







揭秘AI图像篡改检测:让恶意P图无处遁形
在这个数字时代,图像篡改已经变得非常普遍,这给我们的社会带来了许多负面影响。为了应对这一挑战,我们开发了一款AI图像篡改检测系统,该系统可以自动识别并标记出疑似篡改的区域,让恶意P图无处遁形。 用户只需要上传疑似篡改的图像,系统便会输出该图像疑似篡改的区域。这一技术的出现,无疑为我们的社会带来了巨大的帮助,可以帮助我们识别虚假信息,保护我们的网络安全。 然而,我们需要明确一点,我们的模型并不是万能的。虽然它在检测拼接的自然图像的时候具有较高的准确率,但是对于物体擦除或者人脸P图来说,结果稍显逊色,适用的场景有限。因此,在使用我们的系统时,用户需要有一定的心理准备,不能期望它能解决所有问题。 此外,用户自己训练的模型的效果与数据集高度相关。不一样的数据集训练得到的检测结果可能不同。因此,如果用户希望得到更好的检测结果,就需要准备更高质量、更符合实际需求的数据集。 总的来说,虽然我们的AI图像篡改检测系统还有许多需要改进的地方,但我们相信,随着技术的不断发展,它的能力会越来越强,能够更好地服务于我们的社会。
源码链接
详细复现过程请参考传知代码平台
项目源码、数据和预训练好的模型可从该文章下方附件获取。
一、背景及意义介绍
随着照相机、手机、平板电脑、摄像机等数码设备与Photoshop、美图秀秀等各种图片编辑软件的飞速发展,数字图像的生成与编辑已经变得非常容易,几乎人人都有能力生成、编辑大量的数字图像。这虽然方便了人们的生活,但也使图像篡改变得越来越容易,伪造图像也变得越来越不易察觉,甚至能够以假乱真。
日常生活中人们对图像进行拼接,往往是出于美化、娱乐的目的,这并不会带来不良影响,但是当图像在被恶意拼接篡改的情况下经过传播,就会引导人们对客观事物产生错误的判断,有时甚至会对社会和国家造成不良的影响。因此,图像拼接篡改检测在当今社会显得愈发重要。
2004年,小布什竞选时选用的宣传图片,实际上是将小布什的照片拼接到其他照片上得到的。虚假的拼接图像在选举时干扰了民众的决策,对选举的结果也造成了不小的影响。如图所示,上边是篡改前的图像,下边是经过篡改后的图像。

原始图片

篡改后
因此,研究相应的图像算法检测方法,用于判断图片是否经过人为编辑非常重要。图像篡改检测的研究和发展,能够降低造假图像给社会带来的各种不良影响,有助于维护公共信任秩序,打击一些不良的图片造假犯罪行为。
二、概述
本文通过解读并复现两篇论文,来揭秘AI图像篡改检测领域的相关研究。本文解读并复现的论文是《Image Manipulation Detection by Multi-View Multi-Scale Supervision》和《MVSS-Net: Multi-View Multi-Scale Supervised Networks for Image Manipulation Detection》,其中前者2021年发表于ICCV(International Conference on Computer Vision),而《MVSS-Net: Multi-View Multi-Scale Supervised Networks for Image Manipulation Detection》是对该会议论文的改进版本,2022年发表于TPAMI(IEEE Transactions on Pattern Analysis and Machine Intelligence)期刊。众所周知,ICCV会议和TPAMI期刊都是计算机人工智能领域的顶会和顶刊。
三、论文背景
研究背景:
图像篡改技术的发展:随着图像编辑工具的普及,图像篡改变得越来越容易,而人眼很难分辨篡改图像与真实图像。这对信息安全、法律取证等领域提出了挑战。
-
传统篡改检测方法的局限:早期的篡改检测方法主要基于手工特征,如SIFT、LBP等,泛化能力有限。深度学习方法虽然提高了性能,但主要基于单一视角和尺度,忽略了篡改痕迹的多样性。
-
多视角多尺度学习的潜力:不同视角(如空域、频域)和尺度的特征可能包含互补的篡改线索。联合利用这些信息,有望进一步提升篡改检测性能。
研究意义:
-
技术创新:
-
提出了一种新的多视角多尺度学习范式,开创了篡改检测的新思路。
-
在特征提取、融合、监督学习等方面进行了精巧设计,实现了高效的多视角多尺度表示学习。 性能提升:
-
在多个公开数据集上取得了领先的性能,刷新了篡改检测的技术水平。
-
多视角多尺度学习显著优于单一视角或尺度,证明了融合互补信息的优势。
-
应用价值:
-
在信息安全、法律取证、新闻真实性甄别等领域具有广阔的应用前景。
-
提高了篡改图像检测的准确率,有助于遏制虚假信息的传播,维护网络空间的真实可信。
-
启发意义:
-
多视角多尺度学习可以推广到其他计算机视觉任务,如目标检测、语义分割等。
-
启发我们要从多角度理解问题,挖掘数据中的丰富信息,设计巧妙的融合机制,提升算法性能。
四、论文思路
这两篇论文的核心思路是利用多视角和多尺度的方式来监督图像篡改检测模型的训练。传统的方法通常只关注整个图像,而这些工作认为不同的区域和尺度对于检测也很重要。 具体来说,多视角是指从多个角度(视角)观察图像,比如全局视角和局部视角。全局视角关注整个图像,局部视角关注图像的局部区域。多尺度则是在不同的分辨率下观察图像。通过多视角多尺度的监督,模型能够同时学习到全局和局部的语义特征,并在不同尺度下捕获细节信息,从而提高检测性能。
-
多视角学习: 篡改痕迹在RGB空间、噪声域、频域有不同的表现。单一视角难以全面捕捉,因此需要多视角学习。
-
多尺度监督: 篡改痕迹在不同尺度表现不同。小尺度注重局部细节,大尺度注重全局一致性。多尺度监督有助于融合不同尺度的特征。
-
全局与局部建模: 全局特征提供场景级别的信息,局部特征关注像素级别的变化。两者的结合可以更准确地定位篡改区域。
五、模型结构
这两篇论文的模型结构都是基于卷积神经网络,但做了相应改进。 ICCV的会议论文提出了一种新的金字塔特征融合模块,将不同尺度的特征进行融合。TPAMI的期刊论文在此基础上,引入了一种新的注意力模块,用于学习视角之间的交互关系。同时还设计了一种新的金字塔池化模块,以更好地融合多尺度特征。具体来说,可以从以下几个方面描述模型结构:
-
骨干网络: ICCV论文采用Res2Net,TPAMI论文采用SwinTransformer,通过更强的骨干提取多尺度特征。
-
多视角特征提取:
-
RGB空间:骨干网络提取特征。
-
噪声域:用SRM滤波器提取噪声残差特征。
-
频域:用DCT变换提取频域特征。
-
特征融合:
-
ICCV版论文:在每个尺度concat三个视角的特征图,再通过卷积层融合。
-
TPAMI版论文:引入自注意力机制,对多视角特征加权融合,提高表示能力。
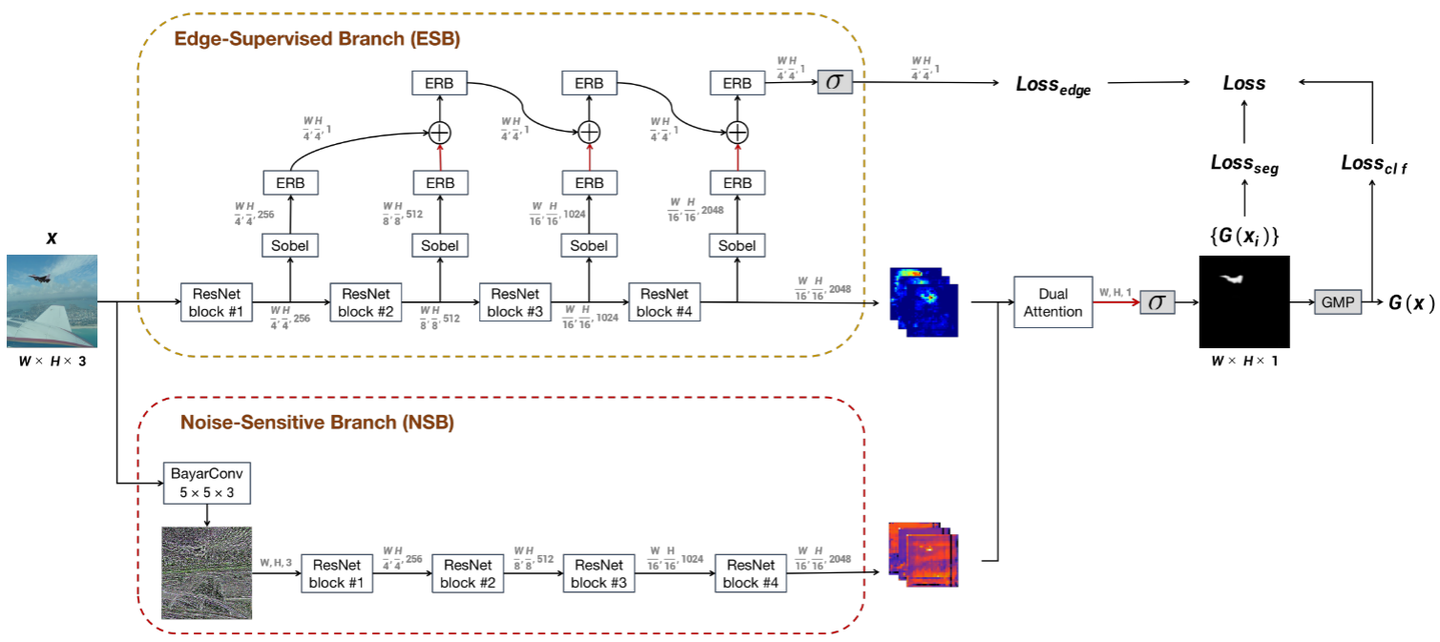
模型框架图
六、损失函数
为了实现多视角多尺度监督,这两篇论文都设计了相应的损失函数。ICCV论文只使用多尺度交叉熵损失,TPAMI论文将以下两种损失相加作为总损失。
-
多尺度交叉熵损失:在每个尺度上计算预测结果与真值图的交叉熵损失,再加权求和。
-
多尺度F1损失:在每个尺度上计算预测结果的F1分数,将其转化为损失函数,再加权求和。F1损失可以缓解类别不平衡问题。
