






(非原创内容,从多篇博客整理来的)
1. 概述
1.1 Arm与Inter
Arm的处理器与Intel处理器有许多不同,其中最主要的区别就在于指令集。相对与Intel采用的复杂指令集(CISC),Arm属于精简指令集(RISC),它指令集少寄存器多。相比而言,精简指令集可以使代码执行变快,但是代价是指令集变少了,编写代码时要更加注意指令间使用关系以及约束。
Arm架构有两种模式:Arm模式和Thumb模式,后者的代码只有2字节或者4字节。
此外,Arm和x86还有其他的不同点:
- Arm中的很多指令都可以用来做为条件执行的判断依据
- x86和x64的机器码使用小端格式
- Arm机器码在v3之前是小端,之后默认采用大端模式,但可以切换到小端
1.2 汇编语言的本质
在最底层,只有电路的电信号,信号被格式化成可变化的高低电平0V(off)或者5V(on)。但是通过电压变化来表述电路状态是繁琐的,所以用0和1来代替高低电平,也就有了二进制格式。由二进制序列组成的组合便是最小的计算机处理器工作单元了:
1110 0001 1010 0000 0010 0000 0000 0001
但是这些组合是不可能记住的,所以就需要助记符来帮助我们记忆这些二进制组合,这些助记符一般是连续的三个字母,用这些助记符编写的程序就是汇编语言程序,用以代表一种计算机的机器码的助记符集合就称之为汇编语言。所以,汇编语言是用来编写程序的最底层的语言。
1.3 Arm的两种模式:Arm和Thumb
常见的Arm指令是32位,其中thumb模式是16位模式,标准32位模式下,可以切换到Thumb模式下用以压缩代码提高空间利用率,程序可以通过对应的指令在Arm模式和Thumb模式之间切换。
Thumb指令可以看作是Arm指令压缩形式的子集,是针对代码密度的问题而提出的,它具有16位的代码密度,但Thumb并不是完整的体系结构,也即是说程序不能只执行Thumb指令而不支持Arm指令集,所以Thumb指令只支持通用功能,必要时借助ARM指令集。
编写Thumb指令时,需先使用伪指令CODE16声明,Arm指令中使用BX指令跳转到Thumb指令以切换处理器状态;编写Arm指令时,可使用伪指令CODE32声明。
Thumb指令集没有协处理指令、信号量指令以及访问CPSR、SPSR的指令,没有乘加指令及64位乘法指令,并且指令的第二操作数受到限制;除跳转指令B有条件执行功能外,其他指令均为无条件执行;大多数Thumb数据处理指令采用地址格式。
2. 数据类型
2.1 Arm汇编数据类型基础
加载和存储的数据类型可以是无符号(有符号)的字(word)、半字(halfword)、字节(bytes),arm汇编中扩展后缀-sh和-h对应半字、-sb和-b对应字节,相关汇编指令:
ldr @加载字
ldrh @加载无符号半字
ldrsh @加载半字
ldrb @加载无符号字节
ldrsb @加载字节
str @存储字
strh @存储无符号半字
strsh @存储半字
strb @存储无符号字节
strsb @存储字节2.2 字节序
前面提到过,版本3之前,Arm使用小端序,之后采用大端序同时允许切换回小端序。Arm指令里面,访问数据时采用大端序还是小端序由程序状态寄存器(CPSR)的第九个比特位来决定。
2.3 Arm寄存器
ARM处理器共有37个寄存器。这些寄存器包括:
- 31个通用寄存器,包括未分组寄存器R0-R7、分组寄存器R8-R14和程序计数器( PC 指针),均为32位的寄存器。
- 6个状态寄存器,包括程序状态寄存器 CPSR 和5个物理状态寄存器 SPSR (用以异常发生时保存 CPSR 的值,异常退出时恢复 CPSR )。 这些状态寄存器用以标识 CPU 的工作状态及程序的运行状态,均为32位。
具体如下
| 用户模式 usr | 系统模式 sys | 特权模式 svc | 中止模式 abt | 未定义指令模式 und | 外部中断模式 irq | 快速中断模式 fiq |
| R0 | R0 | R0 | R0 | R0 | R0 | R0 |
| R1 | R1 | R1 | R1 | R1 | R1 | R1 |
| R2 | R2 | R2 | R2 | R2 | R2 | R2 |
| R3 | R3 | R3 | R3 | R3 | R3 | R3 |
| R4 | R4 | R4 | R4 | R4 | R4 | R4 |
