






意图
使得应用可以通过用户,程序,自动化测试或批处理脚本来驱动,独立于最终的运行环境及数据库进行开发和测试。
当外部事件到达端口,适配器把它们转化成过程调用或者消息,然后传递给应用。应用对输入设备一无所知。应用通过端口把要传递出去的消息传给适配器,适配器用它们生成接收端需要的信号。从语义上来说,应用跟它周围的适配器有着良好的互动,而对适配器外部的一切却一无所知。

动机
业务逻辑到用户界面的代码渗透是开发中存在的一个令人头痛的问题。代码渗透导致的三个问题:
- 系统无法方便地进行自动化测试,因为部分逻辑依赖界面元素,比如输入框的长度或按钮的位置
- 无法把一个面向用户的系统移植到基于批处理的系统
- 程序之间的相互驱动变得很困难,甚至不可能
很多组织不断重试着一些解决方案,他们在架构里增加一个新的层,并承诺不会有业务逻辑被放到新的层里。尽管无法追踪他们是否违背诺言,但若干年后,组织发现新的层里还是掺杂了业务逻辑,于是旧问题又浮出水面。
现在假设应用提供的每一个功能都有相应的API,那么QA就可以通过自动化测试来监测新改的代码是否会破坏已有的功能。业务专家们在GUI出来之前就可以创建自动化测试用例,程序员们就会知道他们写的代码是否正确。应用可以用"headless"模式部署,其它程序通过调用API的方式使用它提供的功能。这种方式使得复杂系统的设计变得容易,面向业务的应用之间不需要人的介入就可以互相调用。最后,自动化回归测试检测到出现问题的地方,并加以修复,保证业务逻辑不会进入到呈现层。
另一个地方存在类似的问题,通常被称为应用的"另一边",也就是应用绑定外部数据库或其它服务的地方。当数据库宕机或者正在更换数据库,依赖数据库的程序就无法正常工作。这会导致响应延迟,甚至造成人们之间的不愉快。
这两个问题之间没有明显的联系,但它们之间看起来是对称的。
方案剖析
造成用户端跟服务端问题的根源是同一个,那就是在设计和实现过程中出现的业务逻辑混淆,以及与外部实体之间的交互关系。我们要关注的非对称性不是应用的"左边"和"右边",而是它的"内部"和"外部"。换句话说,就是该属于"内部"的代码就不要泄露到"外部"去。
抛开左右或者上下的非对称性不说,我们可以看到应用是通过"端口"跟外部进行交互的。"端口"让人联想到操作系统的端口,任何符合协议的设备都可以被插到相应的端口上。就像那些电子设备上的端口,任何符合电子协议的设备都可以插在上面。
定义端口协议是为了能在两个设备之间进行通信。对应用来说,API就是协议。对于每一个外部设备,都有对应的适配器把API转换成自己所需要的信号,或者相反。GUI就是一个很好的例子,它就是把用户操作映射到端口API的适配器。还有其它的例子,比如自动测试套件,批处理驱动器,以及任何需要跨应用程序交互的代码。
在应用的另一面,应用通过与外部实体交互得到数据。这里用到的协议一般就是指数据库协议。从应用角度来看,把SQL数据库迁移到普通的文件或者其它类型的数据库,API仍然保持不变。所以对于同一个端口,又多了一些额外的适配器,包括SQL适配器,文件适配器,还有更重要的mock数据库,它可以是驻存在内存里的数据库,不一定是真实的数据库。
很多应用都只有两个端口:用户端跟数据库端。这种情况看起来是对称的,很自然地就会用单维度多层次的架构来构建它。
这种架构有两个问题。第一,也是最糟糕的一点,人们很容易跨越层间的边界,把业务逻辑渗透到其它层中去,这就引起了之前说的问题。第二,有的应用可能不止需要两个端口,所以不能用单维度架构来构建。
六边形架构,或者说端口与适配器模式解决了这些问题。它着重解决对称性问题,处在内部的应用通过端口与外部进行交互,而外部的实体可以用一对一的方式来处理。
六边形架构强调以下两点:
- "内外"的不对称性以及端口的特点,避免单维度多层次架构存在的问题
- 可以定义不同数量的端口,2个,3个或者4个(在我看来4个最常见)
当然,这里说的六边形不是真的只能有六个边, 人们可以根据需要加入更多的端口和适配器,而不局限于单维度多层次的架构。"六边形架构"只是视觉上的一种叫法。
"端口与适配器"关注整体架构的"目的性",一个端口对应一个有目的交互。但一个端口一般会有多个适配器,因为会存在多种技术需要连接到端口上。也许会是无人应答机,语音留言机,按键电话,用户图形界面,测试套件,批处理驱动器,HTTP接口,程序之间的接口,mock的数据库,或者真实的数据库。
从应用层面来看,还是有点像左右的非对称结构。不管怎么样,这个模式的目的是要把注意力聚焦在内外非对称性上,让外部的实体在应用看来都是一样的。
结构

