







1、基础概念
1.1、阻塞非阻塞和同步异步的结合
下面通过例子来具体说明: 同步阻塞: 小明一直盯着下载进度条,到100%的时候完成。
同步体现在:小明关注下载进度条并等待完成通知。(可以看成同步是我主动关注任务完成的通知,异步是被动的,任务完成后再通知我)
阻塞体现在:在等待过程中,小明不去做别的东西。(不能去做其他事情)
1.2、同步非阻塞:
小明提交下载任务后,就去干别的事了,但每过一段时间就去瞄一眼进度条,看到100%就完成。
同步体现在:小明关注下载进度条并等待完成通知。
非阻塞体现在:等待下载完成通知过程中,去干别的任务了,只是时不时会瞄一眼进度条;【小明必须要在两个任务间切换,关注下载进度】
这种方式是效率低下的,因为程序需要在不同任务的线程中频繁切换。
1.3、异步阻塞:
小明换了个有下载完成通知功能的软件,下载完成就“叮”一声,
异步体现在:小明不用时刻关注进度条,在下载完成后,消息通知机制是由“叮”一声去通知小明的。
阻塞体现在:小明在等待“叮”的时候,不能去做其他事情。
1.4、异步非阻塞:
小明仍然使用那个下载完会“叮”一声的软件,小明在提交下载任务后,就不管了,转而去做其他事情。而当下载完成后,下载软件会通过“叮”去主动通知小明。
异步体现在:小明不用时刻关注下载任务,而是让下载软件下载完成之后通过“叮”来通知他。
非阻塞体现在:小明在下载过程中,并非什么都不做,而是去做其他事情了。【软件处理下载任务,小明处理其他任务,不需关注进度,只需接收软件“叮”声通知,即可】
2、BIO模型 (Blocking IO)同步阻塞IO
同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。这里使用那个经典的烧开水例子,这里假设一个烧开水的场景,有一排水壶在烧开水,BIO的工作模式就是, 叫一个线程停留在一个水壶那,直到这个水壶烧开,才去处理下一个水壶。但是实际上线程在等待水壶烧开的时间段什么都没有做。
实际应用如下图:
当调用系统调用read时,用户线程会一直阻塞到内核空间有数据到来为止,否则就一直阻塞。
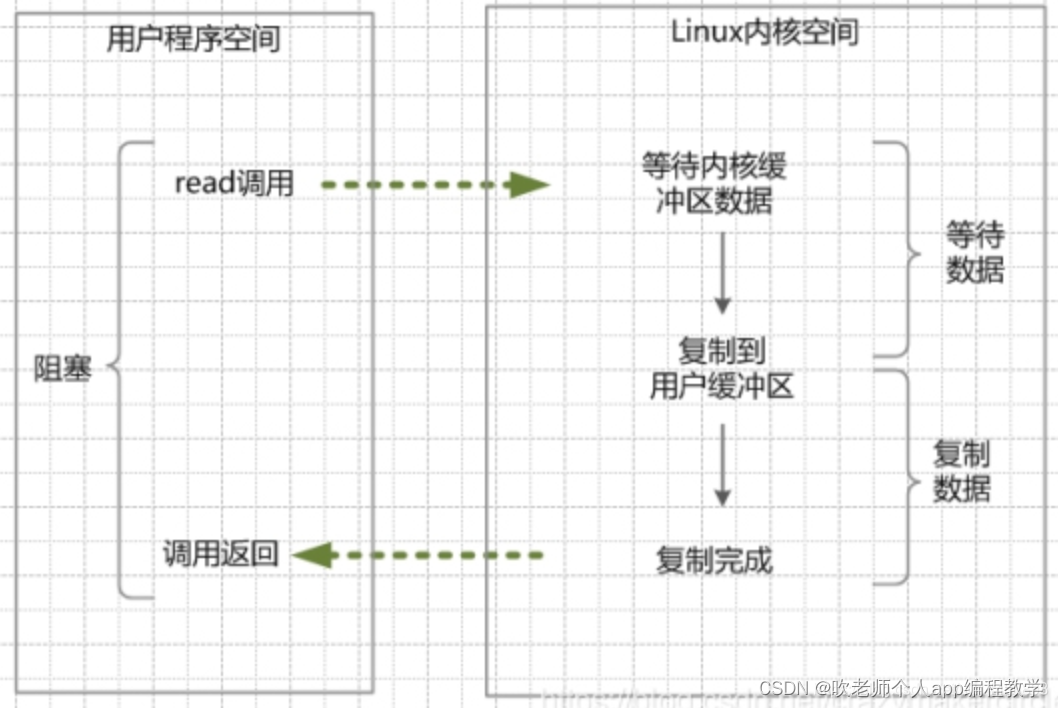
举个栗子,发起一个blocking socket的read读操作系统调用,流程大概是这样:
(1)当用户线程调用了read系统调用,内核(kernel)就开始了IO的第一个阶段:准备数据。很多时候,数据在一开始还没有到达(比如,还没有收到一个完整的Socket数据包),这个时候kernel就要等待足够的数据到来。
(2)当kernel一直等到数据准备好了,它就会将数据从kernel内核缓冲区,拷贝到用户缓冲区(用户内存),然后kernel返回结果。
(3)从开始IO读的read系统调用开始,用户线程就进入阻塞状态。一直到kernel返回结果后,用户线程才解除block的状态,重新运行起来。
BIO特点