| R5 | R5 | R5 | R5 | R5 | R5 | R5 |
| R6 | R6 | R6 | R6 | R6 | R6 | R6 |
| R8 | R8 | R8 | R8 | R8 | R8 | R8_fiq |
| R9 | R9 | R9 | R9 | R9 | R9 | R9_fiq |
| R10 | R10 | R10 | R10 | R10 | R10 | R10_fiq |
| R11 | R11 | R11 | R11 | R11 | R11 | R11_fiq |
| R12 | R12 | R12 | R12 | R12 | R12 | R12_fiq |
| R13(SP) | R13 | R13_svc | R13_abt | R13_und | R13_inq | R13_fiq |
| R14(LR) | R14 | R14_svc | R14_abt | R14_und | R14_inq | R14_fiq |
| PC(R15) | PC | PC | PC | PC | PC | PC |
| CPSR | CPSR | CPSR | CPSR | CPSR | CPSR | CPSR |
| SPSR_svc | SPSR_abt | SPSR_und | SPSR_inq | SPSR_fiq |
2.3.1 未分组寄存器 R0 - R7
对于未分组寄存器,它们没有被系统用于特别的用途,因此任何可采用通用寄存器的应用场合都可以使用未分组寄存器。但需要注意一点,未分组寄存器不会因为处理器模式的改变而更改指向的寄存器,因此在所有的处理器模式下未分组寄存器都指向同一个寄存器,当中断或异常处理造成处理器模式转换的时候,由于不同的处理器模式使用了相同的物理寄存器,这就有可能造成寄存器中的数据被破坏。
R0-R3 用于传参数,更多的参数须通过栈来传递,调用函数的时候,参数先从R0依次传递;R0-R1 也作为结果寄存器,保存函数返回结果,被调用的子程序在返回前无须恢复这些寄存器的内容。
R4-R6 没有特殊规定,就是普通的通用寄存器,作为被调保存(callee-save)寄存器,一般保存函数的局部变量(local variables)。被调保存寄存器(callee-save register)是指,如果这个寄存器被调用/使用之前,需要被保存。
2.3.2 分组寄存器 R8-R14
对于分组寄存器,它们每一次所访问的物理寄存器和处理器当前的运行模式有关。例如在快速中断模式 fiq下R8-R12访问寄存器 R8_fiq-R12_fiq ;而在其他模式下又访问 R8_usr-R12_usr 。因此它们每个对应着两个不同的寄存器。
对于R13(SP)、R14(LR)来说,每个寄存器对应着6个不同的物理寄存器,其中的一个是用户模式与系统模式共用,另外5个物理寄存器对应于其他5种不同的运行模式。采用以下的记号来区分不同的物理寄存器:R13_< mode >、R14_< mode >,其中,mode为以下几种模式之一:usr、fiq、irq、svc、abt、und。
R8,R10-R11 没有特殊的规定,就是普通寄存器。
R9 是操作系统保留。
R11 又称作帧指针(FP),通常Arm模式下R11作为帧指针,Thumb模式下R7则作为帧指针。
R13 栈指针寄存器(SP),用于存放栈顶指针,该栈是一块用来存储本地函数的内存区域。当函数被返回时, 存储空间会被回收。 在堆栈上分配空间,需要从栈寄存器(the stack register)减去。分配一个32位的值, 需要从堆栈指针(the stack pointer)减去4。Arm堆栈结构是从高向低压栈的,因为处理器是32位的Arm,所以每压一次栈,SP就会移动4个字节(32位),也就是SP = SP - 4。由于处理器的每种运行模式均有属于自己的物理寄存器R13,使其指向该运行模式下的栈空间,这样,当程序的运行进入异常模式时,可以将需要保护的寄存器放入R13所指向的堆栈,而当程序从异常模式返回时,则从对应的堆栈恢复,采用这种方式可以保证异常发生后程序的正常执行。
R14 链接寄存器(LR),当一个子程序被调用时,LR 会被填入程序计数器(PC);当一个子程序执行完毕后,PC从 LR 的值恢复,从而返回(到主函数中)。
0x00008d68 <+44>: bl 0x8cd4 <func>
0x00008d6c <+48>: ...
