






文本目录
1.rnn模型
2.LSTM网络
3.代码的实现
3.1旧版本实现
3.2新版本实现
1.rnn模型介绍
RNN 是包含循环的网络,允许信息的持久化
具体的参考模型图: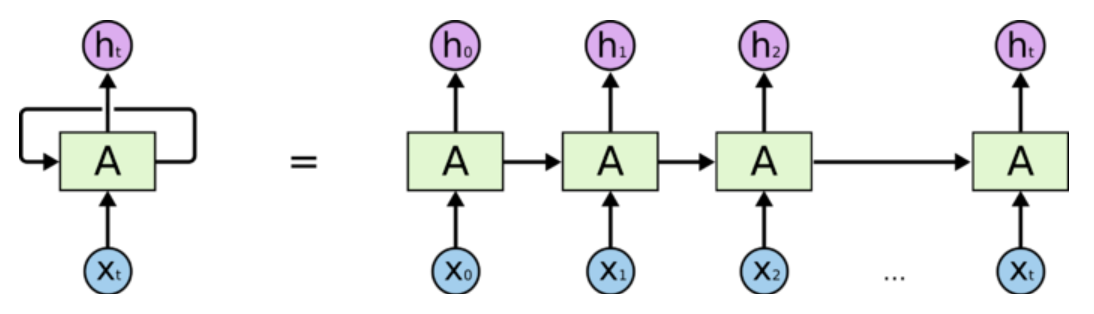
2.LSTM网络
Long Short Term 网络—— 一般就叫做 LSTM ——是一种 RNN 特殊的类型,可以学习长期依赖信息。LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。
具体的模型介绍和知识点请参考简书的一篇文章理解 LSTM 网络。
3.具体的实现代码
3.1旧版本实现
理解LSTM网络最后看一遍这个代码。对于内部的结构和工作方式都能有比较好的了解。具体的代码如下:
import tensorflow as tf
import numpy as np
sess = tf.InteractiveSession()
#载入数据
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('mnist/', one_hot=True)
#定义参数和变量
learning_rate = 0.001
batch_size = 128
n_input = 28
n_steps = 28
n_hidden = 128
n_classes = 10
x = tf.placeholder(tf.float32, [None, n_steps, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
def RNN(x, n_steps, n_input, n_hidden, n_classes):
# Parameters:
# Input gate: input, previous output, and bias
ix = tf.Variable(tf.truncated_normal([n_input, n_hidden], -0.1, 0.1))
im = tf.Variable(tf.truncated_normal([n_hidden, n_hidden], -0.1, 0.1))
ib = tf.Variable(tf.zeros([1, n_hidden]))
# Forget gate: input, previous output, and bias
fx = tf.Variable(tf.truncated_normal([n_input, n_hidden], -0.1, 0.1))
fm = tf.Variable(tf.truncated_normal([n_hidden, n_hidden], -0.1, 0.1))
fb = tf.Variable(tf.zeros([1, n_hidden]))
# Memory cell: input, state, and bias
cx = tf.Variable(tf.truncated_normal([n_input, n_hidden], -0.1, 0.1))
cm = tf.Variable(tf.truncated_normal([n_hidden, n_hidden], -0.1, 0.1))
cb = tf.Variable(tf.zeros([1, n_hidden]))
# Output gate: input, previous output, and bias
ox = tf.Variable(tf.truncated_normal([n_input, n_hidden], -0.1, 0.1))
om = tf.Variable(tf.truncated_normal([n_hidden, n_hidden], -0.1, 0.1))
ob = tf.Variable(tf.zeros([1, n_hidden]))
# Classifier weights and biases
w = tf.Variable(tf.truncated_normal([n_hidden, n_classes]))
b = tf.Variable(tf.zeros([n_classes]))
# Definition of the cell computation
def lstm_cell(i, o, state):
input_gate = tf.sigmoid(tf.matmul(i, ix) + tf.matmul(o, im) + ib)
forget_gate = tf.sigmoid(tf.matmul(i, fx) + tf.matmul(o, fm) + fb)
update = tf.tanh(tf.matmul(i, cx) + tf.matmul(o, cm) + cb)
state = forget_gate * state + input_gate * update
output_gate = tf.sigmoid(tf.matmul(i, ox) + tf.matmul(o, om) + ob)
return output_gate * tf.tanh(state), state
# Unrolled LSTM loop
outputs = list()
state = tf.Variable(tf.zeros([batch_size, n_hidden]))
output = tf.Variable(tf.zeros([batch_size, n_hidden]))
# x shape: (batch_size, n_steps, n_input)
# desired shape: list of n_steps with element shape (batch_size, n_input)
x = tf.transpose(x, [1, 0, 2])
x = tf.reshape(x, [-1, n_input])
x = tf.split(0, n_steps, x)
for i in x:
output, state = lstm_cell(i, output, state)
outputs.append(output)
logits =tf.matmul(outputs[-1], w) + b
return logits
#使用RNN构建训练模型
pred = RNN(x, n_steps, n_input, n_hidden, n_classes)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initializing the variables
init = tf.global_variables_initializer()
#载入计算图
sess.run(init)
for step in range(20000):
batch_x, batch_y = mnist.train.next_batch(batch_size)
batch_x = batch_x.reshape((batch_size, n_steps, n_input))
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y})
if step % 50 == 0:
acc = sess.run(accuracy, feed_dict={x: batch_x, y: batch_y})
loss = sess.run(cost, feed_dict={x: batch_x, y: batch_y})
print "Iter " + str(step) + ", Minibatch Loss= " + "{:.6f}".format(loss) + ", Training Accuracy= " + "{:.5f}".format(acc)
print "Optimization Finished!"
#测试数据
# Calculate accuracy for 128 mnist test images
test_len = batch_size
test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input))
test_label = mnist.test.labels[:test_len]
print "Testing Accuracy:", sess.run(accuracy, feed_dict={x: test_data, y: test_label})
3.2新版本实现
但是最新版的tensorflow将这些都封装到函数中实现代码也变得很简洁,下面是1.4.0中的实现形式(github代码):
#!usr/bin/python
# -*- coding: utf-8 -*-
"""
Created on Sun Dec 10 19:49:08 2017
@author: caibo
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("Mnist_data/", one_hot=True)
# 数据图片是28*28的所以对于每个图片一行28个数据读取28行
n_inputs=28
max_time=28
lstm_size=100
n_classes=10
batch_size=100
n_batch=mnist.train.num_examples // batch_size
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
weights=tf.Variable(tf.truncated_normal([lstm_size,n_classes], stddev=0.1))
biases=tf.Variable(tf.constant(0.1, shape = [n_classes]))
def RNN(X,weights,biases):
#input(batch_size,max_time,n_inputs)
inputs =tf.reshape(X,[-1,max_time,n_inputs])
lstm_cell=tf.contrib.rnn.BasicLSTMCell(lstm_size)
outputs,final_state=tf.nn.dynamic_rnn(lstm_cell,inputs,dtype=tf.float32)
# final_state[0] 是cell state
# final_state[1] 是hidden state
results=tf.nn.softmax(tf.matmul(final_state[1],weights)+biases)
return results
prediction=RNN(x,weights,biases)
cross_entropy=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction))
train_step=tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction=tf.equal(tf.argmax(prediction,1),tf.argmax(y,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(3):
for batch in range(n_batch):
batch_xs,batch_ys=mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys})
acc=sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})
print ("Iter" + str(epoch) + "Test accuracy : " + str(acc))
talk is cheap ,show me the code















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









