







论文题目:A dynamic multi-objective optimization evolutionary algorithm with adaptive boosting
一种自适应提升的动态多目标优化进化算法(Hu Peng a,b,∗, Jianpeng Xiong a, Chen Pi a, Xinyu Zhou c, Zhijian Wu d)IEEE Swarm and Evolutionary Computation 89 (2024) 101621
刚开始学习多目标优化算法,不作商业用途,如果有不正确的地方请指正!
个人总结:
很新奇的静态优化方法选择策略,在第一次静态优化时,分3个种群试验他的性能来选择合适的静态优化器,具体效果可能还是需要写出来再看看.
环境变化以后如果非支配占总体少于70%就采用移动支配解向非支配解靠近并进行交叉变异
正常环境响应就是随机把种群分成3分分别采用1.中心点预测(+一点高斯扰动)和2.使用记忆方法判断环境的相似程度以后采用预测方法3.使用遗传算子、多项式突变和高斯突变来保证种群的多样性.再根据静态优化时个体移动的距离来更新3个方法的使用的权重.
很牛逼的创新点,因为方法都不难,为什么我脑袋空空.
摘要
- 动态多目标优化问题中平衡收敛性和多样性是具有挑战性的,因为单一的策略只能解决特定类型的DMOP。
- 针对这一问题,本文提出了一种自适应提升的动态多目标优化进化算法( AB-DMOEA )。在AB - DMOEA中,自适应增强响应机制将增加高性能策略的权重,包括基于预测、记忆和多样性的策略.
- 此外,占优解强化策略对种群进行优化,以保证上述机制的有效运行。在静态优化中,静态优化提升机制针对当前问题选择合适的静态多目标优化器
引言
环境变化响应机制
环境变化响应机制是DMOEA的关键部分,通常分为基于多样性的策略、基于记忆的策略、基于预测的机制等。
静态多目标优化器
对于静态多目标优化器,大多数DMOEAs直接采用或略微改进现有的MOEAs,如使用基于NSGA - II [ 18 ]、MOEA / D [ 19 ]和基于正则化模型的多目标分布估计算法( RMMEDA ) 等框架
其中MOEA / D在收敛性较好,NSGA -Ⅱ分布较为均匀,而RM - MEDA的性能较为均衡。
本文提出的想法
提出了一种自适应增强的动态多目标优化进化算法AB - DMOEA。当环境发生变化时,采用自适应助推响应机制,并将3种常用的方法集成到该机制中,从而实现合适策略的自适应助推,以解决各种问题。
- 自适应增强响应机制计算各种策略的实时静态优化距离,增强较短值对应的策略优化种群的权重。
- 为了保证自适应增强响应机制的有效性,支配解增强策略预先检测非支配解的比例。如果该比例小于占优解的比例,则该策略移动占优解并执行变异进行优化。