0x00008d70 <+52>: ...123
通常情况下,在汇编代码中不会出现 R14 中产生 PC 备份的指令语句。可以简单的理解为在执行调用的同时,将当前 PC 的指向的值 0x00008d70 减去一条指令的长度,这里是ARM工作状态,指令长度为 0x00000004,并交由R14保存。减去一条指令的原因很简单,不减的话返回的时候中间 0x00008d6c 处的那条指令就被跳过了。
(当前执行的是 0x00008d68 处的指令,0x00008d6c 处的指令处于译码阶段,0x00008d70 的指令处于取指阶段,PC总是指向取指阶段的指令。关于 ARM 处理器的流水线机制和 PC 指向的值 详见下文。)
2.3.3 程序计数器 R15
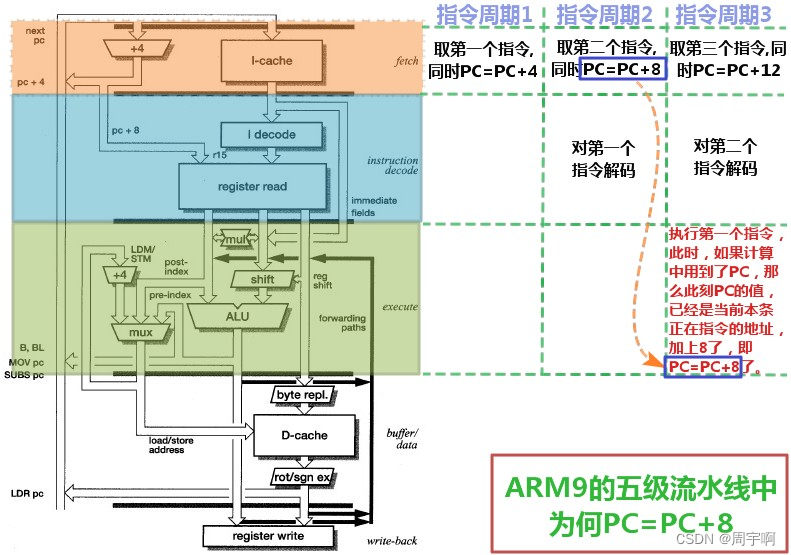
介绍R15之前先简单了解一下 ARM 处理器的是流水线机制。 ARM7 处理器采用3级流水线来增加处理器指令流的速度,能提供 0.9MIPS/MHz 的指令处理速度。
ARM7 的流水线有3个阶段,因此指令分3个阶段执行。
⑴ 取指从存储器装载一条指令
⑵ 译码识别将要被执行的指令
⑶ 执行处理指令并将结果写会寄存器
对于x86处理器来说,只有完成一条指令的读取和执行后,才会执行下一条指令。这样, PC 始终指向的正在“执行”的指令。而对于 ARM7 来说因为是3级流水线,所以把指令的处理分为了上面所述的3个阶段。所以处理时实际是这样的: ARM 正在执行第1条指令的同时对第2条指令进行译码,并将第3条指令从存储器中取出。因此 ARM7 流水线只有在取第4条指令时,第1条指令才算完成执行。继而 ARM 的 PC 寄存器永远指向当前执行的指令后的第二条指令,即处于取指阶段的指令。
2.3.4 SP、FP详解
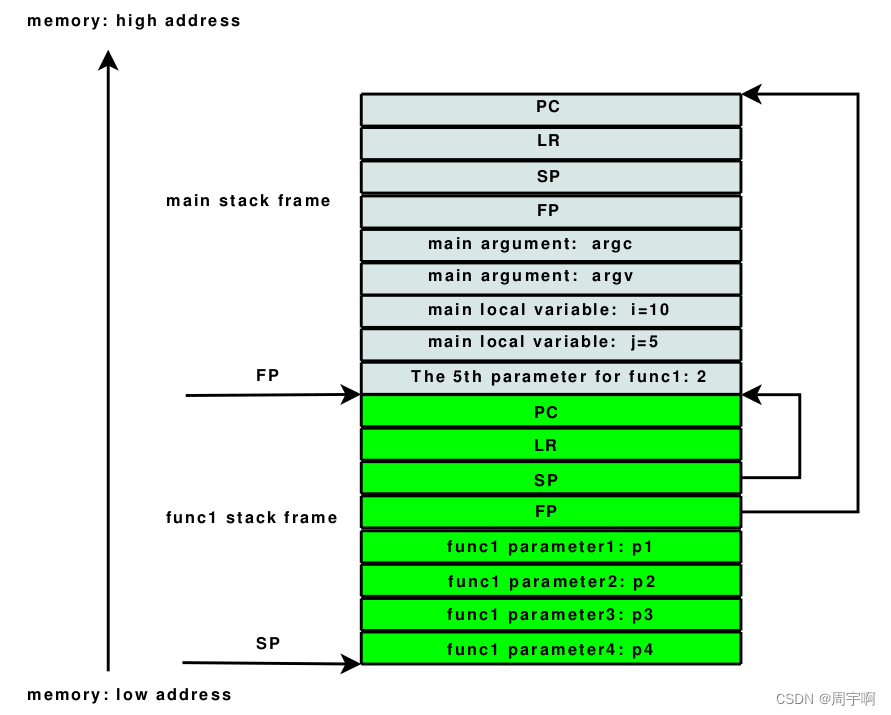
栈帧(Stack Frame)就是一个函数所在的栈的一部分,所有函数的栈帧串起来就组成了一个完整的栈。
栈帧的两个边界分别由 FP 和 SP 来限定,它们2个指向的是当前函数的栈帧。
考虑 main 函数调用fun1函数的情形,下图是它们使用栈。
观察 func1 的栈帧,它的 SP 和 FP 之间指向的栈帧就是 main 函数的栈帧。
main 函数产生调用时,PC、LR、SP、FP 会在第一时间压栈。
2.3.5 状态寄存器 R16
寄存器R16用作当前程序状态寄存器 CPSR (Current Program Status Register),可在任何运行模式下被访问,它包括条件标志位、中断禁止位、当前处理器模式标志位,以及其他一些相关的控制和状态位
每一种运行模式下又都有一个专用的物理状态寄存器,称为备份的程序状态寄存器 SPSR (Saved Program Status Register),当异常发生时, SPSR 用于保存 CPSR 的当前值,从异常退出时则可由 SPSR 来恢复 CPSR 。
由于用户模式和系统模式不属于异常模式,他们没有 SPSR ,当在这两种模式下访问 SPSR ,结果是未知的。
ARM 的执行条件与 x86 下面的标志位有些类似,系统通过对这些标志位的判断来确定是否满足执行条件。几乎所有的 ARM 指令都包含一个4位的条件码,位于指令的最高4位。条件码共有16种,每种条件码可用两个字符表示,这两个字符可以添加在指令助记符的后面和指令同时使用。
例如,跳转指令 B 可以加上后缀 EQ 变成 BEQ 表示“相同则跳转”,即当 CPSR 中的Z标志置位时发生跳转。在16种条件标志码中,只有15种可以使用,如下表所示。第十六种(1111)为系统保留,暂时不能使用。
| 编 码 | 条件助记符 | 标志位 | 含 义 |
| 0000 | EQ | Z=1 | 相等 |
| 0001 | NE | Z=0 | 不相等 |
| 0010 | CS | C=1 | 无符号大于或等于 |
| 0011 | CC | C=0 | 无符号小于 |
| 0100 | MI | N=1 | 负值 |
| 0101 | PL | N=0 | 正值或 0 |
| 0110 | VS | V=1 | 溢出 |
| 0111 | VC | V=0 | 无溢出 |
| 1000 | HI | C=1 且 Z=0 | 无符号大于 |
| 1001 | LS | C=0 且 Z=1 | 无符号小于或等于 |
| 1010 | GE | N 和 V 相同 | 有符号大于或等于 |
| 1011 | LT | N 和 V 不相同 | 有符号小于 |
| 1100 | GT | Z=0 且 N 等于 V | 有符号大于 |
| 1101 | LE | Z=1 且 N 不等于 V | 有符号小于或等于 |
| 1110 | AL | 任意 | 无条件执行(默认) |
