






连接对象(Concatenating)
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)join有两个参数inner(内连)和outer(外连)
ignore_index:是否忽略索引,默认不忽略,此时会按照索引连接。
join_axes:使用哪个数据框的索引
keys:复合索引
横向连接
In [1]: df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3'],
...: 'C': ['C0', 'C1', 'C2', 'C3'],
...: 'D': ['D0', 'D1', 'D2', 'D3']},
...: index=[0, 1, 2, 3])
...:
In [8]: df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
...: 'D': ['D2', 'D3', 'D6', 'D7'],
...: 'F': ['F2', 'F3', 'F6', 'F7']},
...: index=[2, 3, 6, 7])
...:
result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])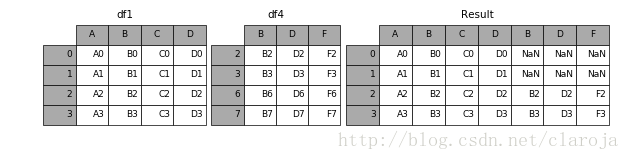
纵向连接
In [15]: result = pd.concat([df1, df4], ignore_index=True) 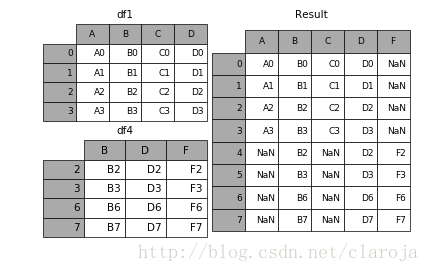
append函数更加有效率
数据库形式的连接(joining/merging)
这个语法是专门为那些使用SQL数据的人群设置的
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x', '_y'), copy=True, indicator=False)left:左数据表
right:右数据表
on:以哪一列为标准做联表,如果没有输入参数,则会以共有的索引作为依据
left_on:以左边的数据框作为join key
right_on:以右边的数据框作为join key
left_index:以左边的索引作为join key
right_index:以右边的索引作为join key
how:left right out inner,默认为inner
sort:通过join key对结果进行排序
suffixes:
copy:
indicator:
merge同时也是一个对象方法,对象默认是左联表。而join实例方法则是默认以索引做为连接方法。
In [38]: left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [39]: right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [40]: result = pd.merge(left, right, on='key')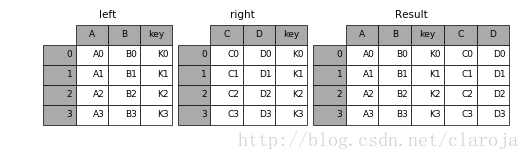
使用indicator可以监视连接的状态
In [48]: df1 = pd.DataFrame({'col1': [0, 1], 'col_left':['a', 'b']})
In [49]: df2 = pd.DataFrame({'col1': [1, 2, 2],'col_right':[2, 2, 2]})
In [50]: pd.merge(df1, df2, on='col1', how='outer', indicator=True)
Out[50]:
col1 col_left col_right _merge
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only














 7733
7733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