- 静态优化提升机制根据非支配解的权重和第一个变化响应期间总种群的最大扩展距离( Maximum Extension Distance,MED )值来选择最优的静态多目标优化器。
背景及相关工作
A.DMOP基础
B.动态多目标优化算法
C.相关工作
1环境变化检测
随机再评价
在每一代开始时随机重新评估种群比例是一种早期和广泛使用的检测DMOPs变化的方法。它需要在种群的每一代中选择特定的或随机的个体进行测试,并通过pre和物镜后型函数值来确定环境是否发生了变化。
基于传感器的检测
基于传感器的检测是一种更为复杂和精确的方法,它使用一些特殊的检测器,就像配置良好的传感器一样,来监测环境的变化。基于传感器的检测是一种比随机再评估更复杂、更精确的方法,但探测器存在监测覆盖范围有限或可能过度反应的问题。
基于种群的检测
基于种群的检测是一种使用统计方法检验当代人和前代人之间的显著差异来检测环境变化的方法。
说了那么多现在看下来还是用的10-20%的个体检测再评估方法
2环境响应机制
介绍了现阶段的各论文里的算法
3静态多目标优化器
NSGA-II、MOEA/D、RM-MEDA等传统MOEAs可以在下一次环境变化前快速跟踪PSt PFt,被广泛用作静态多目标优化器。
D动机
DMOP以其复杂性和可变性而闻名。PSt∕PFt 可能会受到剧烈的、非周期性的、高频的和其他环境变化的影响,这给 DMOEA 带来了巨大的挑战,而单个响应机制仅求解特定类型的 DMOP。