| 1111 | NV | 任意 | 从不执行(不要使用) |
3. Arm模式和Thumb模式
Arm模式(32位)和Thumb模式(16位也可以是32位)是Arm处理器的两个主要操作状态。不同版本的Arm,其调用约定不完全相同,而且支持的Thumb指令集也不完全相同。Thumb指令不同的名字用来区分不同版本:
- Thumb-1(16位宽指令集):ARMv6以及更早期的版本中使用
- Thumb-2(16位\32位宽指令集):在Thumb-1的基础上拓展了更多的指令集(ARMv6T2、ARMv7以及很多32位Android手机所支持的架构上使用)
- Thumb-EE:包括一些改变以及对于动态生成代码的补充
3.1 Arm与Thumb的区别
所有的ARM模式指令都支持条件执行,一些版本的ARM处理器上允许Thumb模式下通过IT汇编指令进行条件执行,条件执行减少了要被执行的指令数量,以及用来做分支跳转的语句,所以具有更高的代码密度。
条件执行和条件跳转:
1 条件执行:指令可以根据状态位来决定是否执行,即只有当某个特定条件满足时(条件标志位),指令才会执行(可以减少分支指令的数目,改善性能,提高代码密度)
2 条件跳转:跳转指令又叫分支指令,是指能够迫使PC指针指向一个新地址,改变程序的执行流程。跳转指令使得子程序调用、if-then-else结构、循环结构变为可能
3.2 Arm指令集模版
ARM指令的模板如下:
MNEMONIC{S}{condition} {Rd}, Operand1, Operand2
助记符{是否使用CPSR}{是否条件执行以及条件} {目的寄存器}, 操作符1, 操作符2
上述模板满足大部分的ARM指令,其具体含义为:
- MNEMONIC: 指令助记符,如ADD
- {S}: 可选的扩展位,如果指令后面加了s则需要依据计算结果更新CPSR寄存器中的条件跳转相关的FLAG
- {condition}: 如果机器码要被条件执行,那它需要满足的条件标识
- {Rd}: 存储结果的目的寄存器
- Operand1: 第一个操作数,寄存器或者立即数
- Operand2: 第二个操作数(可变),可以是立即数、寄存器、偏移量的寄存器
满足上述模板的同样ARM指令集及其含义:
| 指令 | 含义 | 指令 | 含义 |
| MOV | 移动数据 | EOR | 异或 |
| MVN | 取反码移动数据 | LDR | 加载数据 |
| ADD | 数据相加 | STR | 存储数据 |
| SUB | 数据相减 | LDM | 多次加载 |
| MUL | 数据相乘 | STM | 多次存储 |
| LSL | 逻辑左移 | PUSH | 压栈 |
| LSR | 逻辑右移 | POP | 出栈 |
| ASR | 算术右移 | B | 分支跳转 |
| ROR | 循环右移 | BL | 链接分支跳转 |
| CMP | 比较操作 | BX | 分支跳转切换 |
| AND | 比特位与 | BLX | 链接分支跳转切换 |
| ORR | 比特位或 | SWI/SVC | 系统调用 |
4. Arm内存访问相关指令
Arm使用加载-存储模式控制对内存的访问,即只有加载/存储指令才能访问内存。所以Arm下,需要在操作数据前,必须先从内存中取出来放到寄存器再进行相关操作。(x86中允许一些指令直接操作内存中的数据)
Arm架构中的加载和存储有三种形式,区别在于偏移量的形式:立即数作为偏移、寄存器作为偏移、寄存器缩放值作为偏移。通常,LDR用于从内存中加载数据到寄存器,STR用于将寄存器中的数据存放到内存中:
LDR R2, [R0] @ 从R0指向的内存地址取出数据存放到R2中
STR R2, [R1] @ 把R2的数据存放到R1指向的内存地址中参考如下代码
.data /* 数据段是在内存中动态创建的,所以它的在内存中的地址不可预测*/
var1: .word 3 /* 内存中的第一个变量 */
var2: .word 4 /* 内存中的第二个变量 */
.text /* 代码段开始 */
.global _start
_start:
ldr r0, adr_var1 @ 将存放var1值的地址adr_var1加载到寄存器R0中
ldr r1, adr_var2 @ 将存放var2值的地址adr_var2加载到寄存器R1中
ldr r2, [r0] @ 将R0所指向地址中存放的0x3加载到寄存器R2中
str r2, [r1] @ 将R2中的值0x3存放到R1做指向的地址
bkpt
adr_var1: .word var1 /* var1的地址助记符 */
adr_var2: .word var2 /* var2的地址助记符 */4.1 立即数做偏移的情况
参考代码如下
.data
var1: .word 3
var2: .word 4