七、复现过程(重要)
在图像篡改检测的研究中,先看实验结果图,Images列展示的是被篡改的图像,而Mask列则显示的是对应的篡改区域。这类研究的核心目标是最准确地定位出图像中的篡改部分。从图像分类的角度来理解,这个问题可以被视为一个逐像素的二分类任务。具体来说,对于被篡改的图像A中的每一个像素点(x,y),模型需要判断该像素点是否被篡改。如果模型判断一个像素点被篡改,那么它就会输出1;如果判断为未篡改,则输出0。这样,所有像素点的0和1输出组合起来,就形成了一张与原始图像A分辨率相同的Mask图像。在这张Mask图像上,白色区域代表了图像中被篡改的位置,而黑色区域则表示未被篡改的部分。通过这种方式,篡改检测模型能够生成一幅精确的篡改区域图,帮助用户识别和定位图像中的不真实内容。

添加图片注释,不超过 140 字(可选)
由于原论文只给出了推理代码,而无训练代码,因此本文主要复现其训练过程,达到如上图所示结果。接下来就是复现步骤,可以从以下几个过程分解复现(只给出关键代码):
步骤1:
搭建一个最常规的Pytorch训练框架,包括数据集的加载,迭代训练,这一部分的代码可以在Pytorch官网的教程文档中找到;
以Pytorch官网教程中给的以卷积神经网络识别mnist手写数字为例,部分的训练框架如下:
# 定义数据转换步骤,包括转换为张量,以及标准化处理
transform=transforms.Compose([
transforms.ToTensor(), # 将图片转换为PyTorch张量
transforms.Normalize((0.1307,), (0.3081,)) # 根据MNIST数据集的均值和标准差进行标准化
])
# 加载训练集,如果不存在则下载,并应用上述转换
dataset1 = datasets.MNIST('../data', train=True, download=True,
transform=transform)
# 加载测试集,并应用上述转换
dataset2 = datasets.MNIST('../data', train=False,
transform=transform)
# 创建训练数据加载器,使用train_kwargs中的参数
train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs)
# 创建测试数据加载器,使用test_kwargs中的参数
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
# 实例化模型,并将其移动到指定设备
model = Net().to(device)
# 实例化Adadelta优化器,传入模型参数和学习率
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
# 实例化学习率调度器,按照固定的步长和衰减因子调整学习率
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
# 开始训练循环,对于每个epoch
for epoch in range(1, args.epochs + 1):
# 执行训练过程
train(args, model, device, train_loader, optimizer, epoch)
# 执行测试过程
test(model, device, test_loader)
# 调度器步进,根据策略调整学习率
scheduler.step()
# 如果指定了保存模型,则保存模型的参数
if args.save_model:
torch.save(model.state_dict(), "mnist_cnn.pt")
def train(args, model, device, train_loader, optimizer, epoch):
# 设置模型为训练模式
model.train()
# 遍历训练数据集的每个批次
for batch_idx, (data, target) in enumerate(train_loader):
# 将数据和目标发送到计算设备(如GPU)
data, target = data.to(device), target.to(device)
# 清除优化器的梯度
optimizer.zero_grad()
# 通过模型处理数据得到输出
output = model(data)
# 计算输出和目标之间的负对数似然损失
loss = F.nll_loss(output, target)
# 反向传播损失以计算每个参数的梯度
loss.backward()
# 根据梯度更新模型的参数
optimizer.step()
# 按照设定的间隔打印训练状态信息
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 如果是干运行(仅用于测试),则在第一个批次后中断训练循环
if args.dry_run:
break
步骤2:
搭建好基础的训练框架好,需要将官网的数据集加载过程修改为自定义的数据集类,由于图像篡改检测的ground-truth label是一张mask图像,所以需要将原先数据集中的label由代表具体类别的数值改为mask图像,且需要和被篡改图像一一对应,顺序不能乱。
首先需要先进行一下文件名的处理:篡改图像文件夹和其对应的mask文件夹需要放在同一个目录下,然后篡改图像文件名需要和应的mask文件名一致,如文件结构为:
—Dataset
--------forgery image dir
------------------1.jpg
------------------2.jpg
------------------…
--------mask image dir
------------------1.png
------------------2.png
------------------…
然后再用以下加载数据集的代码读取图像文件以及mask图像:
# 导入相关库
from torch.utils.data import Dataset
from torchvision.utils import save_image
import os
import numpy as np
from torchvision import transforms as T
import albumentations as A
from albumentations.pytorch import ToTensorV2
import cv2
import torch
# 设置图片的最大尺寸
max_size_w = 512
max_size_h = 512
# 定义预处理掩码的函数
def preprocess_mask(mask):
mask = mask.astype(np.float32) # 将掩码转换为浮点数类型
mask = mask[:,:,0:1] # 选择掩码的第一个通道
mask[mask<=127.5] = 0.0 # 将掩码中小于等于127.5的值设置为0.0
mask[mask>127.5] = 255. # 将掩码中大于127.5的值设置为255.
