







1、Buffer
1)Arraybuffer对象是用表示通用的,固定长度的二进制数据缓冲区。Arraybuffer不能直接操作,而是要通过类型数组对象或DataView对象来操作,它们会将缓冲区数据表示为特定格式的数据,并通过这类格式来读写缓冲区内容,可以理解为一块内存,具体存什么需要其他声明。
var buffer = new ArrayBuffer(8);//声明一个长度为8的缓冲区域,8位为一个字节
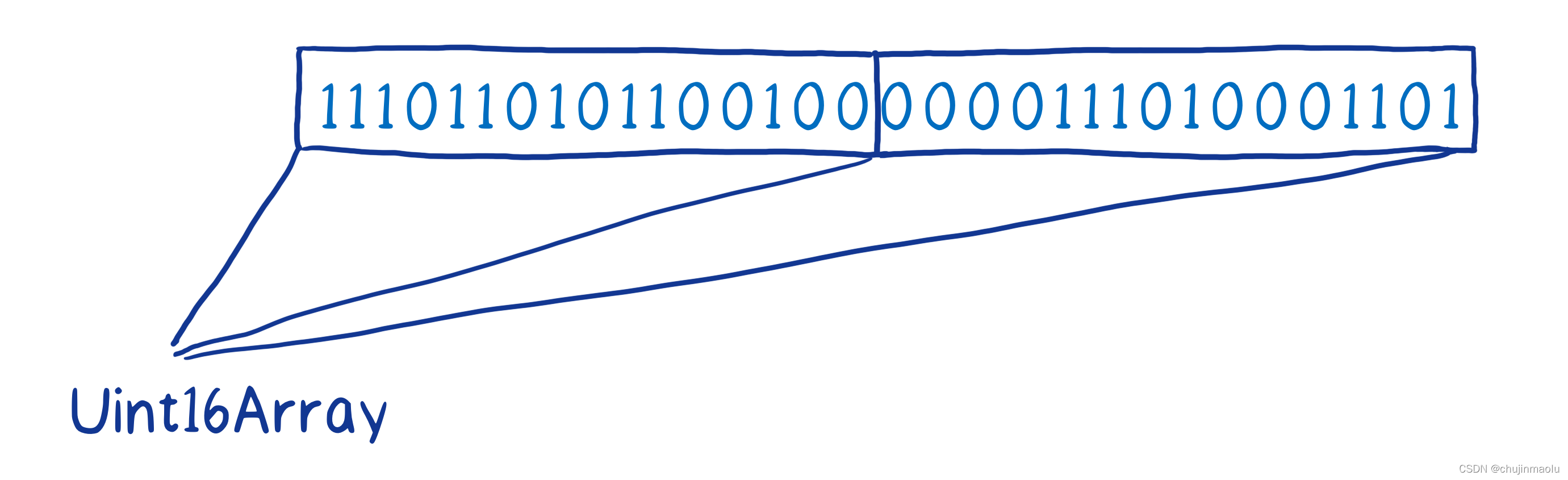
var view = new Int16Array(buffer);//以16位整数数组划分字节长度为8的缓冲区域
console.log(buffer);
console.log(view);//[0,0,0,0],8个字节长度以16位格式划分为4的长度
2)Unit8Array数组类型表示一个8位无符号整型数组,创建时内容被初始化为0,创建完成后可以以对象的形式或者数组下标索引的形式引用数组中的元素
//长度声明
var unit8 = new Unit8Array(2);
unit8[0] = 42;
console.log(uint8[0]); // 42
console.log(uint8.length); // 2
console.log(uint8.BYTES_PER_ELEMENT); // 1 每一个元素的字节大小
//数组声明
var arr = new Uint8Array([21,31]);
console.log(arr[1]); // 31
//来自另一个typedarray声明
var x = new Uint8Array([21, 31]);
var y = new Uint8Array(x);
console.log(y[0]); // 21
3)ArrayBuffer和TypedArray关系
TypedArray:像Uint8Array,Int16Array都属于TypedArray,它们都是给ArrayBuffer提供一个视图,对它们进行读写操作,最终会反应到ArrayBuffer上
ArrayBuffer:它本身是一个0和1的集合,ArrayBuffer不知道第一个和第二元素该怎么分配。
ArrayBuffer如图:
Init8Array:

Unit16Array:
2、nodejsBuffer
Buffer类以一种更适合nodejs的方式实现了Unit8Array API
Buffer类的实例类似于整数数组,但是Buffer的大小是固定的,且在v8堆外分配物理内存,Buffer的大小在被创建时确定,无法调整。
1)基本使用
//创建一个长度为10 且用0填充的buffer
const buf1 = Buffer.alloc(10);//<buffer 00 00 00 ...>
const buf2 = Buffer.alloc(10,1);//<buffer 01 01 01 ...>
//创建一个长度为10,且未初始化的buffer,这个方法比调用Buffer.alloc快,但是返回的Buffer实例可能包含旧数据,因此需要fill(),write()重写
const buf3 = Buffer.allocUnsafe(10);
//创建一个包含01 02 03的buffer
const buf4 = Buffer.from([1,2,3]);
//创建一个包含‘utf-8’字节的buffer
const buf5 = Buffer.from('test');
tips:当调用 Buffer.allocUnsafe() 时,被分配的内存段是未初始化的(没有用 0 填充)。
虽然这样的设计使得内存的分配非常快,但已分配的内存段可能包含潜在的敏感旧数据。 使用通过 Buffer.allocUnsafe() 创建的没有被完全重写内存的 Buffer ,在 Buffer内存可读的情况下,可能泄露它的旧数据。
虽然使用 Buffer.allocUnsafe() 有明显的性能优势,但必须额外小心,以避免给应用程序引入安全漏洞
2)buffer实例与字符编码
Buffer 实例一般用于表示编码字符的序列,比如 UTF-8 、 UCS2 、 Base64 、或十六进制编码的数据。 通过使用显式的字符编码,就可以在 Buffer 实例与普通的 JavaScript 字符串之间进行相互转换。
const buf = Buffer.from('hello world','ascii');//'hello world'以ascii码值打印
console.log(buf.toString('hex'));//68656c6c6f20776f726c64
console.log(buf.toString('base64'));//aGVsbG8gd29ybGQ=
Node.js 目前支持的字符编码包括:
- ‘ascii’ - 仅支持 7 位 ASCII 数据。如果设置去掉高位的话,这种编码是非常快的。
- ‘utf8’ - 多字节编码的 Unicode 字符。许多网页和其他文档格式都使用 UTF-8 。
- ‘utf16le’ - 2 或 4 个字节,小字节序编码的 Unicode 字符。支持代理对(U+10000 至 U+10FFFF)。
- ‘ucs2’ - ‘utf16le’ 的别名。
- ‘base64’ - Base64 编码。当从字符串创建 Buffer 时,按照 RFC4648 第 5 章的规定,这种编码也将正确地接受 “URL 与文件名安全字母表”。
- ‘latin1’ - 一种把 Buffer 编码成一字节编码的字符串的方式(由 IANA 定义在 RFC1345 第 63 页,用作 Latin-1 补充块与 C0/C1 控制码)。
- ‘binary’ - ‘latin1’ 的别名。
- ‘hex’ - 将每个字节编码为两个十六进制字符。
- 在 Node.js 应用程序启动时,为了方便地、高效地使用 Buffer,会创建一个大小为 8K 的内存池。
// 创建内存池
function createPool() {
poolSize = Buffer.poolSize;
allocPool = createUnsafeArrayBuffer(poolSize);
poolOffset = 0;
}
//在 createPool() 函数中,通过调用 createUnsafeArrayBuffer() 函数来创建 poolSize(即8K)的 ArrayBuffer 对象。createUnsafeArrayBuffer() 函数的实现如下
function createUnsafeArrayBuffer(size) {
zeroFill[0] = 0;
try {
return new ArrayBuffer(size); // 创建指定size大小的ArrayBuffer对象,其内容被初始化为0。
} finally {
zeroFill[0] = 1;
}
}
//Uint8Array声明的使用方法
Uint8Array(length);
Uint8Array(typedArray);
Uint8Array(object);
Uint8Array(buffer [, byteOffset [, length]]);
除了buffer类还有一个fastbuffer类,在 FastBuffer 类的构造函数中,通过调用 Uint8Array(buffer [, byteOffset [, length]]) 来创建 Uint8Array 对象。
class FastBuffer extends Uint8Array {
constructor(arg1, arg2, arg3) {
super(arg1, arg2, arg3);
}
}
为什么以下是如此输出
const buf = Buffer.from('semlinker');
console.log(buf); // <Buffer 73 65 6d 6c 69 6e 6b 65 72>
/**
* Functionally equivalent to Buffer(arg, encoding) but throws a TypeError
* if value is a number.
* Buffer.from(str[, encoding])
* Buffer.from(array)
* Buffer.from(buffer)
* Buffer.from(arrayBuffer[, byteOffset[, length]])
**/
Buffer.from = function from(value, encodingOrOffset, length) {
if (typeof value === "string") return fromString(value, encodingOrOffset);
// 处理其它数据类型,省略异常处理等其它代码
if (isAnyArrayBuffer(value))
return fromArrayBuffer(value, encodingOrOffset, length);
var b = fromObject(value);
};
可以看出 Buffer.from() 工厂函数,支持基于多种数据类型(string、array、buffer 等)创建 Buffer 对象。对于字符串类型的数据,内部调用 fromString(value, encodingOrOffset) 方法来创建 Buffer 对象。
function fromString(string, encoding) {
var length;
if (typeof encoding !== "string" || encoding.length === 0) {
if (string.length === 0) return new FastBuffer();
// 若未设置编码,则默认使用utf8编码。
encoding = "utf8";
// 使用 buffer binding 提供的方法计算string的长度
length = byteLengthUtf8(string);
} else {
// 基于指定的 encoding 计算string的长度
length = byteLength(string, encoding, true);
if (length === -1)
throw new errors.TypeError("ERR_UNKNOWN_ENCODING", encoding);
if (string.length === 0) return new FastBuffer();
}
// 当字符串所需字节数大于4KB,则直接进行内存分配
if (length >= Buffer.poolSize >>> 1)
// 使用 buffer binding 提供的方法,创建buffer对象
return createFromString(string, encoding);
// 当剩余的空间小于所需的字节长度,则先重新申请8K内存
if (length > poolSize - poolOffset)
// allocPool = createUnsafeArrayBuffer(8K); poolOffset = 0;
createPool();
// 创建 FastBuffer 对象,并写入数据。
var b = new FastBuffer(allocPool, poolOffset, length);
const actual = b.write(string, encoding);
if (actual !== length) {
// byteLength() may overestimate. That's a rare case, though.
b = new FastBuffer(allocPool, poolOffset, actual);
}
// 更新pool的偏移
poolOffset += actual;
alignPool();
return b;
}
所以我们得到这样的结论
- 当未设置编码的时候,默认使用 utf8 编码;
- 当字符串所需字节数大于4KB,则直接进行内存分配;
- 当字符串所需字节数小于4KB,但超过预分配的 8K 内存池的剩余空间,则重新申请 8K 的内存池;
- 调用 new FastBuffer(allocPool, poolOffset, length) 创建 FastBuffer 对象,进行数据存储,数据成功保存后,会进行长度校验、更新 poolOffset 偏移量和字节对齐等操作。
















 998
998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