.text
.global _start
_start:
ldr r0, adr_var1 @ 将存放var1值的地址adr_var1加载到寄存器R0中
ldr r1, adr_var2 @ 将存放var2值的地址adr_var2加载到寄存器R1中
ldr r2, [r0] @ 将R0所指向地址中存放的0x3加载到寄存器R2中
str r2, [r1, #2] @ 取址模式:基于偏移量。R2寄存器中的值0x3被存放到R1寄存器的值加2所指向地址处。
str r2, [r1, #4]! @ 取址模式:基于索引前置修改。R2寄存器中的值0x3被存放到R1寄存器的值加4所指向地址处,之后R1寄存器中存储的值加4,也就是R1=R1+4。
ldr r3, [r1], #4 @ 取址模式:基于索引后置修改。R3寄存器中的值是从R1寄存器的值所指向的地址中加载的,加载之后R1寄存器中存储的值加4,也就是R1=R1+4。
bkpt
adr_var1: .word var1
adr_var2: .word var24.2 寄存器做偏移的情况
参考代码如下
.data
var1: .word 3
var2: .word 4
.text
.global _start
_start:
ldr r0, adr_var1 @ 将存放var1值的地址adr_var1加载到寄存器R0中
ldr r1, adr_var2 @ 将存放var2值的地址adr_var2加载到寄存器R1中
ldr r2, [r0] @ 将R0所指向地址中存放的0x3加载到寄存器R2中
str r2, [r1, r2] @ 取址模式:基于偏移量。R2寄存器中的值0x3被存放到R1寄存器的值加R2寄存器的值所指向地址处。R1寄存器不会被修改。
str r2, [r1, r2]! @ 取址模式:基于索引前置修改。R2寄存器中的值0x3被存放到R1寄存器的值加R2寄存器的值所指向地址处,之后R1寄存器中的值被更新,也就是R1=R1+R2。
ldr r3, [r1], r2 @ 取址模式:基于索引后置修改。R3寄存器中的值是从R1寄存器的值所指向的地址中加载的,加载之后R1寄存器中的值被更新也就是R1=R1+R2。
bx lr
adr_var1: .word var1
adr_var2: .word var24.3 寄存器缩放值做偏移的情况
参考代码如下
.data
var1: .word 3
var2: .word 4
.text
.global _start
_start:
ldr r0, adr_var1 @ 将存放var1值的地址adr_var1加载到寄存器R0中
ldr r1, adr_var2 @ 将存放var2值的地址adr_var2加载到寄存器R1中
ldr r2, [r0] @ 将R0所指向地址中存放的0x3加载到寄存器R2中
str r2, [r1, r2, LSL#2] @ 取址模式:基于偏移量。R2寄存器中的值0x3被存放到R1寄存器的值加(左移两位后的R2寄存器的值)所指向地址处。R1寄存器不会被修改。
str r2, [r1, r2, LSL#2]! @ 取址模式:基于索引前置修改。R2寄存器中的值0x3被存放到R1寄存器的值加(左移两位后的R2寄存器的值)所指向地址处,之后R1寄存器中的值被更新,也就R1 = R1 + R2<<2。
ldr r3, [r1], r2, LSL#2 @ 取址模式:基于索引后置修改。R3寄存器中的值是从R1寄存器的值所指向的地址中加载的,加载之后R1寄存器中的值被更新也就是R1 = R1 + R2<<2。
bkpt
adr_var1: .word var1
adr_var2: .word var24.4 关于PC相对取址的LDR指令
参考代码如下
.section .text
.global _start
_start:
ldr r0, =jump /* 加载jump标签所在的内存位置到R0 */
ldr r1, =0x68DB00AD /* 加载立即数0x68DB00AD到R1 */
jump:
ldr r2, =511 /* 加载立即数511到R2 */
bkpt上述指令被称作伪指令,编写Arm汇编时可以使用这种格式的指令去引用文字标识池中的数据,比如上述例子中用一条指令将一个32位的常量值放到一个寄存器中,而这么写的原因是因为Arm每次仅能加载8位的值。
4.5 在Arm中使用立即数的规律
在ARM下不能像x86那样直接将立即数加载到寄存器中,因为使用的立即数是受限的。我们知道的是ARM指令的宽度是32位,并且所有的指令都是可以条件执行的。这里一共有16种条件可以使用,并且每个条件在机器码中的占位是4位,然后还需要2位来作为目的寄存器、2位作为第一操作寄存器、1位用作设置状态的标记位、还有操作码(opcode)等的占位。到最后,每条指令剩下的用于存放立即数的空间只有12位宽,即4096个不同的值。换句话说,ARM下使用MOV指令时所操作的立即数的数值范围是有限的,如果是大数就只能拆分成多个部分外加移位操作拼接了。