return mask
# 自定义UNet数据集类
class UNetDataset(Dataset):
def __init__(self, dir_train, dir_mask,train_transform=None,val_transform=None,mode = 'train'):
self.dirTrain = dir_train # 训练图片的目录
self.dirMask = dir_mask # 掩码图片的目录
self.mode = mode # 数据集模式(训练、验证或预测)
# 获取训练图片的文件路径列表
self.dataTrain = [os.path.join(self.dirTrain, filename)
for filename in os.listdir(self.dirTrain)
if filename.endswith('.jpg') or filename.endswith('.png') or filename.endswith('.tif')or filename.endswith('.jpeg') ]
self.dataTrain.sort() # 对文件路径列表进行排序
# 获取掩码图片的文件路径列表
self.dataMask = [os.path.join(self.dirMask, filename)
for filename in os.listdir(self.dirMask)
if filename.endswith('.jpg') or filename.endswith('.png') or filename.endswith('.tif') or filename.endswith('.jpeg') ]
self.dataMask.sort() # 对文件路径列表进行排序
self.trainDataSize = len(self.dataTrain) # 训练图片的数量
self.maskDataSize = len(self.dataMask) # 掩码图片的数量
self.transform1 = T.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)) # 归一化变换
self.toTensor = A.Compose([ToTensorV2()]) # 转换为PyTorch张量的变换
# 如果提供了训练变换,则使用提供的变换,否则使用默认的训练变换
if train_transform is not None:
self.train_transform = train_transform
else:
self.train_transform = A.Compose(
[
A.Resize(max_size_h,max_size_w,p=1), # 调整图片尺寸
A.VerticalFlip(p=0.2), # 随机垂直翻转
A.HorizontalFlip(p = 0.2), # 随机水平翻转
ToTensorV2(), # 转换为PyTorch张量
], is_check_shapes=False
)
# 如果提供了验证变换,则使用提供的变换,否则使用默认的验证变换
if val_transform is not None:
self.val_transform = val_transform
else:
self.val_transform = A.Compose(
[
A.Resize(max_size_h,max_size_w,p=1), # 调整图片尺寸
ToTensorV2(), # 转换为PyTorch张量
], is_check_shapes=False
)
self.kernel = np.ones((4, 4), np.uint8) # 用于形态学操作的核
self.feature_chan = [128,64,32,16] # 特征图的通道数列表
def __getitem__(self, index):
assert self.trainDataSize == self.maskDataSize # 确认训练图片和掩码图片的数量一致
image_filename = self.dataTrain[index] # 获取图片的文件路径
image = cv2.imread(image_filename) # 读取图片
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 将图片从BGR转换为RGB
mask_filename = self.dataMask[index] # 获取掩码的文件路径
mask = cv2.imread(mask_filename) # 读取掩码
mask = cv2.cvtColor(mask, cv2.COLOR_BGR2RGB) # 将掩码从BGR转换为RGB
mask = preprocess_mask(mask) # 预处理掩码
if self.mode=='train':
return image, final_mask,image_filename
if self.mode=='val':
return image, final_mask,image_filename
if self.mode=='predict':
return image, final_mask,w,h,image_filename
def __len__(self):
return self.trainDataSize步骤3:
定义MVSS模型(此模型在原论文中有给出),并将第一步中的卷积神经网络模型model训练模型替换为MVSS模型。
def get_mvss(backbone='resnet50', pretrained_base=True, nclass=1, sobel=True, n_input=3, constrain=True, **kwargs):
model = MVSSNet(nclass, backbone=backbone,
pretrained_base=pretrained_base,
sobel=sobel,
n_input=n_input,
constrain=constrain,
**kwargs)
return model
class MVSSNet(ResNet50):
def __init__(self, nclass, aux=False, sobel=False, constrain=False, n_input=3, **kwargs):
super(MVSSNet, self).__init__(pretrained=True, n_input=n_input)
self.num_class = nclass
self.aux = aux
self.__setattr__('exclusive', ['head'])
self.upsample = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
self.upsample_4 = nn.Upsample(scale_factor=4, mode="bilinear", align_corners=True)
self.sobel = sobel
self.constrain = constrain