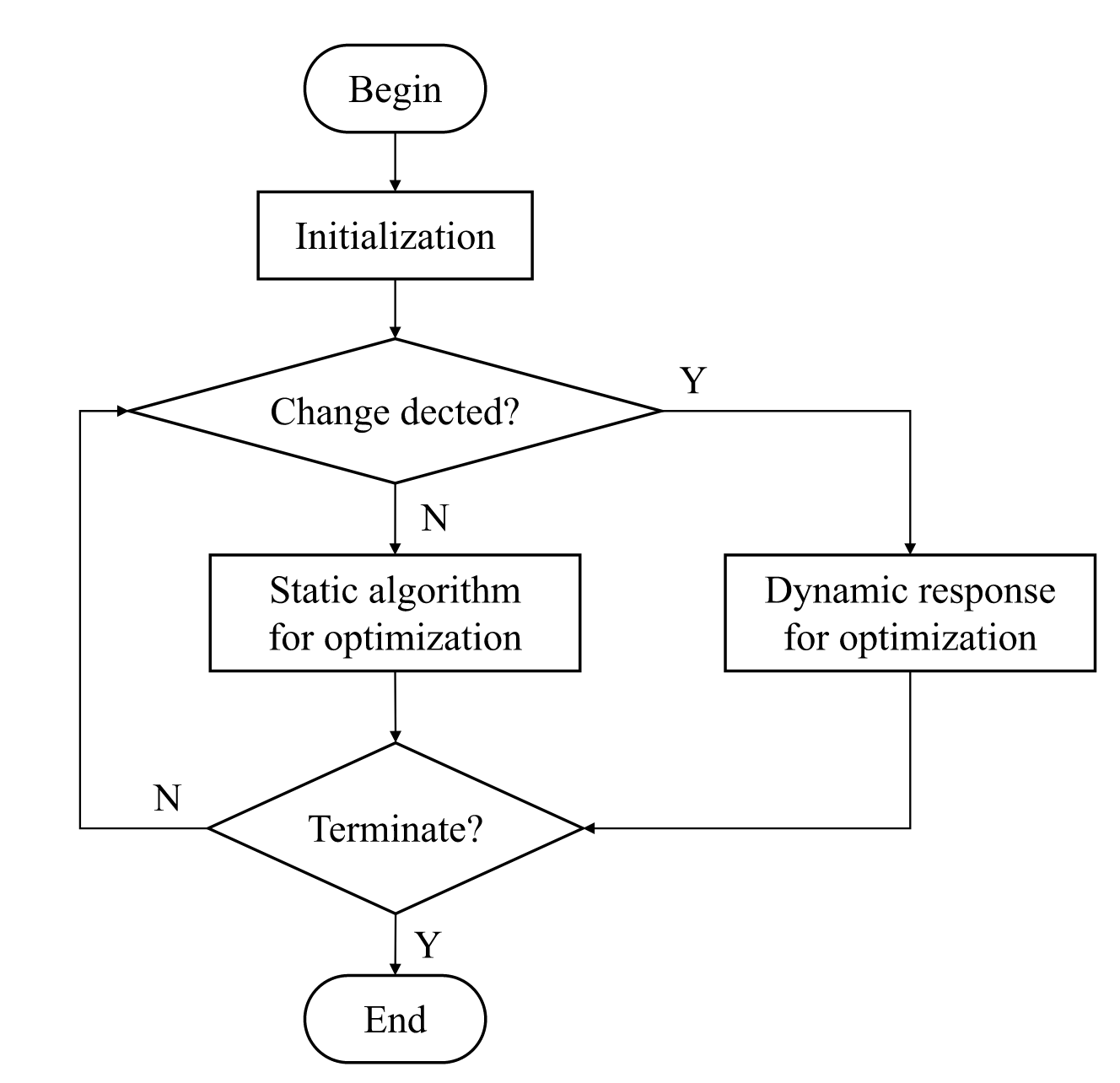
算法具体细节
A.AB-DMOEA算法框架。
初始的静态多目标优化器是MOEA/D-DE
如果非支配解决方案的数量小于 ⌊0.7N⌋,则将使用主导解决方案提升策略来优化种群。当环境第一次发生变化时,静态优化提升机制会选择适应当前环境的静态多目标优化器。
算法为代码

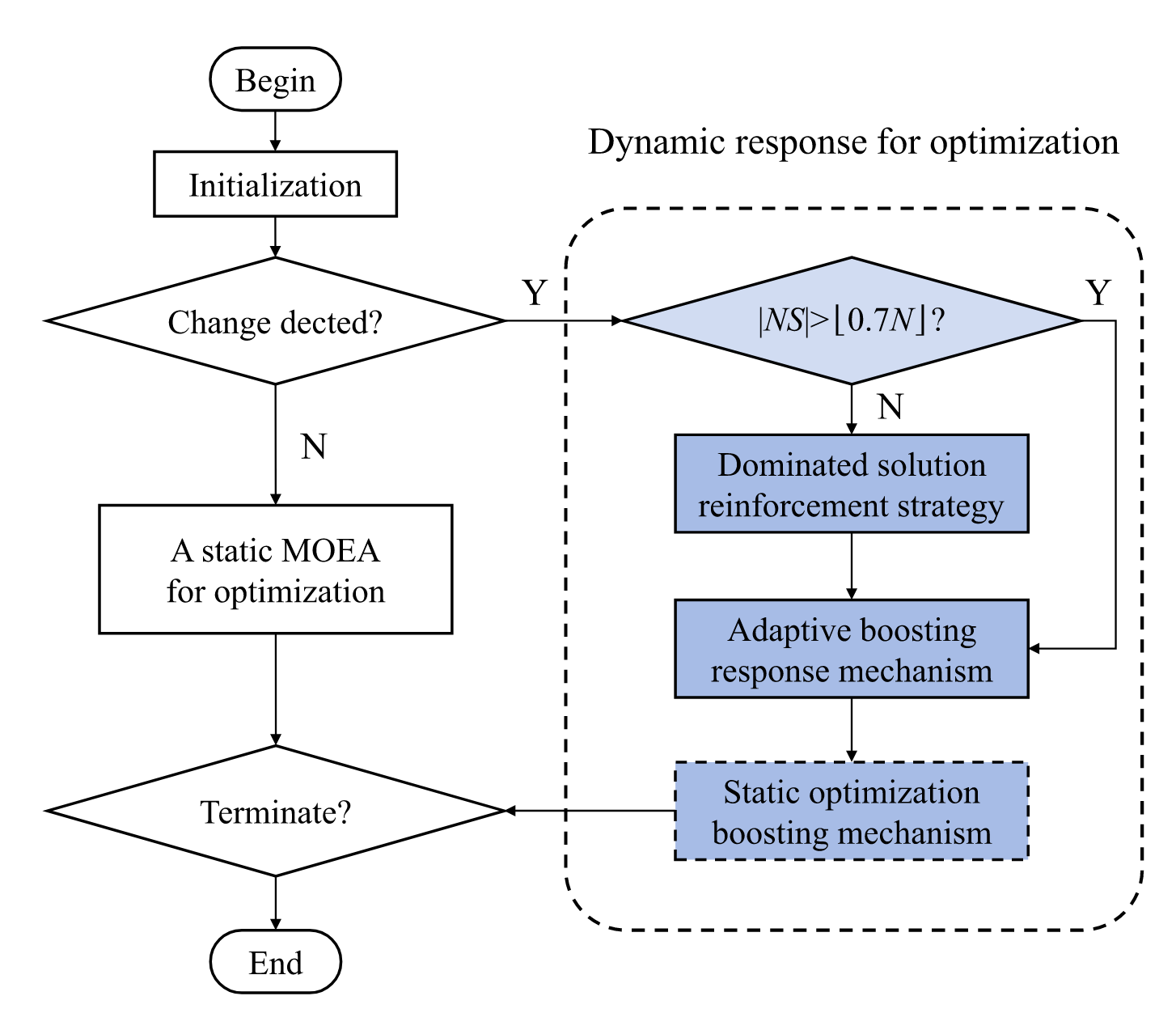
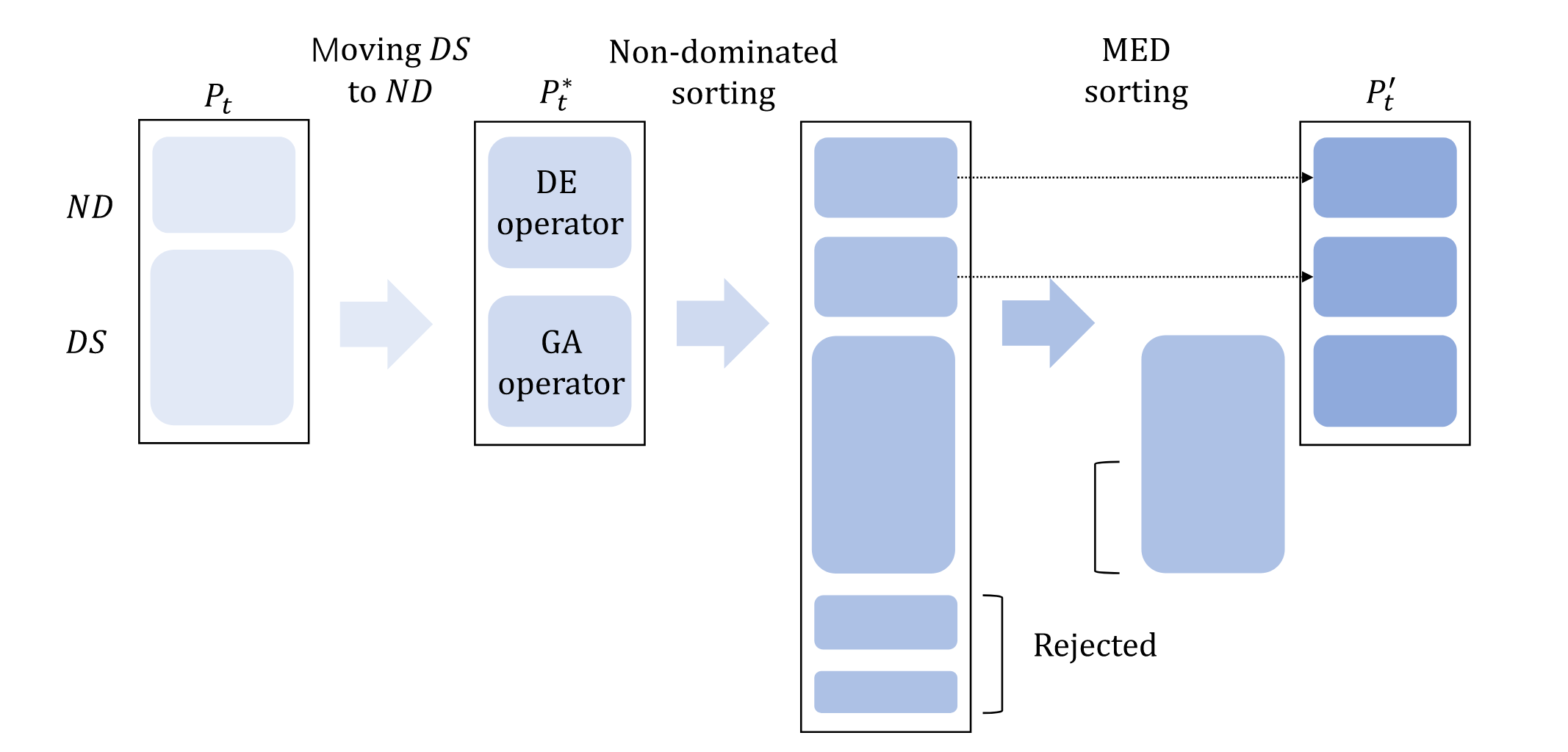
B.支配解强化策略
当种群中的支配解大于种群数量的70%时候就使用支配解强化策略
- 对种群进行非支配排序得到支配解和非支配解,并计算出他们的中心

- 并对支配解进行更新
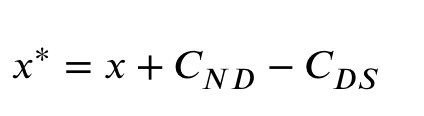
- 然后按照数量对种群进行对半分,一半个体采用DE算子一半个体采用GA算子并对他们进行非支配排序
- 筛选个体,如果支配层级相同,则根据med值挑选
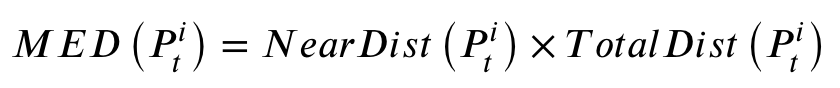
流程图如下:
C.自适应助推响应机制
单一的应对策略可能只对某一类型的问题有效,而使用多种策略可能偶尔会因为一种策略的失败而导致种群的进化方向错误。为了跟踪随时间变化的PSt∕PFt,该文设计了一种自适应助推响应机制,该机制可以根据其历史性能不断增加最有效策略的权重。