因为还要外加移位操作,所以剩下的12位中需要有4位用作0-30位的循环右移,8位用作加载0-255中的任意值,所以有公式:v = n ror 2*r
有效的立即数(例):
#256 // 1 循环右移 24位 --> 256
#384 // 6 循环右移 26位 --> 384
#484 // 121 循环右移 30位 --> 484
#16384 // 1 循环右移 18位 --> 16384
#2030043136 // 121 循环右移 8位 --> 2030043136
#0x06000000 // 6 循环右移 8位 --> 100663296 (十六进制值0x06000000)
Invalid values:
#370 // 185 循环右移 31位 --> 31不在范围内 (0 – 30)
#511 // 1 1111 1111 --> 比特模型不符合
#0x06010000 // 1 1000 0001.. --> 比特模型不符合但是这样并不一次性加载所有32位值,两种解决办法如下:
- 用小部分去组成更大的值:
比如MOV r0, #511会把511拆分成两部分,即MOV r0, #256; ADD r0, #255
- 使用加载指令构造
LDR r1, =value的形式
这种情况下编译器会自动转换成MOV的形式,如果失败就转换成通过从数据段中加载的形式即PC加偏移量。
5. 连续存取
参考代码如下
.data
array_buff:
.word 0x00000000 /* array_buff[0] */
.word 0x00000000 /* array_buff[1] */
.word 0x00000000 /* array_buff[2]. 这一项存的是指向array_buff+8的指针 */
.word 0x00000000 /* array_buff[3] */
.word 0x00000000 /* array_buff[4] */
.text
.global main
main:
adr r0, words+12 /* words[3]的地址 -> r0 ,adr指令用于将基于PC相对偏移的地址值读取到寄存器中,ldr与adr功能一致,区别在于ldr主要用于远端的地址*/
ldr r1, array_buff_bridge /* array_buff[0]的地址 -> r1 */
ldr r2, array_buff_bridge+4 /* array_buff[2]的地址 -> r2 */
ldm r0, {r4,r5} /* words[3] -> r4 = 0x03; words[4] -> r5 = 0x04 */
stm r1, {r4,r5} /* r4 -> array_buff[0] = 0x03; r5 -> array_buff[1] = 0x04 */
ldmia r0, {r4-r6} /* words[3] -> r4 = 0x03, words[4] -> r5 = 0x04; words[5] -> r6 = 0x05; */
stmia r1, {r4-r6} /* r4 -> array_buff[0] = 0x03; r5 -> array_buff[1] = 0x04; r6 -> array_buff[2] = 0x05 */
ldmib r0, {r4-r6} /* words[4] -> r4 = 0x04; words[5] -> r5 = 0x05; words[6] -> r6 = 0x06 */
stmib r1, {r4-r6} /* r4 -> array_buff[1] = 0x04; r5 -> array_buff[2] = 0x05; r6 -> array_buff[3] = 0x06 */
ldmda r0, {r4-r6} /* words[3] -> r6 = 0x03; words[2] -> r5 = 0x02; words[1] -> r4 = 0x01 */
ldmdb r0, {r4-r6} /* words[2] -> r6 = 0x02; words[1] -> r5 = 0x01; words[0] -> r4 = 0x00 */
stmda r2, {r4-r6} /* r6 -> array_buff[2] = 0x02; r5 -> array_buff[1] = 0x01; r4 -> array_buff[0] = 0x00 */
stmdb r2, {r4-r5} /* r5 -> array_buff[1] = 0x01; r4 -> array_buff[0] = 0x00; */
