一个具有单一输出的线性层。由于这是一个二元分类任务(即判断评论是消极还是积极),这个设置非常合适。最终的非线性函数使用 sigmoid 函数。
4.4.1感知器模型
以下是 ReviewClassifier 类的实现:
import torch.nn as nn
import torch.nn.functional as F
class ReviewClassifier(nn.Module):
""" 一个简单的基于感知器的分类器 """
def __init__(self, num_features):
"""
Args:
num_features (int): 输入特征向量的大小
"""
super(ReviewClassifier, self).__init__()
self.fc1 = nn.Linear(in_features=num_features, out_features=1)
def forward(self, x_in, apply_sigmoid=False):
"""分类器的前向传递
Args:
x_in (torch.Tensor): 输入数据张量,形状应为 (batch, num_features)
apply_sigmoid (bool): 是否应用 sigmoid 激活函数的标志
Returns:
输出张量,形状应为 (batch,)
"""
y_out = self.fc1(x_in).squeeze()
if apply_sigmoid:
y_out = F.sigmoid(y_out)
return y_out
关于 sigmoid 函数的应用
我们对 forward 方法进行了参数化,以允许可选地应用 sigmoid 函数。在二元分类任务中,二元交叉熵损失 (torch.nn.BCELoss) 是最合适的损失函数。虽然 sigmoid 函数可以直接应用,但在使用二元交叉熵损失时会存在数值稳定性问题。为了更稳定地进行训练,PyTorch 提供了 BCEWithLogitsLoss,它结合了 sigmoid 激活和交叉熵损失。因此,在默认情况下,我们不应用 sigmoid 函数,但如果用户希望得到概率值,可以通过设置 apply_sigmoid=True 来应用 sigmoid 函数。
4.5 训练例程
在本节中,我们将详细介绍如何设计和实现一个训练例程,以便有效地训练情感分类模型。训练例程的核心是实例化模型、迭代数据集、计算模型输出、计算损失并根据损失更新模型参数。虽然细节很多,但这些步骤在深度学习开发过程中会逐渐变得习惯。
4.5.1 为训练做准备
首先,我们需要定义训练参数和状态,以便在训练过程中跟踪和管理模型的性能。以下是定义这些参数和状态的代码示例:
from argparse import Namespace
args = Namespace(
# 数据和路径信息
frequency_cutoff=25,
model_state_file='model.pth',
review_csv='data/yelp/reviews_with_splits_lite.csv',
save_dir='model_storage/ch3/yelp/',
vectorizer_file='vectorizer.json',
# 模型超参数
# 训练超参数
batch_size=128,
early_stopping_criteria=5,
learning_rate=0.001,
num_epochs=10,
seed=1337,
# 运行时选项
)
def make_train_state(args):
return {'epoch_index': 0,
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': [],
'test_loss': -1,
'test_acc': -1}
train_state = make_train_state(args)
接下来,我们需要检查是否有可用的 GPU,并将模型移动到合适的设备上:
import torch
if not torch.cuda.is_available():
args.cuda = False
args.device = torch.device("cuda" if args.cuda else "cpu")
然后,我们实例化数据集、向量化器、模型、损失函数和优化器:
import torch.optim as optim
# 数据集和向量化器
dataset = ReviewDataset.load_dataset_and_make_vectorizer(args.review_csv)
vectorizer = dataset.get_vectorizer()
# 模型
classifier = ReviewClassifier(num_features=len(vectorizer.review_vocab))
classifier = classifier.to(args.device)
# 损失函数和优化器
loss_func = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(classifier.parameters(), lr=args.learning_rate)
def compute_accuracy(y_pred, y_target):
y_target = y_target.cpu()
y_pred_indices = (torch.sigmoid(y_pred) > 0.5).cpu().long()