self.erb_db_1 = ERB(256, self.num_class)
self.erb_db_2 = ERB(512, self.num_class)
self.erb_db_3 = ERB(1024, self.num_class)
self.erb_db_4 = ERB(2048, self.num_class)
self.erb_trans_1 = ERB(self.num_class, self.num_class)
self.erb_trans_2 = ERB(self.num_class, self.num_class)
self.erb_trans_3 = ERB(self.num_class, self.num_class)
if self.sobel:
print("----------use sobel-------------")
self.sobel_x1, self.sobel_y1 = get_sobel(256, 1)
self.sobel_x2, self.sobel_y2 = get_sobel(512, 1)
self.sobel_x3, self.sobel_y3 = get_sobel(1024, 1)
self.sobel_x4, self.sobel_y4 = get_sobel(2048, 1)
if self.constrain:
print("----------use constrain-------------")
self.noise_extractor = ResNet50(n_input=3, pretrained=True)
self.constrain_conv = BayarConv2d(in_channels=1, out_channels=3, padding=2)
self.head = _DAHead(2048+2048, self.num_class, aux, **kwargs)
else:
self.head = _DAHead(2048, self.num_class, aux, **kwargs)
def forward(self, x):
size = x.size()[2:]
input_ = x.clone()
feature_map, _ = self.base_forward(input_)
c1, c2, c3, c4 = feature_map
if self.constrain:
x = rgb2gray(x)
x = self.constrain_conv(x)
constrain_features, _ = self.noise_extractor.base_forward(x)
constrain_feature = constrain_features[-1]
c4 = torch.cat([c4, constrain_feature], dim=1)
x = self.head(c4)
x0 = F.interpolate(x[0], size, mode='bilinear', align_corners=True)
return x0步骤4:
定义损失函数,本文用图像分类中加权的BCE Loss和Dice Loss来对模型进行训练。
import torch.nn.functional as F
import torch.nn as nn
######## WeightedBCE Loss ###########
class WeightedBCE(nn.Module):
def __init__(self, weights=[0.2, 0.8]):
super(WeightedBCE, self).__init__()
self.weights = weights
def forward(self, logit_pixel, truth_pixel):
logit = logit_pixel.reshape(-1)
truth = truth_pixel.reshape(-1)
assert(logit.shape==truth.shape)
loss = F.binary_cross_entropy(logit, truth, reduction='mean')
pos = (truth>=0.35).float()
neg = (truth<0.35).float()
pos_weight = pos.sum().item() + 1e-12
neg_weight = neg.sum().item() + 1e-12
loss = (self.weights[0]*pos*loss/pos_weight + self.weights[1]*neg*loss/neg_weight).sum()
return loss
######## WeightedDice Loss ###########
class WeightedDiceLoss(nn.Module):
def __init__(self, weights=[0.5, 0.5]): # W_pos=0.8, W_neg=0.2
super(WeightedDiceLoss, self).__init__()
self.weights = weights
def forward(self, logit, truth, smooth=1e-5):
batch_size = len(logit)
logit = logit.reshape(batch_size,-1)
truth = truth.reshape(batch_size,-1)
assert(logit.shape==truth.shape)
p = logit.view(batch_size,-1)
t = truth.view(batch_size,-1)
w = truth.detach()
w = w*(self.weights[1]-self.weights[0])+self.weights[0]
p = w*(p)
t = w*(t)
intersection = (p * t).sum(-1)
union = (p * p).sum(-1) + (t * t).sum(-1)
dice = 1 - (2*intersection + smooth) / (union +smooth)
loss = dice.mean()
return loss
######## Total Loss = WeightedDice Loss + WeightedBCE###########
class WeightedDiceBCE(nn.Module):
def __init__(self,dice_weight=1,BCE_weight=1):
super(WeightedDiceBCE, self).__init__()
self.BCE_loss = WeightedBCE(weights=[0.8, 0.2])
self.dice_loss = WeightedDiceLoss(weights=[0.5, 0.5])
self.BCE_weight = BCE_weight
self.lovasz_weight = 0
self.dice_weight = dice_weight
def forward(self, inputs, targets):