bx lr
words:
.word 0x00000000 /* words[0] */
.word 0x00000001 /* words[1] */
.word 0x00000002 /* words[2] */
.word 0x00000003 /* words[3] */
.word 0x00000004 /* words[4] */
.word 0x00000005 /* words[5] */
.word 0x00000006 /* words[6] */
array_buff_bridge:
.word array_buff /* array_buff的地址*/
.word array_buff+8 /* array_buff[2]的地址 */对于上述的汇编代码,.word标识用于对内存中长度为32位的数据块做引用,所以程序中由.data段组成的数据,在内存中会申请一个长度为5的4字节数组array_buff。
ldm用于加载,stm用于存储。实际的操作就是将从某个地址开始连续读取n个字节的数据或向某个地址连续写入n个字节的数据。
ldm和stm的多种形式:
IA(increase after)
IB(increase before)
DA(decrease after)
DB(decrease before)5.1 Push和Pop
PUSH/POP和LDMIA/STMDB:
.text
.global _start
_start:
mov r0, #3
mov r1, #4
push {r0, r1}
pop {r2, r3}
stmdb sp!, {r0, r1} @ sp之后没有"!"时,指令执行之后sp指针会回到原来的位置,带有"!"时,执行之后,sp执行之后位置改变,效果等同于pop、push
ldmia sp!, {r4, r5}
bkptLDMIA功能是取址后递增,这一行为刚好和POP功能相似,同样的,STMDB是先递减后再存值,这又刚好和PUSH的行为相似。
6.条件执行与分支
6.1 条件执行
参考代码如下
.global main
main:
mov r0, #2 /* 初始化值 */
cmp r0, #3 /* 将R0和3相比做差,负数产生则N位置1 */
addlt r0, r0, #1 /* 如果小于等于3,则R0加一 */
cmp r0, #3 /* 将R0和3相比做差,零结果产生则Z位置一,N位置恢复为0 */
addlt r0, r0, #1 /* 如果小于等于3,则R0加一*/
bx lr6.2 Thumb模式中的条件执行
指令格式:Syntax: IT{x{y{z}}} cond,其中:
- cond:代表IT指令后第一条执行指令需要满足的条件
- x:代表第二条条件执行的指令要满足的条件逻辑相同还是相反
- y:代表第三条条件执行的指令要满足的条件逻辑相同还是相反
- z:代表第四条条件执行的指令要满足的条件逻辑相同还是相反
IT指令的含义是if-then-(else),所以:
- IT:if-then,接下来的一条指令条件执行
- ITT:if-then-then,接下来的两条指令条件执行
- ITTE:if-then-then-else,接下来的三条指令条件执行
- ITTEE:if-then-then-else-else,接下来的四条指令条件执行
在IT块中的每一条条件指令必须是相同的逻辑条件或相反的逻辑条件,如ITE指令,第一条和第二条指令必须使用相同的逻辑条件,而第三条必须是和前两条逻辑上相反的条件:
ITTE NE ; 后三条指令条件执行
ANDNE R0, R0, R1 ; ANDNE不更新条件执行相关flags
ADDSNE R2, R2, #1 ; ADDSNE更新条件执行相关flags
MOVEQ R2, R3 ; 条件执行的move
ITE GT ; 后两条指令条件执行
ADDGT R1, R0, #55 ; GT条件满足时执行加
ADDLE R1, R0, #48 ; GT条件不满足时执行加
ITTEE EQ ; 后两条指令条件执行
MOVEQ R0, R1 ; 条件执行MOV
ADDEQ R2, R2, #10 ; 条件执行ADD
ANDNE R3, R3, #1 ; 条件执行AND
BNE.W dloop ; 分支指令只能在IT块的最后一条指令中使用错误的格式:
IT NE ; 下一条指令条件执行
ADD R0, R0, R1 ; 格式错误:没有条件指令条件指令的逻辑关系:
| 指令 | 逻辑相反 |
| EQ | NE |
| HS(or CS) | LO(or CC) |
| MI | PL |
| VS | VC |
| HI | LS |
| GE | LT |
| GT | LE |
示例代码
.syntax unified @ 这很重要!