BIO优点:程序简单,在阻塞等待数据期间,用户线程挂起。用户线程基本不会占用 CPU 资源。
BIO缺点:
一般情况下,服务端会为每个客户端连接配套一条独立的线程,或者说一条线程维护一个连接成功的IO流的读写。在并发量小的情况下,这个没有什么问题。但是,当在高并发的场景下,需要大量的线程来维护大量的网络连接,内存、线程切换开销会非常巨大。因此,基本上,BIO模型在高并发场景下是不可用的。
public static void main(String[] args) throws Exception {
//建立socket,socket是客户端和服务器沟通的桥梁
ServerSocket server = new ServerSocket(9090,20);
//通过死循环不断接收客户端请求
while (true) {
//线程会阻塞在这行的accep方法
Socket client = server.accept();
//创建新线程处理新客户端的逻辑
new Thread(() -> {
//client的读写逻辑
}).start();
}
}
只要没有客户端连接上服务器,accept方法就一直不能返回,这就是阻塞;对应的读写操作道理也一样,想要读取数据,必须等到有数据到达才能返回,这就是阻塞。
我们还可以站在阻塞的基础上思考一下,为什么服务器的模型要设计成来一个客户端就新建一个线程?
其实答案很简单,当来了一个客户端创建连接后,如果不给客户端新分配一个线程执行服务器逻辑,那么服务端将很难再和第二个客户端建立连接。
就算你把客户端连接用集合保存起来,通过单线程遍历集合的方式去执行服务器端逻辑也是不行的。因为如果某个客户端连接因为读写操作阻塞了,那么其他客户端将得不到执行。
3、NIO模型(Non-blocking IO)
(注意这里说的NIO和Java库的NIO是有区别的,Java的NIO库表示的是New IO的意思。这里我们说的NIO是同步非阻塞IO)
那么什么叫做同步非阻塞?如果还拿烧开水来说,NIO的做法是叫一个线程不断的轮询每个水壶的状态,看看是否有水壶的状态发生了改变,从而进行下一步的操作。
在应用中,NIO是如何做到非阻塞地监控每个IO的呢?
NIO 模型中应用程序在一旦开始IO系统调用,会出现以下两种情况:
(1)在内核缓冲区没有数据的情况下,系统调用会立即返回,返回一个调用失败的信息。
(2)在内核缓冲区有数据的情况下,是阻塞的,直到数据从内核缓冲复制到用户进程缓冲。复制完成后,系统调用返回成功,应用进程开始处理用户空间的缓存数据。
如下图:
多次调用不同socket的read,当内核缓冲区没有数据,则马上返回,直到第N次调用read,才发现内核空间有数据,然后才开始真正读数据
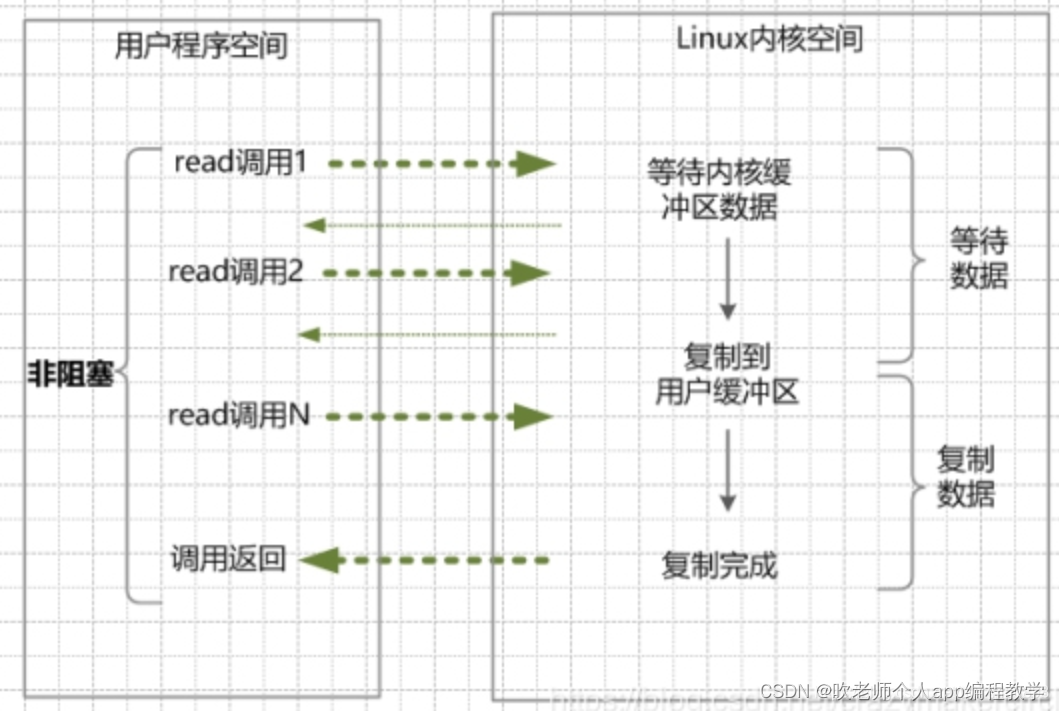
举个栗子。发起一个non-blocking socket的read读操作系统调用,流程是这个样子:
