






Spark在 Spark Core 之上提供了很多面向不同使用场景的高层API。比如 Spark Streaming、Spark SQL 、GraphX 、MLlib
选择spark streaming 做为源码定制的出发点的原因:
从依赖的专业知识上讲,相对于 其他API ,无需引入过多的专业领域的依赖知识。
从技术层面上讲,是在原有Spark Core基础上 升了一维。而这是Streaming特有的。
实时流处理是使用场景最广阔的,是最优吸引力的。
可以在Streaming处理后,调用Spark兄弟框架,如MLlib、SparkSQL
Streaming 是最复杂的,因为数据一直在变动。是挑战最大的。
因此,搞定Spark Streaming之后,再学其他API,就类似《三体》中的降维打击一样,很轻松即可理解。
Streaming因为多了感知数据的逻辑,因此更像是Spark上的一个应用程序。
下面实战演示,实现从源源不断的输入流中过滤掉黑名单中的数据。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
import
org.apache.spark.streaming.{Durations, StreamingContext}
import
org.apache.spark.{SparkConf, SparkContext}
/**
* 感谢王家林老师的知识分享
* 新浪微博:http://weibo.com/ilovepains
* 微信公众号:DT_Spark
* 博客:http://blog.sina.com.cn/ilovepains
* 手机:18610086859
* QQ:1740415547
* 邮箱:18610086859@vip.126.com
* YY课堂:每天20:00现场授课频道68917580
* 王家林:DT大数据梦工厂创始人、Spark亚太研究院院长和首席专家、大数据培训专家、大数据架构师。
*/
object
BlackListFilterSelfScala {
def
main(args
:
Array[String]) {
val
sparkConf
=
new
SparkConf().
setAppName(
"BlackListFilterSelfScala"
).
setMaster(
"spark://master:7077"
)
val
sc
=
new
SparkContext(sparkConf)
/**
* 给定默认的黑名单,此数据也可以从其他数据源动态获取
*/
val
black
_
list
=
sc.parallelize(Array(
"fail"
,
"sad"
)).
map(black
_
word
=
> (black
_
word, black
_
word))
/**
* 指定checkpoint
*/
sc.setCheckpointDir(
"hdfs://master:9000/library/streaming/black_list_filter/"
)
val
ssc
=
new
StreamingContext(sc, Durations.seconds(
30
))
/**
* 输入格式:关键字1,关键字2,...
*/
val
input
_
word
=
ssc.socketTextStream(
"localhost"
,
9999
)
val
flattenWord
=
input
_
word.flatMap(
_
.split(
" "
)).
map(row
=
> {
(row, row)
})
val
not
_
black
_
word
=
flattenWord.transform(fw
=
> {
fw.leftOuterJoin(black
_
list).
// 左连接
filter(
_
.
_
2
.
_
2
.isEmpty).
// 将黑名单中的过滤掉
map(
_
.
_
1
)
// 只返回关键字
})
not
_
black
_
word.print
// 输出
ssc.start
ssc.awaitTermination
sc.stop
}
}
|
部署到集群环境中,另起命令行:

输出:

输入的said和fail 被过滤i到了哦。成功。
成功输出后咱们马上结束程序,使之只执行一次。便于之后分析。
再到 http://master:8080/ 中查看下详细内容

点击Completed Applications 的Name中 看下:
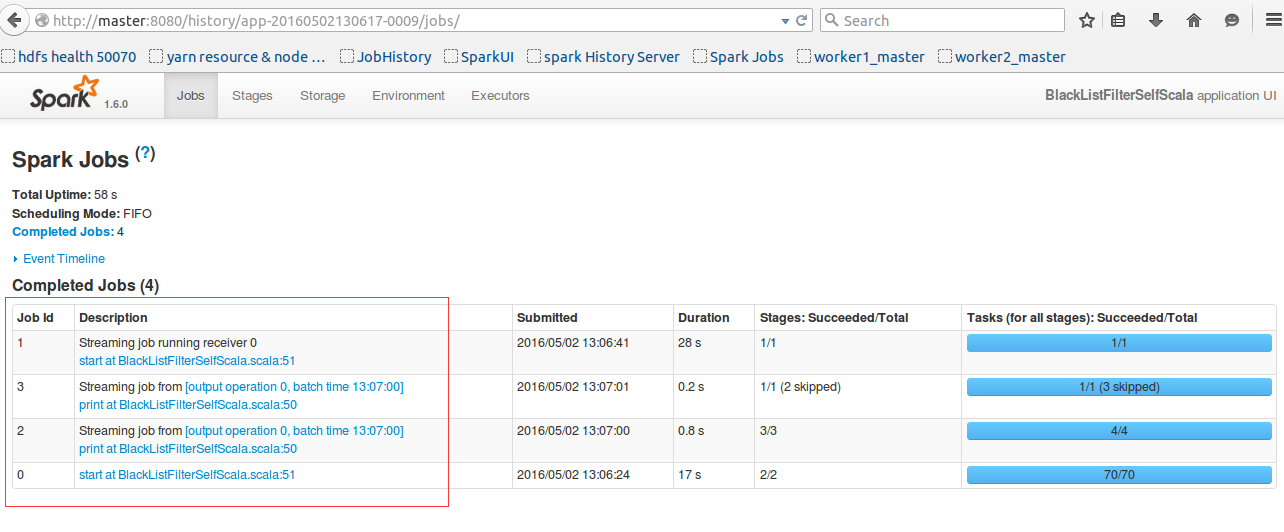
我们的逻辑很简单,只是创建了一个黑名单,并将流进来的数据过滤掉黑名单中的关键字。
并且咱们的批处理只执行一次之后就马上结束了。不存在多次执行的情况。那为什么会有这么多的job呢?