.text
.global _start
_start:
.code 32
add r3, pc, #1 @ R3=pc+1
bx r3 @ 分支跳转到R3并且切换到Thumb模式下(因为R3此时最低比特位为1)
.code 16 @ Thumb模式
cmp r0, #10
ite eq @ if R0 == 10
addeq r1, #2 @ then R1 = R1 + 2
addne r1, #3 @ else R1 = R1 + 3
bkpt这里存在一个Arm模式到Thumb模式的转换,指令add r3, PC, #1执行后,r3的最低位刚好为1,所以执行bx r3指令时就会切换到Thumb模式
6.3 分支指令
分支指令(分支跳转)允许在代码中跳转到别的段,比如要跳到某个函数执行或者跳过一段代码块。常用于条件跳转和循环语句,示例代码:
@ 条件分支
.global main
main:
mov r1, #2 @ 初始化 a
mov r2, #3 @ 初始化 b
cmp r1, r2 @ 比较谁更大些
blt r1_lower @ 如果R2更大跳转到r1_lower
mov r0, r1 @ 如果分支跳转没有发生,将R1的值放到到R0
b end @ 跳转到结束
r1_lower:
mov r0, r2 @ 将R2的值放到R0
b end @ 跳转到结束
end:
bx lr @ lr是链接寄存器,此处相当于main函数执行完后返回
上述代码就类似于如下代码:
int a(2), b(3);
if(a>b)
return a;
else
return b;循环分支的例子:
.global main
main:
mov r0, #0 @ 初始化 a
loop:
cmp r0, #4 @ 检查 a==4
beq end @ 如果是则结束
add r0, r0, #1 @ 如果不是则加1
b loop @ 重复循环
end:
bx lr功能相似的c代码:
int a(0);
while(a < 4)
a += 1;6.4 B/BL/BX
- B:Branch,简单的跳转到一个函数
- BL:Branch link,将下一条指令的入口PC-4保存到LR,然后跳转到函数
- BX、BLX:同B/BL,只是外加了执行模式的切换,且此处需要寄存器作为第一操作数
7. 栈与函数
一般来讲,栈用于存储一些如函数的局部变量、环境变量等临时数据。
7.1 栈相关
关于栈的增长,栈可以向上增长(栈的实现是负向增长时)也可以向下增长(栈的实现是正向增长时)。具体区别在于下一个要存放到栈中的数据要存放到哪里,而决定存放位置的是SP指针。如果SP当前指向上一次存放数据的位置(满栈),SP将会递减(降序栈)或递增(升序栈),然后再对指向的内容进行操作;如果SP指向的是下一次要操作数据的空闲位置(空栈实现),数据会先被存放,而SP会被递减(降序栈)或递增(升序栈)。
不同栈实现,可以使用不同的多次连续存取指令来表示:
| 栈类型 | 压栈 | 弹栈 |
| 满栈降序(FD,Full descending) | STMFD(等价于STMDB,操作之前递减) | LDMFD(等价于LDM,操作之后递增) |
| 满栈增序(FA,Full ascending) | STMFA(等价于STMIB,操作之前递增) | LDMFA(等价于LDMDA,操作之后递减) |
| 空栈降序(ED,Empty descending) | STMED(等价于STMDA,操作之后递减) | LDMED(等价于LDMIB,操作之后递增) |
| 空栈增序(EA,Empty ascending) | STMEA(等价于STM,操作之后递增) | LDMEA(等价于LDMDB,操作之前递减) |
7.2 函数栈帧
ARM下函数体结构:
- 开辟栈帧:
push {r11, lr} /* 保存R11与LR */
add r11, sp, #4 /* 设置栈帧底部,PUSH两个寄存器,SP加4后指向栈帧底部元素 */
sub sp, sp, #16 /* 在栈上申请相应空间 */- 栈帧销毁
sub sp, r11, #4 /* 收尾操作开始,调整栈指针,有两个寄存器要POP,所以从栈帧底部元素再减4 */
pop {r11, pc} /* 收尾操作结束。恢复之前函数的栈帧指针,以及通过之前保存的LR来恢复PC。 */实际上,ARM下的函数栈帧和x86下的栈帧基本无异。















 680
680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