图2中的应用有两个端口,每个端口对应几个适配器。这两个端口分别用于应用控制和数据获取。这个应用可以被自动化测试,系统层面的回归测试,用户,远程HTTP应用或者另外一个本地应用驱动。在数据方面,通过配置使用外部的数据库,可以是Oracle的内存数据库,mock的数据库,或者测试数据库或生产数据库。应用的功能说明是依据六边形内部的接口来编写的,而不是依据外部可能用到的任何一种技术。
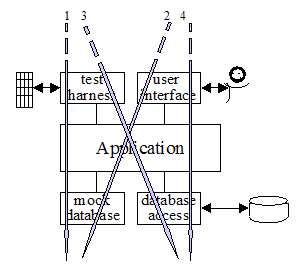
图3是一个三层架构的应用。为简单起见,每个端口只给出两个适配器。这个图是想说明架构的顶层跟底层可以适用多少个适配器,以及这些适配器是如何按照一定顺序来开发的。带有数字的箭头告诉我们一个团队是如何按照一定顺序来开发和使用应用的:
- 用测试套件来驱动应用,用mock的内存数据库模拟真实数据库。
- 给应用增加GUI,但仍然使用mock数据库。
- 在集成测试的时候使用自动化测试脚本,数据库换成包含测试数据的真实数据库。
- 用户在生产环境使用应用,数据库也是真实的。
代码示例
FIT的文档给出了一个简单的例子来说明端口与适配器模式,它是一个计算折扣价格的应用:
discount(amount) = amount * rate(amount);
在这个应用里,amount来自用户的输入,而rate来自数据库,所以需要两个端口。我们一步一步来实现它:先用测试代码跟rate常量来测试,然后再使用GUI跟mock数据库。
感谢来自IHC的Gyan Sharma提供这个示例的代码。
第一步:用常量模拟mock数据库
首先我们创建测试用例,并用HTML表格列出来:
| TestDiscounter | |
| amount | discount() |
| 100 | 5 |
| 200 | 10 |
在实现时列名会变成类名或函数名。有了测试数据,接下来开始创建用户端适配器ColumnFixture:
import fit.ColumnFixture;
public class TestDiscounter extends ColumnFixture
{
private Discounter app = new Discounter();
public double amount;
public double discount()
{ return app.discount(amount); }
}现在可以从命令行运行测试:
set FIT_HOME=/FIT/FitLibraryForFit15Feb2005
java -cp %FIT_HOME%/lib/javaFit1.1b.jar;%FIT_HOME%/dist/fitLibraryForFit.jar;src;bin
fit.FileRunner test/Discounter.html TestDiscount_Output.html
FIT会生成一个测试报告,报告会用不同颜色标识成功或失败的用例。
截止到这一步,代码可以被提交到代码库,然后持续集成系统或自动化测试系统可以对它进行自动化测试了。
第二步:加入用户界面
因为创建用户界面的代码比较长,这里只列出关键的片段,其它的要靠你们自己去完成。
...
Discounter app = new Discounter();
public void actionPerformed(ActionEvent event)
{
...
String amountStr = text1.getText();
double amount = Double.parseDouble(amountStr);
discount = app.discount(amount));
text3.setText( "" + discount );
...到了这一步,应用既可以被演示也可以被回归测试,用户端的两个适配器都可以正常运行。
第三步:mock数据库
为了让数据库端的适配器可以被灵活调换,我们为仓库生成了一个接口,还有一个可以创建mock数据库或真实数据库的仓库工厂,以及驻存在内存里的数据库。
public interface RateRepository
{
double getRate(double amount);
}
public class RepositoryFactory
{
public RepositoryFactory() { super(); }
public static RateRepository getMockRateRepository()
{
return new MockRateRepository();
}
}
public class MockRateRepository implements RateRepository
{
public double getRate(double amount)
{
if(amount <= 100) return 0.01;
if(amount <= 1000) return 0.02;
return 0.05;
}