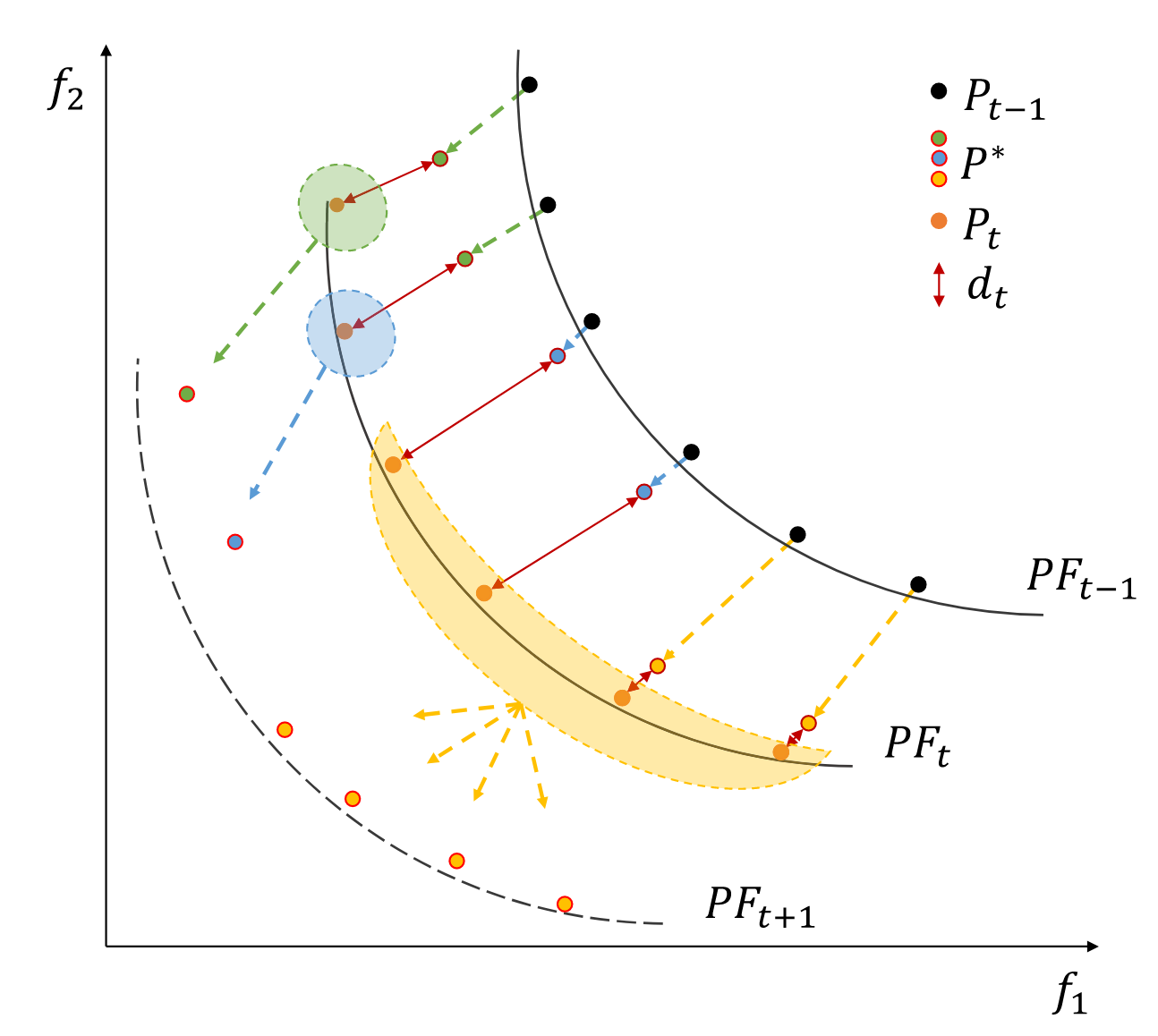
PF 更改过程的示例。绿色、蓝色和黄色点是通过三种不同策略更新的子种群,而橙色点是通过静态优化更新的种群。红色实线表示静态优化距离。
3.1预测策略
作者认为单纯的线性预测并不能很好的处理复杂的问题所以提出了基于改进的预测策略
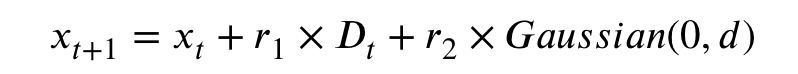
r=0.5,1,1.5 d为Dt的长度/种群个数,r2为0,1
3.2记忆策略
每一代种群,存储下他的种群中心点Ac和目标值的平均取值Af.当环境发生的时候,比较存档当中的Af.如果所有目标的平均值相差少于0.5𝜀,则认为环境变化前后具有高相似性,如果大1.5𝜀则认为环境进行了大幅度变化.
如果环境变化的程度不高两个环境的相似性很高将使用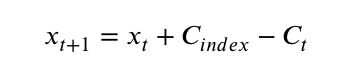 方法来创建新个体,如果环境不相思,则采取基于改进的预测策略产生新的个体
方法来创建新个体,如果环境不相思,则采取基于改进的预测策略产生新的个体
3.3多样性策略
为了提高种群的收敛性和多样性,基于预测和基于记忆的方法存在局限性,可能导致算法落入局部最优。为了在不增加复杂性的情况下保持多样性,引入了三种具有不同特征的有效突变算子:遗传算子、多项式突变和高斯突变。就是从3者里随机选择一个
