






原文:https://www.analyticsvidhya.com/blog/2016/04/complete-tutorial-tree-based-modeling-scratch-in-python/
Introduction
基于树的学习算法,一贯被认为是最好的、最有用的监督学习方法。这种方法可以有效的保证预测模型的高准确度,稳定性和易理解性。不同于线性模型算法,他们可以很好的反映非线性关系。他们可以很容易的使用在需要解决的任何类型的问题上(分类或回归)。
像决策树算法,随机森林,梯度推进等算法,已经被广泛使用在解决各种类型的数据科学问题当中。因此,对于每一个数据分析者而言(当然也包括菜鸟啦),学习这些算法原理并在实践中使用这些模型,是很有帮助和必要的。
该教程的只要意图,就是帮助那些新人摆脱" 抓耳挠腮,无处下手 “ 的状态,帮助他们从基础开始,逐步打开学习的大门。希望大家能在完成本轮学习之后,能够熟练的使用基本的算法逻辑和构建预测模型。
注意: 本教程并不需要任何的机器算法基础。但是基本的 R 或者Python的编程基础还是有一定的要求。
如果需要,可进入学习 full tutorial in R and full tutorial in Python.
Table of Contents
-
- What is a Decision Tree? How does it work?
- Regression Trees vs Classification Trees
- How does a tree decide where to split?
- What are the key parameters of model building and how can we avoid over-fitting in decision trees?
- Are tree based models better than linear models?
- Working with Decision Trees in R and Python
- What are the ensemble methods of trees based model?
- What is Bagging? How does it work?
- What is Random Forest ? How does it work?
- What is Boosting ? How does it work?
- Which is more powerful: GBM or Xgboost?
- Working with GBM in R and Python
- Working with Xgboost in R and Python
- Where to Practice ?
1. 什么是决策树?它如何工作?
决策树是一种监督学习算法(具有预先定义的目标变量),在分类问题上作用效果明显。它适合于分类和连续输入、输出变量。在算法过程中,我们会基于最有效的分离器或者区分器,将样本分为两个或多个同类集合(或者子样本集),如下图。
示例:
我们有一个包含有30位同学的样本集,他们都有单个不同的标签:性别(男,女),班级(IX/X)和身高(5 to 6 ft)。他们其中有15人在课余时间是喜欢打板球的。那么现在,我们想构建一个模型,来预测一下,那些同学在课余时间喜欢打板球!在这个问题中,我们需要基于这三个输入中最显著的特征的输入变量,来划分所有的同学,进而得到问题的答案。
通过树形图,我们可以看到,基于每种变量和其取值,我们可以将同学分成不同类别的样本组,每组之间都是完全不同类别的。如下图,对比可以发现,性别标签,比其他两个标签能够鉴别出最好的同类集。
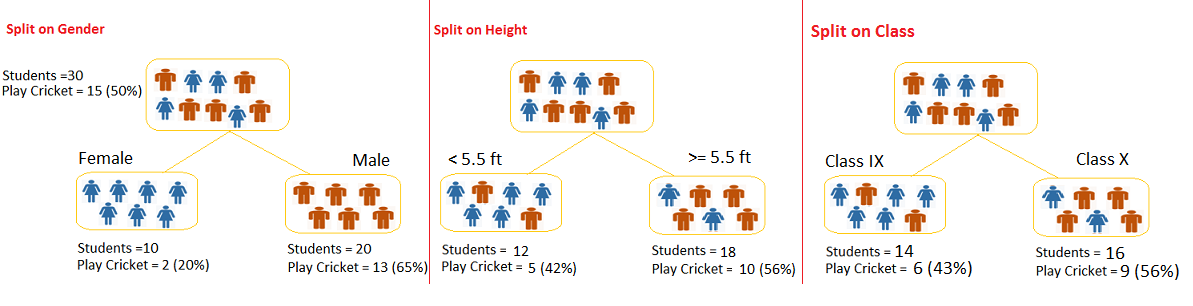
如上所述,决策树能够标识出最有效的变量和取值,这些变量和值能够很好的区分原始样本。那么问题来了,它是如何从所有标签中确定这个最有效的标签的呢?为了解决这个问题,决策树算法使用的多种算法,下面我们就要讨论一下这些算法。
决策树的类型
决策树的类型,是基于我们已有的目标变量的类型而定的,共有两类:
- Categorical Variable Decision Tree: 离散变量决策树,顾名思义,他的目标变量是离散状态。比如:上面提到的学生的例子,目标变量就是“学生玩板球或者不玩”,也就是两种状态:是,否。
- Continuous Variable Decision Tree: 连续变量决策树,顾名思义,他的目标变量是连续状态。举个例子:假如我们想预测一个客户是否会继续给他的保险公司缴纳保金(当然这个结果是离线的,即,交或者否)。但是我们发现对所有的客户,工资输入是影响交否的一个重要变来变量,但是保险公司去没有所有用户的工资细节信息。因此,我们可基于用户的职业,产品以及其他各式各样的变量,来构建一个决策树来预测客户的输入决策树。这个例子中,我们的预测值(工资)就是个连续变量了。
决策树术语
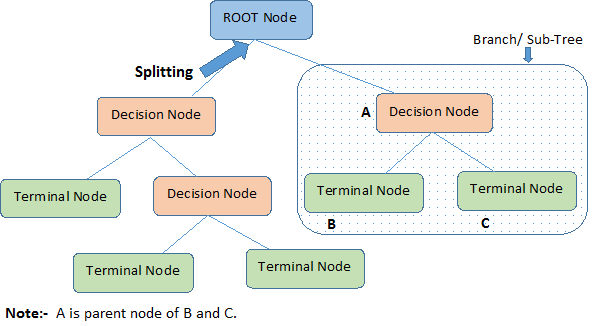
-
Root Node:根节点,代表全部样本集合。
-
Splitting: 拆分,将一个节点分割成多个节点的过程
-
Decision Node: 决策点,当一个子节点还可以被继续拆分,那这个子节点就是一个决策点。
-
Leaf/ Terminal Node: 叶子/终结点,不能在被拆分的节点
-
Pruning: 剪除,移除一个决策点的子节点的过程
-
Branch / Sub-Tree: 分支, 整个树的一个分路径,就叫一个分支
-
Parent and Child Node: 父节点/子节点,一个节点,把它拆分成多个子节点,那么这个节点就是父节点。
优点
- 容易理解,基础要求低.
- 在数据分析上很有用,可以帮我们快速从众多变量中找到最有用的,最有意义的标签
- 无需数据清晰,能够很好包容异常、缺失数据
- 能够同时处理数据型和常规型属性
- 无参算法,即无需假定空间分布或者分类框架等
缺点
- 过分拟合。这个问题通过设置模型参数和修剪的约束来解决(详见下文)。
- 不适合连续变量。
2. Regression Trees vs Classification Trees
我们都知道终端节点(或叶子)位于决策树的底部。这意味着决策树通常是颠倒的,就像叶子是底而根是顶一样(如下图所示)。