带着疑问,我们看看每个job中都些什么鬼。
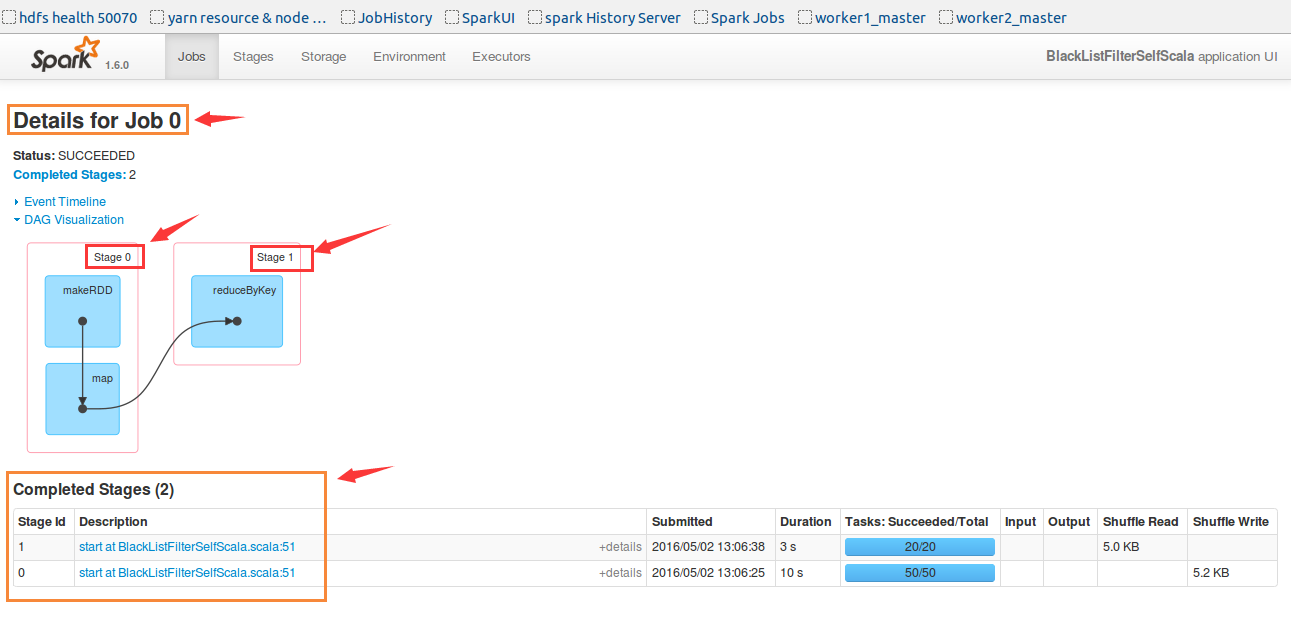
 此处可见,第一个job0是生产黑名单的job。但是代码里并没有reduceByKey。哪来的呢?此处留一个悬念。
此处可见,第一个job0是生产黑名单的job。但是代码里并没有reduceByKey。哪来的呢?此处留一个悬念。
再看看Job1
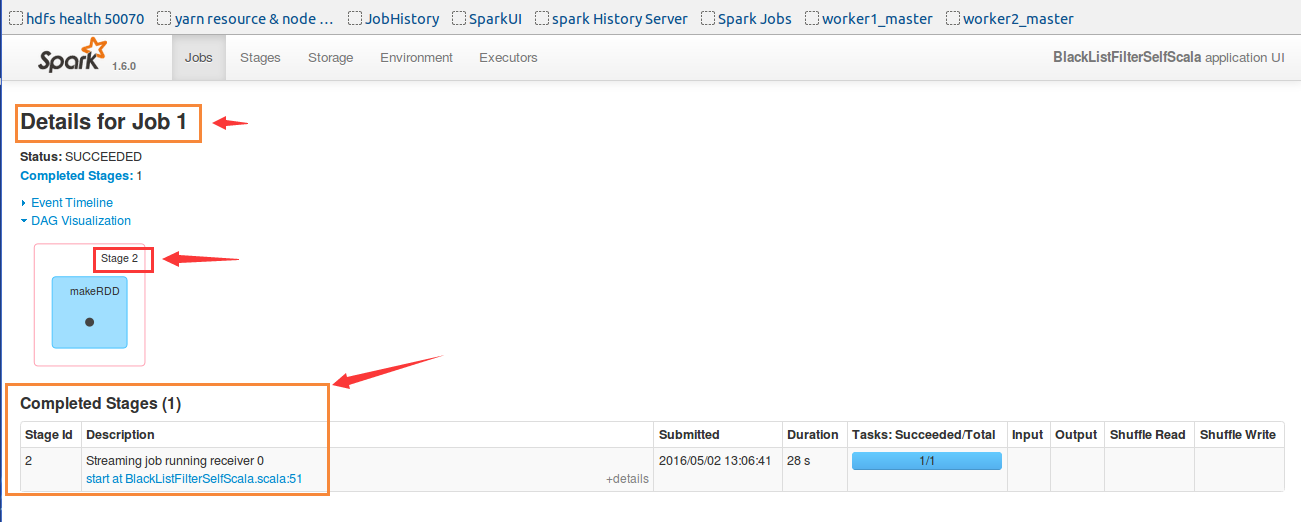

