






该系列将描述一些自然语言处理方面的技术,完整目录请点击这里。
这个教程,我们将要讨论语言模型的关键问题:给定一个语料库,我们如何学习到概率 p? 在这一部分,我们将利用马尔科夫模型来解决这个问题。
1.1 马尔科夫模型对于确定长度的序列问题
考虑一个随机变量序列,X1, X2, X3, ....,Xn。每个变量是有限集合 V中的任何值。我们假设,这个序列是一个确定长度的序列,长度为 n(比如,n = 100)。在下一节中,我们将介绍实现如何在 n 也是随机变量的情况下,来解决语言模型的问题。
那么我们的目标就是:当 n ≥ 1,xi ∈ V for i = 1,2, ..., n时,我们需要求的序列 x1, ...,xn 的联合概率:
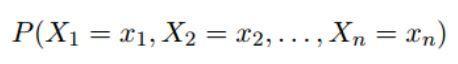
序列 x1, x2, ..., xn 的可能组成形式将达到 |V|^n 次,这是一个非常大的组合,如果我们直接采用上面的联合概率来计算,那么将是一个非常庞大的计算模型,所以我们需要构建一个更加压缩性的模型。
接下来,我们来介绍第一个压缩模型 —— 一阶马尔科夫模型,我们做出如下假设,这将大大简化模型的复杂度:
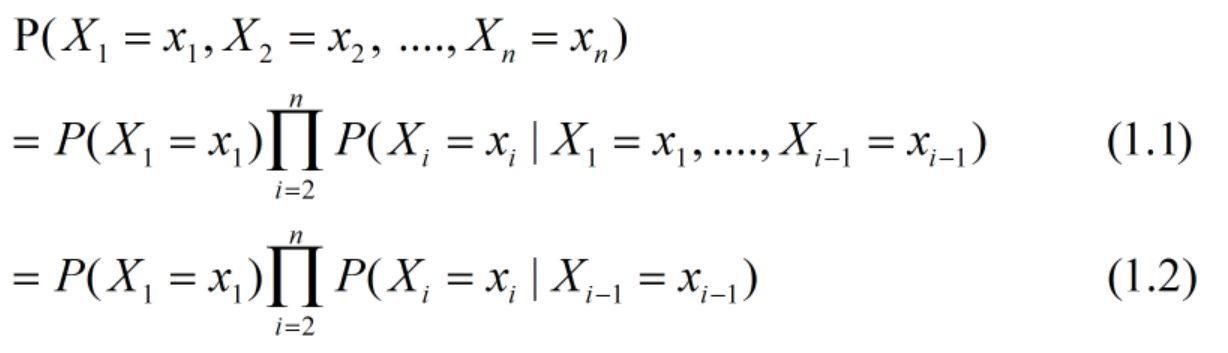
在第一步等式 1.1 中,这是链式法则推导得出的,任何的概率分布 P(X1 = x1 . . . Xn = xn) 都可以被写成这种形式。因此,在这一步中我们没有任何的假设条件。但在等式的第二步,我们进行了一些假设,具体形式如下:
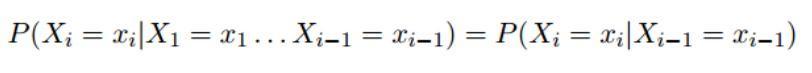
这就是一阶马尔科夫假设。我们假设序列的第 i 个变量只依赖于它前一个变量。更正式的,我们假设 Xi 独立于 X1, X2, ..., Xi-2,只依赖于 Xi-1。
接下来,我们介绍第二个压缩模型 —— 二阶马尔科夫模型,它是构成 trigram 语言模型的基础。二阶马尔科夫模型有一个稍微弱一点的假设,即我们假设每一个字只依赖于它前面的两个字,具体方程如下:
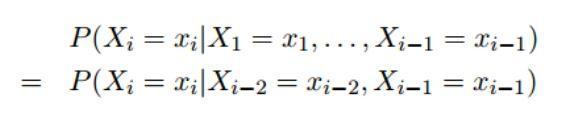
因此,我们可以将整个序列的概率写成:
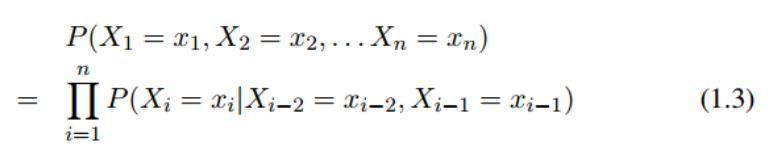
为了方便,我们假设 x0 = x-1 = ,其中 是句子中的一个特殊符号 start 。
1.2 马尔科夫模型用于长度可变序列
在上一部分中,我们假设序列的长度是确定的 n 。然而,在很多的应用中,序列的长度都是会发生变化的。也就是说,长度 n 是一个可变量。有很多种方法可以对可变长度序列进行建模,但在本节中,我们介绍一种语言模型的最常用方法。
这个方法非常简单:我们假设句子中的第 n 个字是 Xn,并且这个字是一个特殊符号 STOP ,这个符号只会出现在序列的最后。我们使用与以前完全相同的假设:比如,我们使用二阶马尔科夫假设,那么我们可以得到:
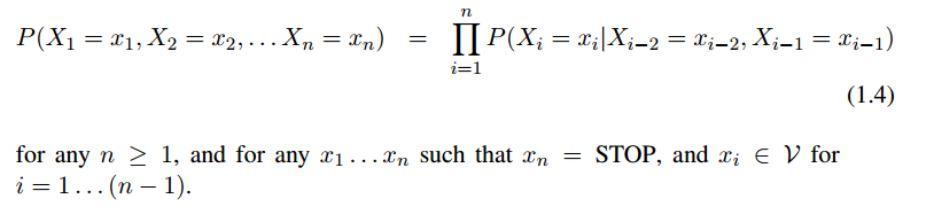
我们假设一个二阶马尔科夫过程,在每个步骤中,我们都生成一个 xi 的概率分布,如下:
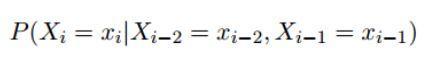
其中,xi 可以是 V 中的其中一个元素,也可以是最后一个特殊符号 STOP。如果我们计算到最后一个符号 STOP,那么就代表序列的结束。
更加正式的,句子生成的过程如下:

因此,我们现在有一个生成不同长度序列的模型了。















 1121
1121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









