







这个爬虫我在两个月前就开始做了,后来因为一些技术难题没有解决以及各种期末考试,所以一直搁置了下来。现在终于解决了技术上最难的模拟登录问题,这篇文章中我便会较详细的演示我解决这个问题的方法以及一些心路历程......
以下我就完整的展示一遍我解决这个问题的方法:
1.当我们需要去模拟登录一个网站的时候,首先要做的就是找到那个网站的登录页面(有些网站的注册登录页面不是像下面这张图一样一个单独的页面,而是嵌入在网站里的,这里的freelancer其实也是这种情况,我的解决方法是在url后面加上/login,我估计很多网站都是这样的。如果您看不懂这段可以去 freelancer 看看,要登陆时要点击Log in哦)

那么当我们找到这个页面之后,需要做的就是按下F12来打开浏览器自带的抓包工具,我这里是firebug。然后我们先输入错误的用户名和密码,并且抓包,这样来观察它的post数据长什么样子。
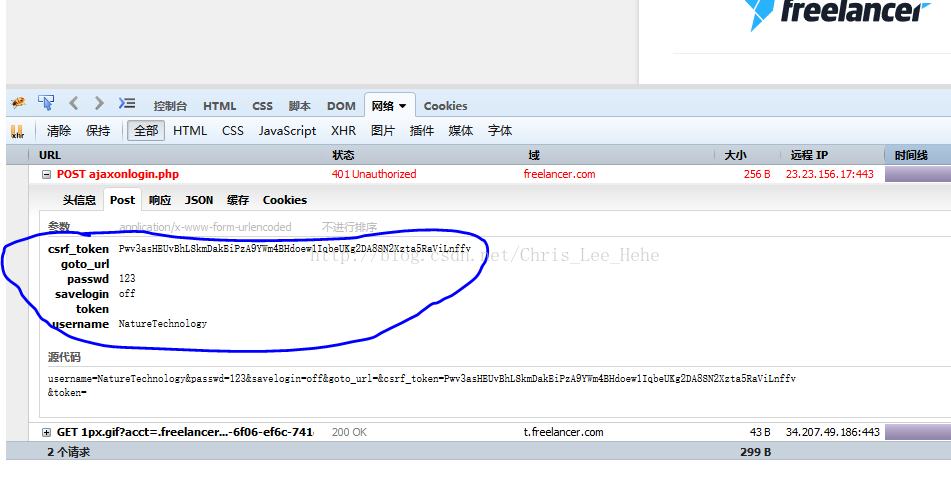
这里我们看到了,post数据里主要有csrf_token,passwd,savelogin,usename,goto_url,token这几个参数。那么我们就知道之后如何构造自己的post参数了。
于是,这里我的代码是这个样子的:
# -*- coding:utf-8 -*- import requests import cookielib agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0' headers = { "Host": "www.freelancer.com", 'User-Agent': agent } session = requests.session() session.cookies = cookielib.MozillaCookieJar(filename='cookies') try: print '加载Cookie...' session.cookies.load(ignore_discard=True) print '加载成功' except: print "Cookie 未能加载" def login(): print "login..." headers["X-Requested-With"] = "XMLHttpRequest" post_url = 'https://www.freelancer.com/users/ajaxonlogin.php' postdata = { 'csrf_token':'Pwv3asHEUvBhLSkmDakEiPzA9YWm4BHdoew1IqbeUKg2DA8SN2Xzta5RaViLnffv', 'passwd':'******', #密码保密哦 'savelogin':'off', 'username':'NatureTechnology' } login_page = session.post(post_url, data=postdata, headers=headers) print login_page.status_code print login_page.text session.cookies.save() def test(): #然后我们访问一个项目的url来进行测试 html = session.get('https://www.freelancer.com/projects/Mobile-Phone/Write-iPhone-application-fix-13394262/',headers=headers) print html.text login() test()然后我以为就结束了,但是返回结果没有成功呢......再然后,我就困在这里了,因为这里的问题应该是在于这个csrf_token这里(关于这个东西大家可以看看 这里 的讲解,讲的是不错的),然而由于我一直没有解决这个问题,于是我开始尝试了另外一种方法,也可以说是爬虫的一大杀器,就是 python+selenium+Phantomjs 的方式,关于这种方式我之后的某次爬虫实战会利用这种方法来给大家分享,在这里我大概阐述一下:因为爬虫说到底本质就是模拟真实用户的行为,而这里Phantomjs是一个无头的浏览器,即没有用户界面。而当它和python结合的时候,这就非常的方便了。如果你用这个方式的话,相当于你的爬虫使用了个浏览器来访问网站了,这就意味着一切用户看见的东西你的爬虫都可以访问到了。
好了我们说回来,那么之前的代码到底出了什么问题呢?关键还是在这个csrf_token上,之前我爬取知乎的时候,知乎类似的参数是已经存在于登录界面的源码中,我们只需要提取出来就行了,但这里源码中并没有,然后我就开始了漫长的观察,试图去发现其规律,最后终于让我找到了。其实在每次登录表单提交的时候,你向服务器发送的cookie里面有一个叫xsrf_token的参数,而这个参数和csrf_token是一模一样的。

