







独立成分分析(ICA)
其他与openCV中PCA算法类似的降维方式还有scikit-learn中的ICA。
from sklearn import decomposition跟前面提到的一样,我们还是使用fit_transform 函数来训练模型。
ica = decomposition.FastICA()
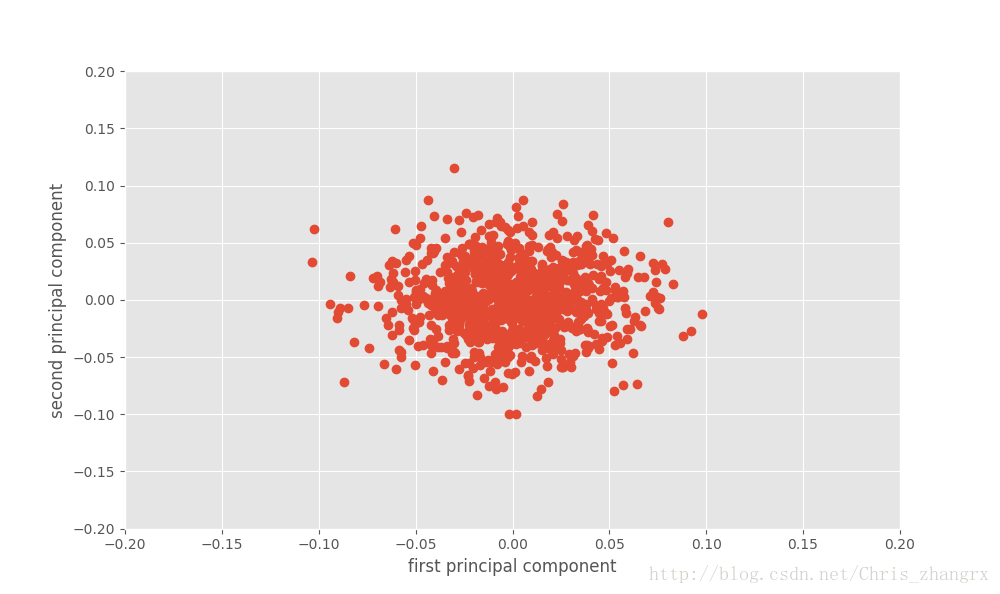
X2 = ica.fit_transform(X)然后我们就可以将输出结果可视化出来:
plt.figure(figsize=(10,6))
plt.plot(X2[:,0],X2[:,1],'o')
plt.xlabel('first principal component')
plt.ylabel('second principal component')
plt.axis([-0.2,0.2,-0.2,0.2])
plt.show()输出结果为:
非负矩阵分解(NMF)
使用此方法唯一的限制是,数据矩阵中的元素都是非负的
nmf = decomposition.NMF()
X2 = nmf.fit_transform(X)
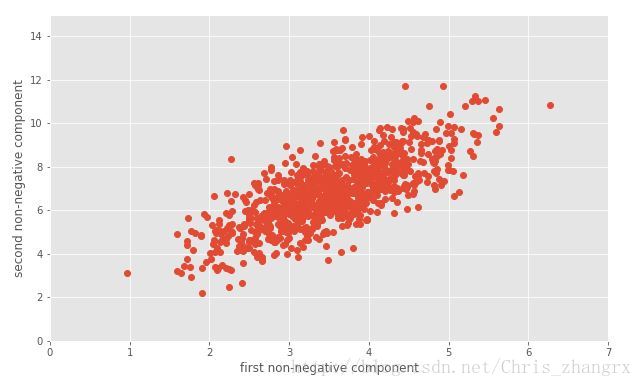
#可视化
plt.figure(figsize=(10,6))
plt.plot(X2[:,0],X2[:,1],'o')
plt.xlabel('first principal component')
plt.ylabel('second principal component')
plt.axis([0,7,0,15])
plt.show()输出结果为:
表示类型变量
类型特征所带来的问题就是它们不是连续变化的,这就给数字表示变量带来了困难。例如一根香蕉不是绿的就是黄的,不可能两种都有;一个产品是属于服装部门还是属于书籍部门,但是很少同属于两个部门… 等等
首先以一些机器学习和人工智能的先辈们的信息为例,加入我们有如下信息:
data = [
{'name':'Alan Turing','born':1912,'died':1954},
{'name':'Herbert A.Simon','born':1916,'died':2001},
{'name': 'Jacek Karpinski', 'born': 1927, 'died': 2010},
{'name': 'J.C.R. Licklider', 'born': 1915, 'died': 1990},
{'name': 'Marvin Minsky', 'born': 1927, 'died': 2016},
]当我们想给以上信息编码时,若使用下面的方式好像是可行的,但是从机器学习的角度却不可行。
{'Alan Turing': 1,
'Herbert A. Simon': 2,
'Jacek Karpinsky': 3,
'J.C.R. Licklider': 4,
'Marvin Minsky': 5};一种快速的方法就是使用sklearn中的DictVectorizer 也叫独热编码(one-hot encoding),使用方式就是将一个包含数据的字典输入到fit_transform() 里面
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer(sparse=False, dtype=int)
vec.fit_transform(data)
# 显示出各数据对应的特征名称
print(vec.get_feature_names())输出结果是:

所以第一行的意思可以理解为: ‘born’=1912, ‘died’=1954, ‘Alan Turing’=1, ‘Herbert A. Simon’=0, ‘J.C.R Licklider’=0, ‘Jacek Karpinsik’=0, and ‘Marvin Minsky’=0. 后面的数据以此类推。
表示文本特征
sample = [
'feature engineering',
'feature selection',
'feature extraction'
]想要给上面的文本信息打标签,最简单的方法就是使用单词序号编码,即给不同的单词表上序号,在sklearn中我们可以使用CountVectorizer 去实现它。
from sklearn import feature_extraction
vec=feature_extraction.text.CountVectorizer()
X=vec.fit_transform(sample)
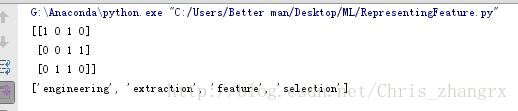
print(X.toarray())
print(vec.get_feature_names())默认X输出的是一个稀疏矩阵,我们 想很好的观察它需要将X转换成正常的矩阵,所以这里使用X.toarray() 函数来实现。我们依旧输出特征的名称:
但是这种方法的一个弊端就是我们可能会放太多的权重在出现频率高的单词上面,我们使用一种叫做 frequency-inverse document frequency(TF-IDF):
from sklearn.feature_extraction.text import TfidfVectorizer
vec = TfidfVectorizer()
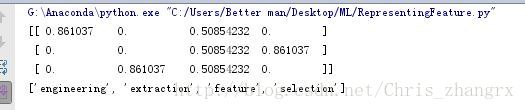
X = vec.fit_transform(sample)
X.toarray()输出结果为:














 2174
2174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