(1)在内核数据没有准备好的阶段,用户线程发起IO请求时,立即返回。用户线程需要不断地发起IO系统调用。
(2)内核数据到达后,用户线程发起系统调用,用户线程阻塞。内核开始复制数据。它就会将数据从kernel内核缓冲区,拷贝到用户缓冲区(用户内存),然后kernel返回结果。
(3)用户线程才解除block的状态,重新运行起来。经过多次的尝试,用户线程终于真正读取到数据,继续执行。
NIO特点:
NIO优点:每次发起的 IO 系统调用,在内核的等待数据过程中可以立即返回。用户线程不会阻塞,则表示用户线程不用呆呆地等待数据到来,而是可以去干其他活了。
NIO缺点:需要不断的重复发起IO系统调用,这种不断的轮询,将会不断地询问内核,这将占用大量的 CPU 时间,系统资源利用率较低。而且任务完成(处理到来数据)的响应延迟增大了,因为每过一段时间才去轮询一次 read 操作,而任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低。
总之,NIO模型在高并发场景下,也是不可用的。一般 Web 服务器不使用这种 IO 模型。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。java的实际开发中,也不会涉及这种IO模型。
再次说明,Java NIO(New IO) 不是IO模型中的NIO模型,而是另外的一种模型,叫做IO多路复用模型( IO multiplexing )。
如果说服务器只有很少的人用,那么上面那段bio的代码其实挺好的,但问题在于互联网蓬勃发展,随着服务器访问人数的增加,这样的服务器模型将会成为瓶颈。
我们以一种C10K的思想去看待上面这段服务器代码。如果我们客户端的连接数增加了10K倍,那么就意味着要创建10k个线程,单单创建线程就是一项不小的开销了,再加上线程之间要来回切换,单机服务器根本就扛不住这么大的连接数。
那既然瓶颈是出在线程上,我们就考虑能不能把服务器的模型变为单线程模型,思路其实和之前说的差不多,用集合保存每个连接的客户端,通过while循环来对每个连接进行操作。
之前我们说了这样的操作瓶颈在于accept客户端的时候会阻塞,以及进行读写操作的时候会阻塞,导致单线程执行效率低。为了突破这个瓶颈,操作系统发展出了nio,这里的nio指的是非阻塞io。
也就是说在accept客户端连接的时候,不需要阻塞,如果没有客户端连接就返回-1(java-NULL),在读写操作的时候,也不阻塞,有数据就读,没数据就直接返回,这样就解决了单线程服务器的瓶颈问题。示例代码如下:
public static void main(String[] args) throws Exception {
//用于存储客户端的集合
LinkedList<SocketChannel> clients = new LinkedList<>();
//nio里概念改成了channel