这两种树的工作原理几乎是一样的,让我们来看看分类和回归树之间的主要差异和相似性:
- 回归树通常在因变量连续时候使用;分类数则是在因变量离散时用
- 回归树中,训练数据中终端节点所获得的值是该区域观测值下降(observation falls )的平均响应。因此,如果一个看不见的数据在那个区域下降,我们将用平均值来做预测。
- 在分类树的情况下,训练数据中终端节点获得的值(类别)是该区域的观测值。因此,如果在该区域中有一个看不见的数据,我们将用mode值进行预测。
- 这两种树将预测空间(独立变量)分为不同的和非重叠的区域。为了简单起见,您可以将这些区域看作是高维的箱子。
- 这两棵树都遵循自顶向下的贪婪方法,称为递归二进制分割。我们把它称为“自上而下”,因为它从树的顶端开始,当所有的观测都在一个区域内,并相继将预测空间分成两个新的分支。它被称为“贪婪”,因为算法只关心当前的分割,而不是未来的分裂,从而构建出更好的树。
- 这种分裂过程一直持续到用户定义的停止标准达成。例如: 一旦每个节点的观察次数小于 50时,我们可以让算法停下来。
- 在这两种情况下,分裂过程会导致完全长成的树,直到达到停止的条件。但是,完全成熟的树可能会过分拟合数据,从而导致不可见数据的不准确性。这这将造成“修剪”。修剪是解决过度拟合的技术之一。在下一节中,我们将进一步了解它。
未完待续。。。















 319
319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









