






目的:爬取“2019USNEWS美国综合性大学排名”上大学的信息【排名、学校中文、学校英文、学校地址、录取率】,然后将数据保存到MySQL中
结果呈现:在MySQL中存储数据,实现对数据的查取
昨晚收到“阿里”的电话面试,和面试小哥聊了40分钟,我发现“阿里”的人真的太nice了!发现我感冒了提醒我注意身体,然后面试我的时候,完全不是看我投的职位,而是从我的兴趣出发,对我的简历提出了建设性的建议,体谅我没做过项目,没有从项目角度让我分析问题,而是从我发的博客中来讲,问了我很多,鼓励我要有信心。但是对我数据库这块问的还挺多,但是我只知道MySQL,其余是真的不知道。甚至“关系型数据库和非关系型数据的区别”,我讲的也不好,所以啊!!!现在爬取的数据进行要存储到数据库里!!!
 【我。。。。。。想去阿里!!!】
【我。。。。。。想去阿里!!!】
注:代码很简单啦~~~看看就懂啦~~~重点是数据库的使用!!!
#下面为本实例的爬虫代码,若有问题可以给我留言,或者有更好的解决方法也可以私信我~
import requests from bs4 import BeautifulSoup import pymysql class SJK(): #数据库的类 def __init__(self,db_name,table_name): self.db_name=db_name #数据库的名称 self.table_name=table_name #表名 def save_to_database(self,info): db=pymysql.connect(host='localhost',port=3306,user='root',passwd='12345678',db=self.db_name,charset='utf8') cursor=db.cursor() #使用cursor的方法创建一个游标对象 sql="""INSERT INTO {} (rank,ChineseName,EnglishName,Location,rate) VALUES ('{}','{}','{}','{}','{}')""".format(self.table_name,info[0],info[1],info[2],info[3],info[4]) try: cursor.execute(sql) db.commit() print('{}-----存储成功'.format(info[1])) except Exception as e: db.rollback() print('{}-----存储失败'.format(info[1])) print(e) class SchoolInfo(): #爬取信息 def __init__(self): self.start_url='https://www.xuanxiaodi.com/ranks/1190-1.html' self.headers={'user-agent':'Mozilla/5.0'} self.sjk=SJK('SchoolInfo','University') def get_page(self,url): try: r=requests.get(url,headers=self.headers) r.raise_for_status() #r.encoding=r.apparent_encoding return r.text except Exception as e: print(e) def get_num(self,url): html=self.get_page(url) soup=BeautifulSoup(html,'html.parser') ul=soup.find('ul',{'class':{'component-pagination '}}) li_page=ul('li')[-2]('a')[0].text.strip() #字符串类型 return li_page def get_info(self,url): html=self.get_page(url) soup=BeautifulSoup(html,'html.parser') ul=soup.find('ul',{'class':{'school-list'}}) info=[] for li in ul('li'): try: rank = int(li.find('svg', {'class': {'rank-num'}}).text.strip().replace('#', '')) # rank是整数类型 zh_name = li.find('a', {'class': {'school-zh-name'}}).text.strip() # 学校中文名字 en_name = li.find('div', {'class': {'school-en-name'}}).text.strip() # 学校英文名 location = li.find('span', {'class': {'location-text'}}).text.strip() # 学校地址 rate = li.find('span', {'class': {'rate-num'}}).text.strip() # 录取率 if rate == '-': rate = '' else: rate = float(rate.replace('%', '')) # 录取率变为float型 if location == '': print('无') # 未知地址 info = [rank, zh_name, en_name, location, rate] self.sjk.save_to_database(info) except: continue def main(self): num=self.get_num(self.start_url) for i in range(1,int(num)): page_url=self.start_url.replace('1.html',str(i)+'.html') self.get_info(page_url) school_info=SchoolInfo() school_info.main()
【前期数据库的操作:】
"""
数据库中操作:
首先打开数据库管理权限:net start mysql56
C:\WINDOWS\system32>mysql -u root -p
Enter password: ********
进入MySQL
新建数据库:SchoolInfo
新建表:University 字段:id INT;rank INT;ChineseName VARCHAR(225);EnglishName VARCHAR(225);Location VARCHAR(225);rate FLOAT;
mysql> CREATE DATABASE IF NOT EXISTS SchoolInfo DEFAULT CHARSET utf8 COLLATE utf8_general_ci; #创建数据库
mysql> USE SchoolInfo;
mysql> CREATE TABLE University(
-> id INT PRIMARY KEY AUTO_INCREMENT, #注:此时PRIMARY KEY必须放在AUTO_INCREMENT之前
-> rank INT,
-> ChineseName VARCHAR(225),
-> EnglishName VARCHAR(255),
-> Location VARCHAR(225),
-> rate FLOAT);
mysql> DESCRIBE University;
+-------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| rank | int(11) | YES | | NULL | |
| ChineseName | varchar(225) | YES | | NULL | |
| EnglishName | varchar(255) | YES | | NULL | |
| Location | varchar(225) | YES | | NULL | |
| rate | float | YES | | NULL | |
+-------------+--------------+------+-----+---------+----------------+
"""
数据库中显示:【屏幕也有显示存储成功】
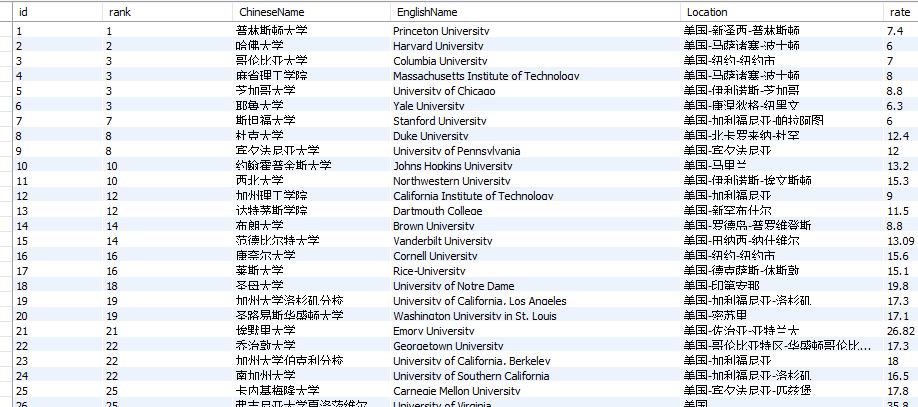
在数据中查询录取率>90.0%的学校
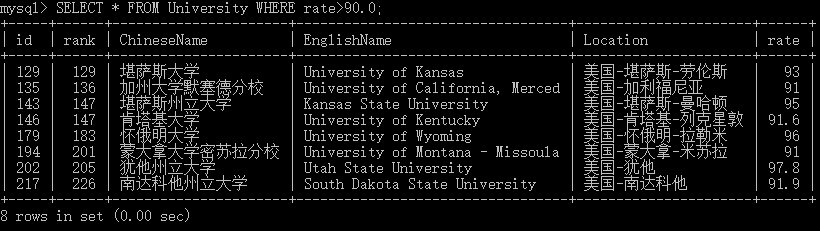
面向对象爬取完成!
---------(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)----------
注:以后写代码,我应该都是直接写面向对象的形式!【!!!欢迎大家监督!!!】
注:以后数据,我尽量保存到数据库【!!!欢迎大家监督!!!】
今日爬虫完成!
今日鸡汤:有梦想的人不做选择题,只做证明题,所以,年轻的你,可以犯错,可以跌倒,但千万不要怀疑自己,也不要放弃梦想。去想去的地方,做该做的事情,不迟疑,不徘徊。从明天开始,向自己承诺:你做的每个选择,都让自己比现在快乐、充实。
加油ヾ(◍°∇°◍)ノ゙














 3100
3100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