原来job1是专门用来接受数据的。接收数据的Receiver也专门有一个job。这个任务运行了28S,咱们任务的间隔是30S,并不是28S。疑问来了。
不过至少可以知道,数据是通过在Executor上运行job的方式来接收的。

Job2一看就知道是我们的业务逻辑。
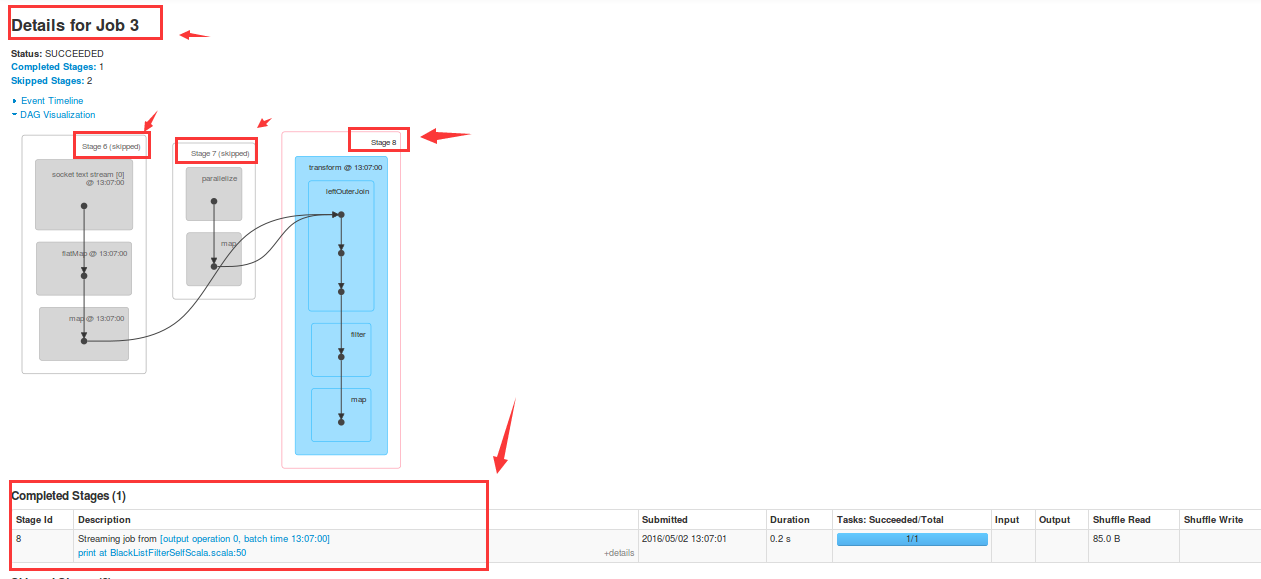
这里为什么重复了呢?
让我们尽请期待后续的讲解。
让我们再看看DStream,DStream是离散流;可以认为数据像水龙头中流出的水,DStream是下面的一个水桶,在设定的时间间隔内换一个空桶,之前的水桶取走,交给下游流水线处理(业务处理)。
此处可以看到,只是按设置的时间来触发换水桶,换句话说,只受时间维度的影响,因为,时间对所有的业务理解都是一样的,此设计是超棒的解耦。
感谢王家林老师的知识分享
王家林老师名片:
中国Spark第一人
感谢王家林老师的知识分享
新浪微博:http://weibo.com/ilovepains
微信公众号:DT_Spark
博客:http://blog.sina.com.cn/ilovepains
手机:18610086859
QQ:1740415547
邮箱:18610086859@vip.126.com
YY课堂:每天20:00现场授课频道68917580
王家林:DT大数据梦工厂创始人、Spark亚太研究院院长和首席专家、大数据培训专家、大数据架构师。















 76
76

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









