






1.NLTK的安装
pip install nltk
2.安装语料库
import nltk nltk.download()
例如安装布朗大学的语料库:brown
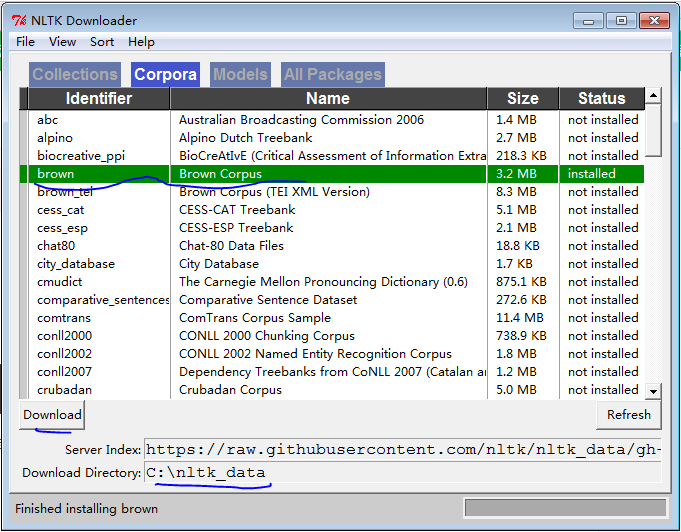
也可以在程序中下载
nltk.download('brown')
3.NLTK自带语料库
from nltk.corpus import brown from pprint import pprint pprint(brown.categories()) print len(brown.sents()) print len(brown.words())
4.文本处理流程
文本-->分词-->特征工程-->机器学习
5.分词
(1)英文分词
import nltk
nltk.download('punkt')
sentence = 'Hello, Python'
tokens = nltk.word_tokenize(sentence)
print tokens
词性标注
print nltk.pos_tag(tokens)
(2)中文分词
1)原理:
HMM模型:http://yanyiwu.com/work/2014/04/07/hmm-segment-xiangjie.html
CRF模型:http://blog.csdn.net/ifengle/article/details/3849852
2)中文分词的Python库
jieba:https://github.com/fxsjy/jieba
corenlp-python:http://stanfordnlp.github.io/CoreNLP/
https://pypi.python.org/pypi/corenlp-python
6.中文分词之jieba
import jieba sentence = '我来到北京清华大学' sentence2 = '小明硕士毕业于中国科学院计算所,后在日本京都大学深造' seg1 = jieba.cut(sentence, cut_all=True) # 全模式 # print type(seg) # 分词后的结果并不是一个list,而是一个generator print '[全模式:]', '/'.join(seg1) seg2 = jieba.cut(sentence, cut_all=False) # 精准模式 print '[精准模式:]', '/'.join(seg2) seg3 = jieba.cut(sentence) # 默认情况是精准模式 print '[默认情况:]', '/'.join(seg3) seg4 = jieba.cut_for_search(sentence2) # 搜索引擎模式 print '[搜索引擎模式:]', '/'.join(seg4)
7.停用词(stopwords)
from nltk import word_tokenize
from nltk.corpus import stopwords
sentence = 'NetworkX is a Python language software package for studying the complex networks'
words = word_tokenize(sentence)
print words
filtered_words = [word for word in words if word not in stopwords.words('english')]
print filtered_words
8.NLP的应用
(1)情感分析
1)最简单的就是基于sentiment dictionary的方法,类似于基于关键词的打分机制,目前应用于广告投放领域。存在的问题:无法解决新词,特殊词以及更深层次的情感
from nltk import word_tokenize
from nltk.corpus import stopwords
sentiment_dictionary = {}
for line in open(r'E:\Python\QiyueZaixian\1_lesson\data\AFINN\AFINN-111.txt', 'r'):
word, score = line.split('\t')
sentiment_dictionary[word] = int(score)
sentence = 'He is a brave man'
words = word_tokenize(sentence)
filtered_words = [word for word in words if word not in stopwords.words('english')]
total_score = sum(sentiment_dictionary.get(word, 0) for word in filtered_words)
print total_score
2)基于Machine Learning的情感分析
# 配上Machine Learning的情感分析
from nltk.classify import NaiveBayesClassifier
# 训练集
s1 = 'this is a good book'
s2 = 'this is a awesome book'
s3 = 'this is a bad book'
s4 = 'this is a terrible book'
# 文本预处理函数
def pre_process(s):
return {word: True for word in s.lower().split()}
# 标准化训练集
training_data = [
[pre_process(s1), 'pos'],
[pre_process(s2), 'pos'],
[pre_process(s3), 'neg'],
[pre_process(s4), 'neg']
]
# 训练
model = NaiveBayesClassifier.train(training_data)
# 测试
test_s = 'This is a great book'
print model.classify(pre_process(test_s))
(2)文本相似度:基于词频的独热编码(One-hot encoding),使用FreqDist进行词频统计
from nltk import word_tokenize
from nltk import FreqDist
# 构建词库
sentence = 'this is my sentence this is my life this is the day'
tokens = word_tokenize(sentence)
print tokens
fd = FreqDist(tokens)
print fd['is']
standard_vector = fd.most_common(6)
print standard_vector
size = len(standard_vector)
# 记录下出现次数最多的几个单词的位置信息
def position(st_vec):
ps_dt = {}
index = 0
for word in st_vec:
ps_dt[word[0]] = index
index += 1
return ps_dt
standard_position = position(standard_vector)
print standard_position
# 新的句子
new_sentence = 'this is cool'
freq_list = [0] * size
new_tokens = word_tokenize(new_sentence)
for word in new_tokens:
try:
freq_list[standard_position[word]] += 1
except KeyError:
continue
print freq_list
(3)文本分类:TF-IDF(词频-逆文档频率)
举例:一个文档中有100个单词,单词sheep出现了7次,那么TF(sheep) = 7/100 = 0.07
现在我们有10,000,000个文档,出现sheep的文档有10,000个,
那么IDF(sheep) = lg(10,000,000/10,000) = 3,
那么TF-IDF(sheep) = TF(sheep) * IDF(sheep) = 0.07 * 3 = 0.21
from nltk.text import TextCollection
sentence1 = 'this is sentence one'
sentence2 = 'I love you'
sentence3 = 'He is a brave man'
sentence4 = 'Hello, Python'
corpus = TextCollection([sentence1, sentence2, sentence3])
print corpus.tf('Hello', sentence4) # tf = sentence4.count('Hello')/ len(sentence4)
print corpus.tf_idf('Hello', sentence4)















 2340
2340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