ServerSocketChannel ss = ServerSocketChannel.open();
ss.bind(new InetSocketAddress(9090));
//设置成非阻塞
ss.configureBlocking(false);
while (true) {
//下面的accept方法不会阻塞
SocketChannel client = ss.accept();
if (client == null) {
System.out.println("null.....");
} else {
//设置客户端操作也为非阻塞
client.configureBlocking(false);
clients.add(client);
}
ByteBuffer buffer = ByteBuffer.allocateDirect(4096);
//遍历已经链接进来的客户端能不能读写数据
for (SocketChannel c : clients) {
int num = c.read(buffer);
if (num > 0) {
//其他操作
}
}
}
}
4、IO多路复用模型
IO多路复用模型,就是通过一种新的系统调用,一个进程可以监视多个文件描述符(如socket),一旦某个描述符就绪(一般是内核缓冲区可读/可写),内核kernel能够通知程序进行相应的IO系统调用。
目前支持IO多路复用的系统调用,有 select,epoll等等。select系统调用,是目前几乎在所有的操作系统上都有支持,具有良好跨平台特性。epoll是在linux 2.6内核中提出的,是select系统调用的linux增强版本。而Java NIO库中的 selector 底层就是IO多用复用技术。
尽管上面的单线程NIO服务器模型比BIO的优良许多,但是仍然有一个大问题。在客户端与服务器建立连接后,后续会进行一系列的读写操作。虽然这些读写操作是非阻塞的,但是每调一次读写操作在操作系统层面都要进行一次用户态和内核态的切换,这个也是一项巨大的开销(读写等系统调用都是在内核态完成的)。
在上面的代码中每次循环遍历都进行读写操作,我们以读操作为例:大部分读操作都是在数据没有准备好的情况下进行读的,相当于执行了一次空操作。我们要想办法避免这种无效的读取操作,避免内核态和用户态之间的频繁切换。
补充:客户端与服务器两端都是通过socket进行连接的,socket在linux操作系统中有对应的文件描述符,我们的读写操作都是以该文件描述符为单位进行操作的。
为了避免上述的无效读写,我们得想办法得知当前的文件描述符是否可读可写。如果逐个文件描述符去询问,那么效率就和直接进行读写操作差不多了,我们希望有一种方法能够一次性得知哪些文件描述符可读,哪些文件描述符可写,这,就操作系统后来发展出的多路复用器。