n_correct = torch.eq(y_pred_indices, y_target).sum().item()
return n_correct / len(y_pred_indices) * 100
4.5.2 训练循环
训练循环使用上述初始化的对象来更新模型参数,以便逐渐改进模型性能。训练循环包括两个主要部分:外循环遍历多个 epoch,内循环遍历每个 epoch 中的数据批次。
在训练循环中,我们首先设置训练状态的 epoch 索引,然后设置数据集的分割(首先是“train”,然后是“val”,在每个 epoch 结束时用于测量模型性能,最后是“test”,在模型最终评估时使用)。以下是一个基本的训练循环示例:
from tqdm import tqdm
for epoch_index in tqdm(range(args.num_epochs)):
train_state['epoch_index'] = epoch_index
# 训练数据集迭代
dataset.set_split('train')
batch_generator = generate_batches(dataset, batch_size=args.batch_size, device=args.device)
running_loss = 0.0
running_acc = 0.0
classifier.train()
for batch_index, batch_dict in enumerate(batch_generator):
# 训练步骤
optimizer.zero_grad()
y_pred = classifier(x_in=batch_dict['x_data'].float())
loss = loss_func(y_pred, batch_dict['y_target'].float())
loss.backward()
optimizer.step()
# 计算损失和准确率
loss_batch = loss.item()
running_loss += (loss_batch - running_loss) / (batch_index + 1)
acc_batch = compute_accuracy(y_pred, batch_dict['y_target'])
running_acc += (acc_batch - running_acc) / (batch_index + 1)
train_state['train_loss'].append(running_loss)
train_state['train_acc'].append(running_acc)
# 验证数据集迭代
dataset.set_split('val')
batch_generator = generate_batches(dataset, batch_size=args.batch_size, device=args.device)
running_loss = 0.0
running_acc = 0.0
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
y_pred = classifier(x_in=batch_dict['x_data'].float())
loss = loss_func(y_pred, batch_dict['y_target'].float())
loss_batch = loss.item()
running_loss += (loss_batch - running_loss) / (batch_index + 1)
acc_batch = compute_accuracy(y_pred, batch_dict['y_target'])
running_acc += (acc_batch - running_acc) / (batch_index + 1)
train_state['val_loss'].append(running_loss)
train_state['val_acc'].append(running_acc)
运行结果:
100%|██████████| 10/10 [02:35<00:00, 15.60s/it]
这里我们测试时把num_epochs改为10,num_epochs=100时需要跑大约半个小时
外部循环与内部循环的细节
外部循环
外部循环控制整个训练过程的迭代次数,每次迭代称为一个 epoch。在每个 epoch 中,我们首先设置训练状态的 epoch_index,然后将数据集的分割设置为训练集,并创建一个批次生成器。训练模式下的模型参数是可变的,这也支持正则化机制如 dropout。
内部循环
内部循环遍历每个批次的数据,并执行以下步骤:
- 重置梯度:使用
optimizer.zero_grad()方法重置优化器的梯度。 - 计算输出:从模型中计算输出。
- 计算损失:使用损失函数计算模型输出与真实标签之间的损失。
- 反向传播:对损失对象调用
loss.backward()方法,计算梯度并传播到每个参数。 - 更新参数:使用优化器执行参数更新。
每个批次迭代中,还计算损失和准确率,并更新运行损失和运行准确率变量。
验证阶段
在每个 epoch 结束后,我们对验证数据集进行迭代,计算模型的损失和准确率。与训练阶段不同,验证阶段不会更新模型参数。我们调用 classifier.eval() 方法,使模型进入评估模式,参数不可变且不可丢失。
4.5.3总结
通过定义训练参数和状态、初始化训练组件以及实现训练循环,我们成功地创建了一个完整的训练例程,用于训练情感分类模型。这个训练例程可以用于各种深度学习任务,并且可以根据具体需求进行调整和优化。在接下来的部分中,我们将进一步探讨如何优化和评估模型,以提升其性能。