dice = self.dice_loss(inputs, targets)
BCE = self.BCE_loss(inputs, targets)
dice_BCE_loss = self.dice_weight * dice + self.BCE_weight * BCE
return dice_BCE_loss步骤5:
最后的训练框架就会变为:
#=============================数据集设置===================================
# 训练图片目录
img_dir ='./test_data/train_img'
# 训练掩码目录
gt_mask_dir ='./test_data/train_mask'
# =============================数据集设置===================================
# 创建训练数据集
train_dataset = UNetDataset(img_dir, gt_mask_dir, mode='train')
# 创建训练数据加载器
train_loader = DataLoader(
train_dataset, # 使用之前定义的UNetDataset
batch_size=params["batch_size"], # 批处理大小
shuffle=True, # 打乱数据
num_workers=params["num_workers"], # 加载数据的工作进程数
pin_memory=True, # 将数据加载到CUDA中的固定内存中
drop_last=True, # 如果最后一个批次的数据量小于batch_size,则丢弃该批次
)
# 获取模型,使用resnet50作为骨干网络,预训练基础模型,输出类别数为1,使用Sobel算子,应用约束,输入通道数为3
model = get_mvss(backbone='resnet50',
pretrained_base=True,
nclass=1,
sobel=True,
constrain=True,
n_input=3,
)
# 实例化优化器,使用AdamW算法,传入模型参数和学习率
optimizer = torch.optim.AdamW(model.parameters(), lr=params["lr"])
# 实例化损失函数,使用加权Dice和BCE损失,权重分别为0.3和0.7,并将其移动到GPU上
criterion_1 = WeightedDiceBCE(dice_weight=0.3,BCE_weight=0.7).cuda()
# 开始训练循环,从epoch_start开始,到设定的epochs结束
for epoch in range(epoch_start, params["epochs"] + 1):
# 将模型设置为训练模式
model.train()
# 创建进度条,显示处理过程,颜色为青色
stream = tqdm(train_loader,desc='processing',colour='CYAN')
# 遍历数据加载器中的每个批次
for i, (images, masks,_) in enumerate(stream, start=1):
# 将图片和掩码发送到GPU上,非阻塞式传输
images = images.cuda(non_blocking=params['non_blocking_'])
masks = masks.cuda(non_blocking=params['non_blocking_'])
# 通过模型处理图片得到输出
reg_outs = model(images)
# 应用Sigmoid激活函数
reg_outs = torch.sigmoid(reg_outs)
# 计算损失
loss_region = criterion1(reg_outs, masks)
# 清除优化器的梯度
optimizer.zero_grad()
# 反向传播损失
loss_region.backward()
# 更新模型的参数
optimizer.step()使用附件代码以及附件数据集(附件txt文件中附上数据集下载地址),运行python main.py就可以一键实现对图像篡改检测定位的训练。如果想要直接得到结果,可以使用附件txt中提供的作者预训练好的模型,运行test.py,在其中修改测试数据集路径,或者把图像及其对应的mask图像放到./test_dataset/val_img目录下以及./test_dataset/val_mask目录下,要求两个目录中都有文件名相同的文件,如果测试集没有mask图像,则将274行代码val_gt_mask_dir=xxx也设置为与val_img_dir = xxx一样即可。预测所得图像在./test_dataset/predict_results目录中。
此外,还开发了一个桌面版的GUI界面和一个网页版的web供算法的可视化演示。 首先是桌面版的GUI界面,运行app.py,就会出来一个界面,点击请选择待检测图像按钮,在test_data的img文件夹中存放着几张例子图像,其对应的篡改区域可以见同一个目录下的mask文件夹。选择图像后,点击OK后界面左边会加载显示疑似篡改图像,点击篡改检测按钮,稍等几秒后界面右边就会显示疑似的篡改P图区域。值得一提的是,该界面使用了热力图的形式来标注篡改区域,越接近蓝色则表明其不是篡改区域,越接近红色则表明其是篡改区域。除了可以检测一般的P图,它还可以检测聊天截图中可能存在的篡改区域。 其次是网页版的web,运行python web.py文件,可以在浏览器中通过与以上类似的操作,得到一张篡改检测的图像。

演示效果1

演示效果2

演示效果3
部署方式
环境要求:python 3.7
torch==1.13.1
torchvision==0.14.1
segmentation-models-pytorch==0.3.3
opencv-python-headless==4.9.0.80
Pillow==9.5.0
imageio==2.31.2
dearpygui>=1.3.0
scikit-learn==1.0.2
参考文献
[1] Chen, X., Dong, C., Ji, J., Cao, J., & Li, X. (2021). Image Manipulation Detection by Multi-View Multi-Scale Supervision. 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 14165-14173.
[2] Dong, C., Chen, X., Hu, R., Cao, J., & Li, X. (2021). MVSS-Net: Multi-View Multi-Scale Supervised Networks for Image Manipulation Detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45, 3539-3553.















 1387
1387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









