







音频格式
音频格式中 规定了使用多少 bits 来对信号进行编码。
- 无压缩的格式
- 无损压缩
- 有损压缩
1. wav 音频格式介绍
微软 和 IBM 于 1991 年 提出的资源交换的文件格式 RIFF( resource interchange File Format);
wav 是 属于RIFF 中的一个应用实例;
1.1 RIFF 的组成
RIFF的其他实例还包含了其他的音视频格式 AVI, 图像动画ANI;
RIFF 文件由一个表头 header, 多个区块 chunk 组成;
1.2 wav 的组成
打开该网址:
http://soundfile.sapp.org/doc/WaveFormat/
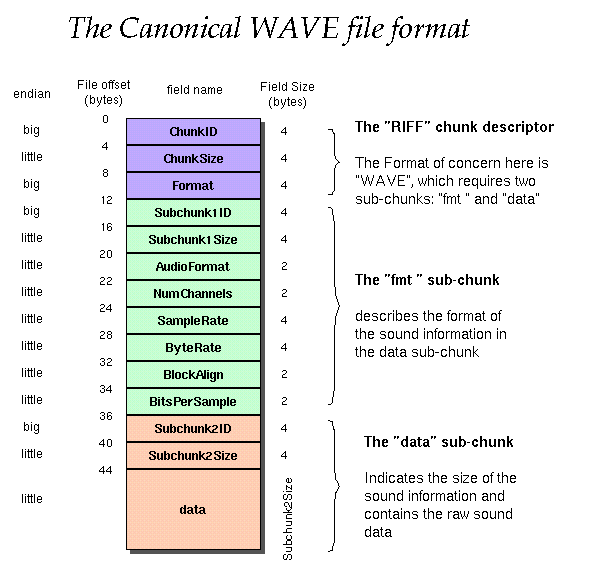
wav 的 Header : 使用 32 位正整数表示整个文件的大小, 故wav 大小不超过 4 GB;
第一个区块,格式子块,Format chunk: 记录了音频的相关格式信息包括如下:
编码格式, 通道数,采样率,Byte Rate 传输速率(字节每秒), 块对齐,
第二个区块,数据子块,data chunk :开始存储音频的数据,
注意到在数据块中,左通道和右通道的数据有依次间隔存放的,按照
左通道1,右通道1,左通道2, 右通道2 这样的顺序依次交替存放;

2. python 读取 wav 文件,
调用 struct module,
https://docs.python.org/3/library/struct.html?highlight=struct#struct.unpack_from
注意,使用 struct.unpack(),
其中,关键点:
- 字节顺序 byte order : 区分高位在前还是低位在前;
< 表示, 低位在前;
>表示,高位在前;
- 数据类型:
H unsigned short integer 2
H 表示无符号的短整形, integer, 占2 个字节;
I unsigned int integer 4
I: 表示无符号的整形, integer占4 个字节;
2.1 struct.unpack() 的使用
注意到根据字节序来判断使用的场景,
byteorder 是big: 即高位在前时, 使用 f.read()直接打开;
byteorder 是little: 即低位在前时, 使用 struct.unpack() 函数打开;
import struct
f = open("./male_audio.wav", mode = "rb") # 以二进制的只读模式打开该文件;
chunk_id = f.read(4) # 文件的前4byte 字节代表 RIFF;
print("the chunk id:", chunk_id)
# < 代表 低位在前, I:代表无符号的整数, 4byte;
chunk_size = struct.unpack('<I', f.read(4))[0]
print("the chunk size :", chunk_size)
wav_format = f.read(4)
print("the wav format", wav_format)
sub_chunck_1_id = f.read(4)
print("the first sub chunk id:", sub_chunck_1_id)
sub_chunck_1_size = struct.unpack('<I', f.read(4))[0]
print("the sub chunk 1 size: ", sub_chunck_1_size)
# < 代表 低位在前, H:代表无符号的短整数, 2个字节;
audio_format = struct.unpack('<H', f.read(2))[0]
print("the audio format", audio_format)
# PCM = 1 (i.e. Linear quantization)
# Values other than 1 indicate some form of compression.
# Mono = 1, Stereo = 2, etc.
num_channel = struct.unpack('<H', f.read(2))[0]
print(" the num channel of audio:", num_channel)
# sampel rate 8000, 44100, etc.
sample_rate = struct.unpack('<I', f.read(4))[0]
print("the sample rate: ", sample_rate)
#ByteRate == SampleRate * NumChannels * BitsPerSample / 8
byte_rate = struct.unpack('<I', f.read(4))[0]
print("the byte rate: ", byte_rate)
# BlockAlign == NumChannels * BitsPerSample/8
# The number of bytes for one sample including
# all channels. I wonder what happens when
# this number isn't an integer?
block_align = struct.unpack('<H', f.read(2))[0]
print(" the block align:", block_align)
# BitsPerSample 8 bits = 8, 16 bits = 16, etc.
bits_per_sample = struct.unpack('<H', f.read(2))[0]
print("the bits per sample:", bits_per_sample)
# ---- the following data sub chunk---
sub_chunck_2_id = f.read(4)
print("\n the sub chunk 2:", sub_chunck_2_id)
sub_chunck_2_size = struct.unpack('<I', f.read(4))[0]
print("the sub chunk_2_size:", sub_chunck_2_size)
data0 = struct.unpack('<H', f.read(2))[0]
print("the first data:", data0)
# 这里需要注意, 第一个前4 个字节中, 前两个
字节代表左声道, 后两字节代表右声道;
2.2 f.read() 函数的使用:
# ”读“的细节操作
# 1. # f.read(字节数):读取的是字节
# 字节数默认是文件长度;下标会自动后移
# f = open('test.txt','r')
# print(f.read())
# f.close()
# 2.f.readline([limit])
# 读取一行数据
# limit
# 限制的最大字节数
# f = open('test.txt', 'r')
#
# content = f.readline()#只读取一行
# print(content)
#
# content = f.readline()#只读取一行
# print(content)
# f.close()
# 3.f.readlines()
# 会自动的将文件按照换行符进行处理
# 将处理好的每一行组成一个列表返回
f = open('test.txt', 'r')
cn = f.readlines()
for line in cn:
print(line, end='')
f.close()
3. 其他存储格式
RIFF: 由微软和IBM提出;
AIFF : 苹果公司提出;
-
无损格式: FLAC
free lossless audio codec; -
lossy : 有损格式
MP3, mostly for music, based on:
• Modified discrete cosine transform (MDCT)
• Sub-band coding
• Advanced Audio Coding (AAC)
• OPUS
• Speex

















 1782
1782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