4.6 评估、推断和检查
在训练出一个模型后,接下来的步骤包括评估它在未见过的数据上的表现、使用它对新数据进行预测,以及检查模型的权重以了解它学到了什么。在本节中,我们将展示所有三个步骤,帮助您全面理解模型的性能和行为。
4.6.1 在测试数据上进行评估
为了确保模型的泛化能力,我们需要在未见过的测试数据上评估其表现。测试集应该尽量少使用,因为频繁使用可能会导致模型过拟合测试数据,从而降低测试集作为性能度量的可靠性。以下是评估测试集的代码示例:
# 设置数据集的分割为测试集
dataset.set_split('test')
# 生成批量数据的生成器
batch_generator = generate_batches(dataset, batch_size=args.batch_size, device=args.device)
# 初始化运行中的损失和准确率
running_loss = 0.0
running_acc = 0.0
# 将分类器设置为评估模式
classifier.eval()
# 遍历每个批次
for batch_index, batch_dict in enumerate(batch_generator):
# 计算输出
y_pred = classifier(x_in=batch_dict['x_data'].float())
# 计算损失
loss = loss_func(y_pred, batch_dict['y_target'].float())
loss_batch = loss.item()
running_loss += (loss_batch - running_loss) / (batch_index + 1)
# 计算准确率
acc_batch = compute_accuracy(y_pred, batch_dict['y_target'])
running_acc += (acc_batch - running_acc) / (batch_index + 1)
# 将运行中的平均损失和准确率赋值给训练状态
train_state['test_loss'] = running_loss
train_state['test_acc'] = running_acc
# 打印测试集上的损失值和准确率
print("Test loss: {:.3f}".format(train_state['test_loss']))
print("Test Accuracy: {:.2f}".format(train_state['test_acc']))
输出结果:Test loss: 0.227
Test Accuracy: 91.01
在这个过程中,我们将数据集的分割设置为测试集,生成批量数据的生成器,并遍历每个批次进行前向传播、计算损失和准确率。最终,我们打印测试集上的损失值和准确率。
4.6.2 推断和分类新数据点
评估模型的另一种方法是对新数据进行推断,以直观地了解模型的预测效果。这可以帮助我们理解模型在真实应用中的表现。以下是对新评论进行预测的代码示例:
def predict_rating(review, classifier, vectorizer, decision_threshold=0.5):
"""预测评论的评分
Args:
review (str): 评论的文本
classifier (ReviewClassifier): 训练好的模型
vectorizer (ReviewVectorizer): 相应的向量化工具
decision_threshold (float): 决定分类的阈值
"""
# 预处理评论文本
review = preprocess_text(review)
# 将预处理后的评论文本向量化
vectorized_review = torch.tensor(vectorizer.vectorize(review))
# 使用分类器预测结果
result = classifier(vectorized_review.view(1, -1))
# 将结果应用sigmoid函数,得到概率值
probability_value = torch.sigmoid(result).item()
# 根据概率值和决策阈值决定类别索引
index = 1 if probability_value >= decision_threshold else 0
# 返回对应类别的标签
return vectorizer.rating_vocab.lookup_index(index)
# 测试评论
test_review = "this is a pretty awesome book"
# 预测评论的评分
prediction = predict_rating(test_review, classifier, vectorizer)
# 打印测试评论和预测结果
print("{} -> {}".format(test_review, prediction))
输出结果:
this is a pretty awesome book -> 2
/opt/conda/lib/python3.6/site-packages/torch/nn/functional.py:1332: UserWarning: nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.
warnings.warn("nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.")