也就是说,多路复用器的核心功能就是告诉我们哪些文件描述符可读,哪些文件描述符可写。而多路复用器也分为几种,他们也经历了一个演化的过程。最初的多路复用器是select模型,它的模式是这样的:程序端每次把文件描述符集合交给select的系统调用,select遍历每个文件描述符后返回那些可以操作的文件描述符,然后程序对可以操作的文件描述符进行读写。
它的弊端是,一次传输的文件描述符集合有限,只能给出1024个文件描述符,poll在此基础上进行了改进,没有了文件描述符数量的限制。
但是select和poll在性能上还可以优化,它们共同的弊端在于:
它们需要在内核中对所有传入的文件描述符进行遍历,这也是一项比较耗时的操作
(这点是否存在优化空间有待考证)每次要把文件描述符从用户态的内存搬运到内核态的内存,遍历完成后再搬回去,这个来回复制也是一项耗时的操纵。
后来操作系统加入了epoll这个多路复用器,彻底解决了这个问题:
epoll多路复用器的模型是这样的:
为了在发起系统调用的时候不遍历所有的文件描述符,epoll的优化在于:当数据到达网卡的时候,会触发中断,正常情况下cpu会把相应的数据复制到内存中,和相关的文件描述符进行绑定。epoll在这个基础之上做了延伸,epoll首先是在内核中维护了一个红黑树,以及一些链表结构,当数据到达网卡拷贝到内存时会把相应的文件描述符从红黑树中拷贝到链表中,这样链表存储的就是已经有数据到达的文件描述符,这样当程序调用epoll_wait的时候就能直接把能读的文件描述符返回给应用程序。
除了epoll_wait之外,epoll还有两个系统调用,分别是epoll_create和epoll_ctl,分别用于初始化epoll和把文件描述符添加到红黑树中。
以上就是多路复用器与常见io模型的关系了,网上常常有文章把多路复用器说成是nio的一部分,我觉得也是合理的,因为在具体编程的时候两个概念往往会融为一体。
后续
其实Java已经为我们把多路复用器用Selector类给封装起来了,我们完全可以基于Selector进行NIO服务器开发。但是我们自己写nio服务器可能不够严谨,Java届有一款优秀nio框架,名叫Netty,这部分内容我们留到下一次再讲啦。
5、IO多路复用和NIO的区别
NIO需要在用户程序的循环语句中不停地检查各个socket是否有数据读入,而IO多路复用在用户程序层面则不需要循环语句,虽然IO多路复用也是轮询,但是IO多路复用是交给内核进行各个socket的监控的。其次,由于NIO多次调用read这种系统调用,因此会频繁造成用户态和内核态的转换,而IO多路复用则是先调用select这个系统调用去查询是否有数据就绪的socket,然后有数据就绪,才调用read这个系统调用来读。所以从性能上来说,IO多路复用会比NIO好。
在一定程度上来说,IO多路复用算是同步阻塞的一种,因为select会阻塞到有socket数据就绪为止。所以在应用上,一般会开一条程序来专门给select查询。
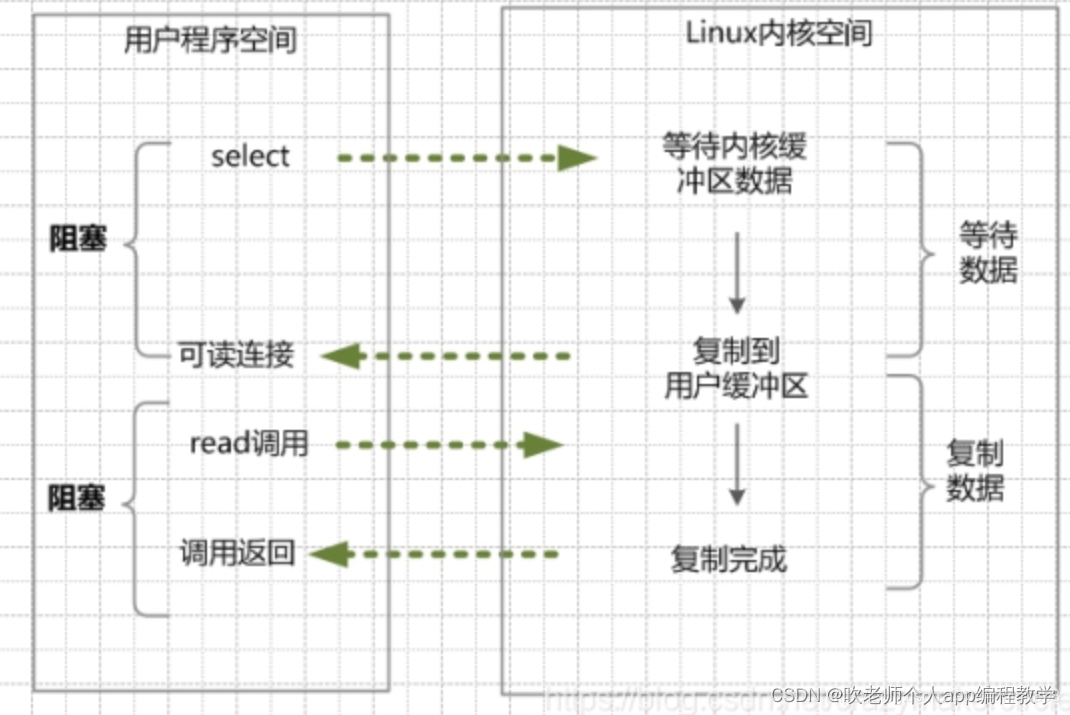
如下图为IO对路复用的过程:
(1)进行select/epoll系统调用,查询可以读的连接。kernel会查询所有select的可查询socket列表,当任何一个socket中的数据准备好了,select就会返回。
当用户进程调用了select,那么整个线程会被block(阻塞掉)。
(2)用户线程获得了目标连接后,发起read系统调用,用户线程阻塞。内核开始复制数据。它就会将数据从kernel内核缓冲区,拷贝到用户缓冲区(用户内存),然后kernel返回结果。
(3)用户线程才解除block的状态,用户线程终于真正读取到数据,继续执行。
6、多路复用IO的特点
IO多路复用模型,建立在操作系统kernel内核能够提供的多路分离系统调用select/epoll基础之上的。多路复用IO需要用到两个系统调用(system call), 一个select/epoll查询调用,一个是IO的读取调用。
和NIO模型相似,多路复用IO需要轮询。负责select/epoll查询调用的线程,需要不断的进行select/epoll轮询,查找出可以进行IO操作的连接。
另外,多路复用IO模型与前面的NIO模型,是有关系的。对于每一个可以查询的socket,一般都设置成为non-blocking模型。只是这一点,对于用户程序是透明的(不感知。因为是在内核处理的)。
优点:
用select/epoll的优势在于,它可以同时处理成千上万个连接(connection)。与一条线程维护一个连接相比,I/O多路复用技术的最大优势是:系统不必创建线程,也不必维护这些线程,从而大大减小了系统的开销。
缺点:
本质上,select/epoll系统调用,属于同步IO,也是阻塞IO。都需要在读写事件就绪后,自己负责进行读写,也就是说这个读写过程是阻塞的。
7、AIO ( Asynchronous I/O)异步非阻塞I/O模型
异步非阻塞I/O模型。异步非阻塞与同步非阻塞的区别在哪里?异步非阻塞无需一个线程去轮询所有IO操作的状态改变,在相应的状态改变后,系统会通知对应的线程来处理。对应到烧开水中就是,为每个水壶上面装了一个开关,水烧开之后,水壶会自动通知我水烧开了。
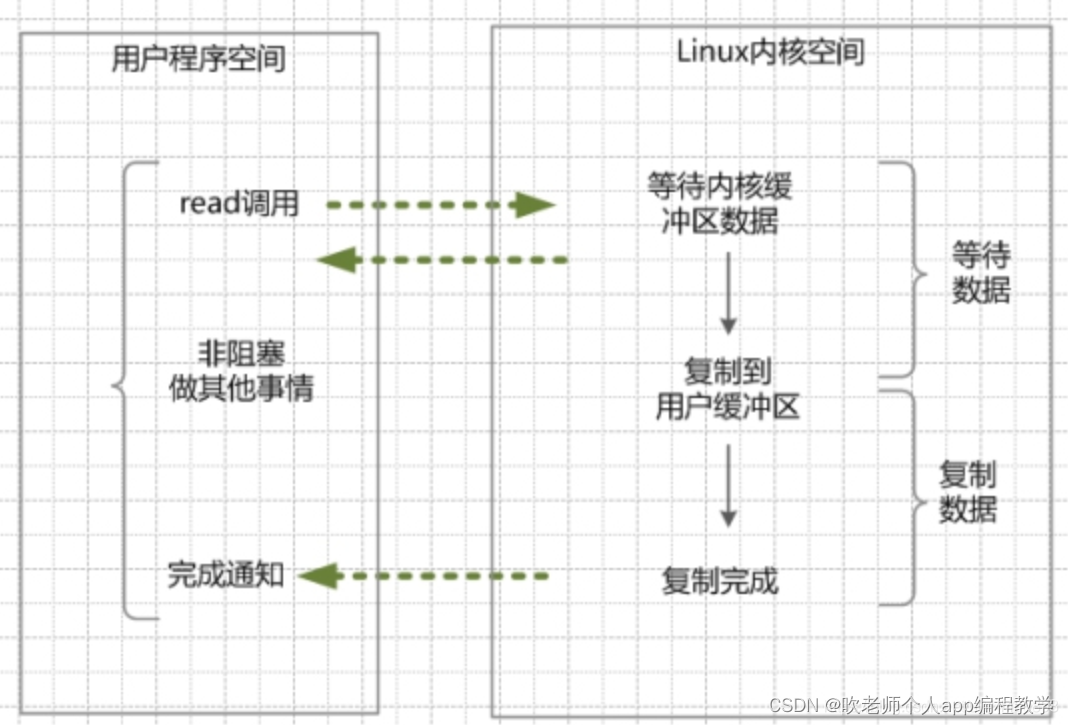
例子:如下图
(1)当用户线程调用了read系统调用,立刻就可以开始去做其它的事,用户线程不阻塞。
(2)内核(kernel)就开始了IO的第一个阶段:准备数据。当kernel一直等到数据准备好了,它就会将数据从kernel内核缓冲区,拷贝到用户缓冲区(用户内存)。
(3)kernel会给用户线程发送一个信号(signal),或者回调用户线程注册的回调接口,告诉用户线程read操作完成了。
(4)用户线程读取用户缓冲区的数据,完成后续的业务操作。
















 671
671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











