






代码下载地址:https://github.com/tazhigang/big-data-github.git
一、前期准备
- 由于本案例是在案例六的基础上做的优化,所以需求及数据输入输出请参考案例六;初次之外需要拷贝pd.txt文件在本地电脑J盘的根目录下以做参考
- 本案例只需要上传order.txt到HDFS上即可-"/user/hadoop/order_productv2/input"
二、代码
- DistributedCacheDriver.java
package com.ittzg.hadoop.orderproductv2;
import com.ittzg.hadoop.orderproduct.OrderAndProductBean;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
/**
* @email: tazhigang095@163.com
* @author: ittzg
* @date: 2019/7/6 20:46
*/
public class DistributedCacheDriver {
public static class DistributedCacheMapper extends Mapper<LongWritable,Text,OrderAndProductBean,NullWritable>{
Map<String,String> map = new HashMap<String,String>();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//获取缓存在中的文件
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("j:/pd.txt")));
String line;
while(StringUtils.isNotEmpty(line = reader.readLine())){
// 2 切割
String[] fields = line.split("\t");
// 3 缓存数据到集合
System.out.println(fields[0]+":"+fields[0].trim().length());
map.put(fields[0], fields[1]);
}
// 4 关流
reader.close();
}
OrderAndProductBean orderAndProductBean= new OrderAndProductBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
System.out.println(map.toString());
String line = value.toString();
String[] split = line.split("\t");
orderAndProductBean.setOrderId(split[0]);
orderAndProductBean.setPdId(split[1]);
orderAndProductBean.setAccount(split[2]);
orderAndProductBean.setPdName(map.get(split[1]));
orderAndProductBean.setFlag("0");
context.write(orderAndProductBean,NullWritable.get());
}
}
public static class OrderProDuctReduce extends Reducer<OrderAndProductBean,NullWritable,OrderAndProductBean,NullWritable>{
@Override
protected void reduce(OrderAndProductBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
public static void main(String[] args) throws Exception{
// 设置输入输出路径
String input = "hdfs://hadoop-ip-101:9000/user/hadoop/order_productv2/input";
String output = "hdfs://hadoop-ip-101:9000/user/hadoop/order_productv2/output";
Configuration conf = new Configuration();
conf.set("mapreduce.app-submission.cross-platform","true");
Job job = Job.getInstance(conf);
//
job.setJar("F:\\big-data-github\\hadoop-parent\\hadoop-order-product\\target\\hadoop-order-product-1.0-SNAPSHOT.jar");
job.setMapperClass(DistributedCacheMapper.class);
job.setReducerClass(OrderProDuctReduce.class);
job.setMapOutputKeyClass(OrderAndProductBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(OrderAndProductBean.class);
job.setOutputValueClass(NullWritable.class);
// 6 加载缓存数据
job.addCacheFile(new URI("file:/j:/pd.txt"));
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop-ip-101:9000"),conf,"hadoop");
Path outPath = new Path(output);
if(fs.exists(outPath)){
fs.delete(outPath,true);
}
FileInputFormat.addInputPath(job,new Path(input));
FileOutputFormat.setOutputPath(job,outPath);
boolean bool = job.waitForCompletion(true);
System.exit(bool?0:1);
}
}
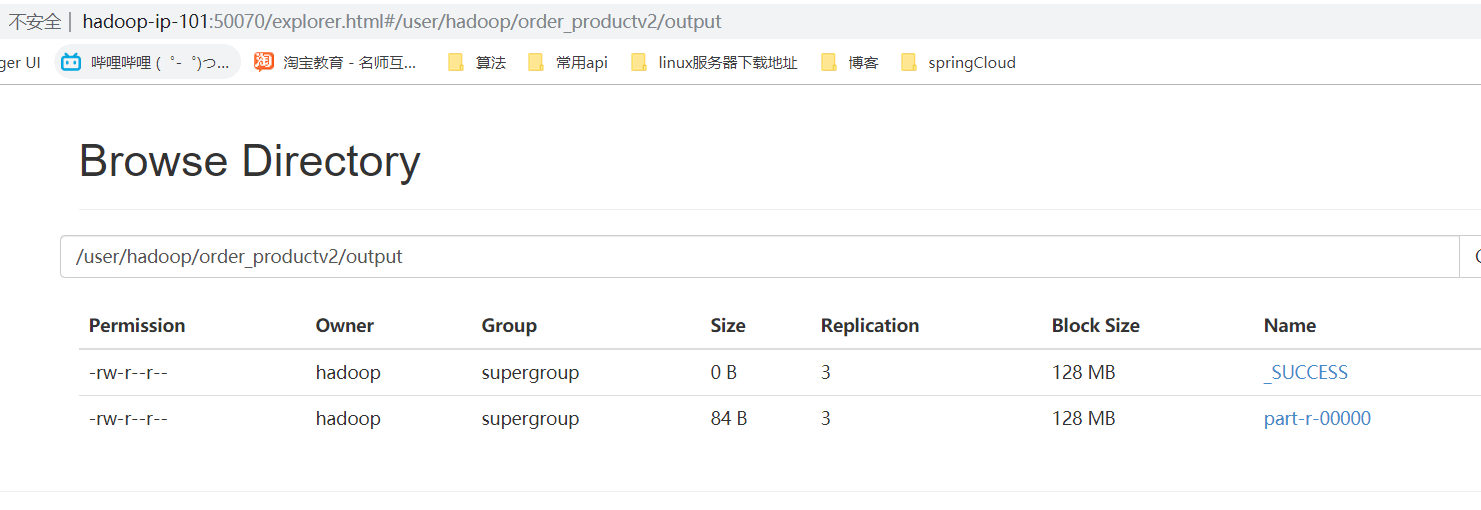
三、运行结果
- 网页浏览
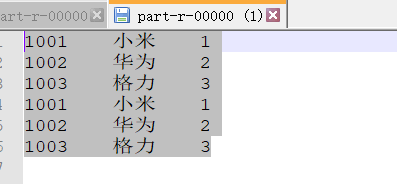
- 文件内容下载浏览















 2023
2023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