3.4静态优化提升机制
AB-DMOEA选择在第一次环境变化时表现最好的SMOA。
当前种群被随机分为三个大小相等的亚种群,并由三个常用且有用的 SMOA(MOEA/D-DE、RM-MEDA 和 NSGA-II-DE)独立优化。然后,提出一种评分机制来评估静态优化器的收敛性和多样性。评分机制包括 MED 比例评分 MEDScore 和非支配解决方案比例评分 NDScore。
MEDScore是指单个SMOA的MED占所有MED的比例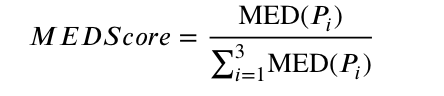
NDScore 是指所有合并总体中每个 SMOA 的非主导解决方案的比例。需要记录每个个体使用的SMOA,然后合并三个群体,并进行快速的非显性排序,得到非显性解SND。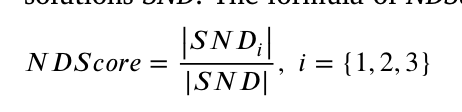
最后,将MEDScore和NDScore相加得到总分,最高分作为以下静态优化器。它们分别代表了SMOA的趋同性和多样性,通过这种机制,可以在短时间内快速选择在两者中表现良好的SMOA。

















 219
219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









