






Flink:开源分布式流式处理框架
基本特性
- 提供准确的结果,即使是面对无序或延迟数据
- 有状态的且容错,可无缝恢复,且能维持精确一次处理语义
- 运行在大规模多节点上,有很好的TPS和延时性能
很多Flink特性——状态管理,无序数据处理和灵活的时间窗口都是用于实现无限数据集上的精确结果计算,当然也可以用于有限数据集上的计算。
- 确保精确一次的处理语义用于状态计算,有状态意味着应用可以持续维护数据的聚合或汇总。Checkpointing机制确保精确一次
- Flink支持流式处理和窗口化(基于event time)。使用event time可以很容易地得到准确的计算结果,即使事件是无序到达或是延迟到达
- Flink支持灵活的时间窗口,可以基于时间、数量或会话以及数据驱动的时间窗口。
- 轻量级的容错方案,允许系统维护高TPS并提供精确一次的处理语义。0数据丢失
- 高TPS,低延时
- Savepoint机制提供状态版本化,可以更新应用或重新处理历史数据而不造成状态丢失或停机
- 旨在运行于大规模集群之上,节点数可达上千。同时也支持单机运行。另外Flink还支持YARN和Mesos
Flink提供了两套API:DataStrem和DataSet,分别用于处理无限数据集和有限数据集。在Flink中,一个有限数据集被视为无限数据集的一个特例,这样就可以使用一套流式概念来处理所有的数据集。DataSet API就是这样的思想,有限数据集在Flink内部就是被当做一个有限流被处理的。总之就是一套模型衍生出两套API分别处理两种数据集合类型
Flink架构
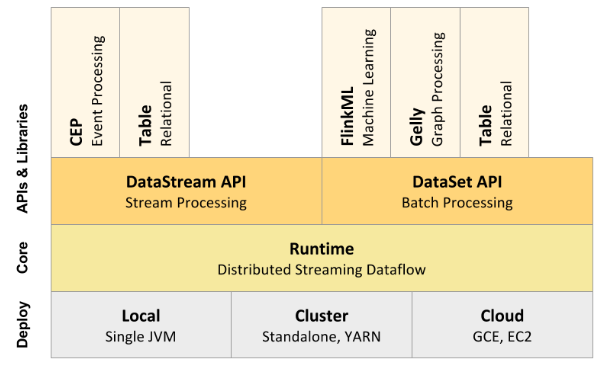
部署模式: 可运行于云平台或普通集群环境,可由YARN或Mesos调度和管理
运行时:Flink core是一个分布式流数据流引擎,每次只处理一条事件,而不是以批的方式处理
API:
- DataStream API——实现数据流转化
- DataSet API——实现数据集合上的转化
- Table API —— 类SQL,可集成进DataStream或DataSet
- Streaming SQL——在流上执行SQL查询,语法类似于Apache Calcite
库:提供了很多特定用途的库,比如CEP,机器学习,图像处理以及与Storm的集成
使用场景
1 优化电子商务网站实时查询结果
2 流式处理
3 网络/传感器监控和错误检测
4 企业数据挖掘ETL
Flink程序构成
- 数据源:提供输入数据
- 转换:处理步骤,修改输入
- 数据输出Sink:Flink发送处理后的数据

















 1587
1587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