在这个示例中,我们首先对评论文本进行预处理,然后将其向量化。接着,使用分类器预测结果,并将预测结果应用 sigmoid 函数得到概率值。根据概率值和决策阈值决定评论的类别,最后返回对应类别的标签。这一过程可以帮助我们验证模型在真实数据上的预测效果。
4.6.3 检查模型权重
了解模型在训练完成后的表现,另一种方法是检查权重,并对权重进行定性判断。使用感知器和折叠的 one-hot 编码,这种方法相对简单,因为每个模型权重直接对应词汇表中的单词。以下是打印分类器权重对应单词的代码示例:
# 获取分类器第一层的权重,并进行分离(不计算梯度)
fc1_weights = classifier.fc1.weight.detach()[0]
# 对权重进行排序,按降序排列
_, indices = torch.sort(fc1_weights, dim=0, descending=True)
indices = indices.numpy().tolist()
# 打印最重要的20个正面词语
print("Influential words in Positive Reviews:")
print("--------------------------------------")
for i in range(20):
print(vectorizer.review_vocab.lookup_index(indices[i]))
# 将索引列表反转,使其按升序排列
indices.reverse()
# 打印最重要的20个负面词语
print("Influential words in Negative Reviews:")
print("--------------------------------------")
for i in range(20):
print(vectorizer.review_vocab.lookup_index(indices[i]))
输出结果:
Influential words in Positive Reviews:
--------------------------------------
delicious
amazing
excellent
great
fantastic
awesome
perfect
vegas
love
yummy
pleasantly
best
solid
yum
ngreat
outstanding
superb
helpful
reasonable
definitely
//
Influential words in Negative Reviews:
--------------------------------------
worst
mediocre
horrible
bland
terrible
rude
awful
overpriced
meh
disgusting
disappointing
tasteless
poor
dirty
not
elsewhere
ok
unprofessional
poorly
gross
在这个示例中,我们获取分类器第一层的权重,并对其进行排序。然后,我们打印出前20个正面和负面的词语。通过这些词语,我们可以直观地了解哪些词对模型的决策影响最大。这不仅有助于验证模型的合理性,还能帮助我们发现潜在的问题或改进点。
4.6.4总结
通过评估模型在测试数据上的表现、对新数据进行推断以及检查模型的权重,我们可以全面了解模型的性能和行为。这些步骤不仅帮助我们验证模型的有效性,还为我们提供了进一步优化和改进模型的依据。通过这些技术,我们可以更好地利用训练好的模型,并根据需要进行调整和优化。
通过以上示例,我们希望您能更好地理解如何评估、推断和检查情感分类模型。这些技能在机器学习和深度学习项目中非常重要,有助于确保模型的可靠性和有效性。
五、总结
在当今的深度学习领域,神经网络已经成为解决各种复杂问题的强大工具。通过本文的实际案例,我们从头到尾地构建了一个情感分类器,从数据预处理、模型构建到训练与评估,涵盖了深度学习项目的关键步骤。
5.1关键点回顾
-
神经网络基础:
- 介绍了感知器作为神经网络最基本的单元,包括其组成部分和工作原理。
- 详细讲解了几种常见的激活函数,如Sigmoid、Tanh和ReLU,及其各自的优缺点。
-
损失函数和优化器:
- 讨论了不同类型的损失函数,包括均方误差损失(MSE)和交叉熵损失(Cross-Entropy Loss)。
- 介绍了几种常见的优化器,如随机梯度下降(SGD)和Adam,并展示了如何在PyTorch中实现这些优化器。
-
构建和训练模型:
- 使用PyTorch构建了一个简单的感知器分类器,并通过数据集和数据加载器管理数据。
- 详细描述了训练循环的实现,包括前向传播、损失计算、反向传播和参数更新等步骤。
-
评估、推断和检查模型:
- 讲解了如何在测试数据上评估模型性能,并对新数据进行推断以验证模型的预测效果。
- 介绍了如何检查模型权重,理解模型学习到的特征和模式。
5.2 实际应用与扩展
通过本案例的学习,您应该已经掌握了使用PyTorch进行情感分类的基本方法。以下是一些未来可能的扩展方向:
-
模型改进:
- 通过增加更多的层或使用更复杂的网络结构(如卷积神经网络或递归神经网络)来提升模型性能。
- 尝试不同的激活函数、损失函数和优化器,找到最适合您数据集的组合。
-
数据扩展:
- 使用更多的数据或更复杂的数据预处理技术(如词嵌入或TF-IDF)来增强模型的泛化能力。
- 结合外部数据源(如情感词典或情感分析API),进一步提升模型的准确性。
-
应用场景:
- 将模型应用于其他文本分类任务,如垃圾邮件检测、产品评论分类等。
- 集成到实际应用中,如聊天机器人、推荐系统等,为用户提供智能化的服务。
5.3 结语
深度学习和自然语言处理是当前最具前景的技术之一,通过掌握这些技术,您可以解决许多现实生活中的复杂问题。希望本文的详细讲解能够帮助您更好地理解和应用神经网络,开启您的深度学习之旅。无论是个人项目还是实际应用,这些技能都将为您的职业生涯带来巨大的价值。
继续探索,持续学习,不断创新,您将在深度学习领域取得更大的成就。祝您在未来的项目中一切顺利,取得卓越的成果!















 5442
5442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