}要把这个适配器加到应用里,需要对应用做一些修改。同时,需要用户端适配器把仓库接口作为应用的构造函数传递给应用。代码如下:
import repository.RepositoryFactory;
import repository.RateRepository;
public class Discounter
{
private RateRepository rateRepository;
public Discounter(RateRepository r)
{
super();
rateRepository = r;
}
public double discount(double amount)
{
double rate = rateRepository.getRate( amount );
return amount * rate;
}
}
import app.Discounter;
import fit.ColumnFixture;
public class TestDiscounter extends ColumnFixture
{
private Discounter app =
new Discounter(RepositoryFactory.getMockRateRepository());
public double amount;
public double discount()
{
return app.discount( amount );
}
}这个例子是六边形架构最简单示例。另一个用Ruby和Rack实现的例子可以看这里https://github.com/totheralistair/SmallerWebHexagon。
左右非对称性
端口与适配器模式强调端口之间的相似性。从架构层面来说,这有它的优点。在实现的时候一般有两种风格,我们称之为"主动"和"从动",或者叫驱动适配器跟被驱动适配器。
细心的读者可能已经注意到,在上面的例子中,FIT被用在左边的端口上,而mock的东西在右边。在三层架构中,FIT在最顶层,mock在最底层。
这个跟"主动者"和"从动者"的用例有点像,"主动者"驱动应用,"从动者"获取结果或发出通知。这两者之间的区别在于是谁触发了会话,或者谁在会话中起主导作用。
FIT就是"主动者",这个框架就是被设计用来通过脚本来驱动应用的。Mock数据库就是"从动者",数据库被设计用来响应来自应用的查询或记录变更事件的。
根据系统用例,我们把"主动"的端口和适配器放在了六边形的左边,而"从动"的端口和适配器放在了六边形的右边。
记住它们之间的关系以及它们的实现方式是很有用的,但前提是要用在六边形架构中。端口与适配器模式最大的好处就是可以让应用可以完全独立地运行。
用例与应用边界
六边形架构模式对用例编写也有强化作用。
人们在编写用例时都会犯一个错,就是把端口外边的技术细节包含在用例里。这样的用例在我们的行业里早就臭名昭著,它们易读性差,乏味,脆弱,难于维护。
在理解了端口与适配器模式之后,我们知道,编写用例应该以应用的边界为准。用例要明确应用能够支持的功能和事件,而不用关心外部的技术是怎么样的。用例应该简洁,可读性要强,易于维护,并且稳定。
需要多少个端口?
如何使用端口取决于个人的想法。一种极端的情况,每个用例都被赋予一个端口,这样应用里就会有成百上千的端口。另一种情况是,把主动端口跟从动端口分别合并起来,这样就只剩两个端口,一个在左边,一个在右边。
这两种情况都不是最理想的。让我们看看一些大家所熟知的用例。
天气预报系统有四个端口:天气预报源,管理员,订阅者,订阅者数据库。咖啡机控制器有四个端口:用户,包含菜单和价格的数据库,调配师,硬币盒。医药系统有三个端口:护士,处方数据库,药剂师。
这些用例告诉我们,不必拘泥于端口的数量。我一般倾向于选择更少的端口,两个,三个或者四个。

图4展示了一个包含四个端口和若干适配器的应用。这个应用是一个报警系统,它从国家天气服务中心获取地震,龙卷风,火灾和洪水的预警,然后通过电话或语音留言通知人们。当时我们在讨论这个系统接口的时候,我们遵循的是技术与业务目标相关联的原则。一个接口用于接收来自预报源的数据,一个用来向语言留言机发送通知,一个GUI管理界面,以及一个获取订阅者数据的数据库接口。
人们想往系统里增加一些接口,比如一个来自天气服务中心的http接口,一个到订阅者的邮件接口。他们还要考虑怎么让应用套件满足客户定制化需求。他们担心会陷入维护和测试的恶梦,因为他们要为不同的定制需求开发不同的版本。
后来他们调整了系统接口的设计,新的架构面向的是业务目标,而不是具体的技术,而且他们把所有的具体技术换成了适配器。这样,他们很快就把http和邮件接口加入到了系统中。他们把应用部署成"headless"模式,并添加了一个适配器,可以按需通过API调用连接到子应用上。最后,因为应用的独立运行能力和各种适配器的存在,他们就可以使用单独的自动化脚本进行回归测试了。















 6129
6129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