所以我们要干什么呢???我们需要在访问的时候加入这些cookie的内容!
于是,我的代码变成了这样:
# -*- coding:utf-8 -*- import requests import cookielib agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0' headers = { "Host": "www.freelancer.com", 'User-Agent': agent } session = requests.session() session.cookies = cookielib.MozillaCookieJar(filename='cookies') try: print '加载Cookie...' session.cookies.load(ignore_discard=True) print '加载成功' except: print "Cookie 未能加载" def login(): myCookie = {'_tracking_session':'93e13395-3371-6f06-ef6c-741e7c5113c5', 'XSRF-TOKEN': 'Pwv3asHEUvBhLSkmDakEiPzA9YWm4BHdoew1IqbeUKg2DA8SN2Xzta5RaViLnffv', '__utmc': '138759908', '__utmt': '1', 'first_session': '%7B%22visits%22%3A2%2C%22start%22%3A1499416819602%2C%22last_visit%22%3A1499416828206%2C%22url%22%3A%22https%3A%2F%2Fwww.freelancer.com%2Fjobs%2F2%2F%2314123689%22%2C%22path%22%3A%22%2Fjobs%2F2%2F%22%2C%22referrer%22%3A%22%22%2C%22referrer_info%22%3A%7B%22host%22%3A%22www.freelancer.com%22%2C%22path%22%3A%22%2Fjobs%2F2%2F%22%2C%22protocol%22%3A%22https%3A%22%2C%22port%22%3A80%2C%22search%22%3A%22%22%2C%22query%22%3A%7B%7D%7D%2C%22search%22%3A%7B%22engine%22%3Anull%2C%22query%22%3Anull%7D%2C%22prev_visit%22%3A1499416819602%2C%22time_since_last_visit%22%3A8604%2C%22version%22%3A0.4%7D', '__utmz': '138759908.1499243491.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)', '__utma': '138759908.909517807.1499243491.1499243491.1499416821.2', '__utmb': '138759908.4.10.1499416821', '__asc': '5151fdd515d1c35002feea7fcf6', '__auc': 'db6d7de215d11e0330f12d00e79', '_uetsid': '_uet464e2b87', 'session2': '75ad8c1f5dfa117c440e42fec322c0efa1d5fe629445c095238ed8f1aeb5e04448c2660d5d770dd0', 'RT': ''} headers["X-Requested-With"] = "XMLHttpRequest" csrf_token = 'Pwv3asHEUvBhLSkmDakEiPzA9YWm4BHdoew1IqbeUKg2DA8SN2Xzta5RaViLnffv' post_url = 'https://www.freelancer.com/users/ajaxonlogin.php' postdata = { 'csrf_token':csrf_token, 'passwd':'*****', 'savelogin':'off', 'username':'NatureTechnology' } login_page = session.post(post_url, data=postdata, headers=headers,cookies=myCookie) print login_page.status_code print login_page.text session.cookies.save() def test(): html = session.get('https://www.freelancer.com/projects/Mobile-Phone/Write-iPhone-application-fix-13394262/',headers=headers) print html.text login() test()然后呢......就成功啦......
恩,还是要再小结下,因为这个其实是我真正的第一次自己尝试去模拟登陆,所以花费了很多的时间,像上面我写到的很多思路其实可以说是套路,只要大家写多了,其实模拟登录这个东西也不是很难。我还想提到的一点是,爬虫能做很多事,而且比较有趣,练习爬虫的同时可以提升自己的python技,但是大家还是不要把太多时间放在爬虫上,把爬虫当做一种辅助工具来用就挺好的了。我呢,也要把爬虫稍微放放了,自己终于要开始学 自然语言处理 了,好兴奋!!!














 1479
1479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









