










(Owed by: 春夜喜雨 http://blog.csdn.net/chunyexiyu)
参考:https://segmentfault.com/a/1190000040088969
参考:https://zhuanlan.zhihu.com/p/92654574
参考:https://www.sqlite.org/windowfunctions.html
引言
最近看资料时,突然看到数据库的窗口函数(window function),许多年未用数据库,窗口函数这块对自己来说竟然是一个未知领域,所以就去研究了研究。
下面以sqlite中的窗口函数作为研究的样例。
Window function support was first added to SQLite with release version 3.25.0 (2018-09-15).
先来看语法结构,与一个使用的样例,然后再来看看支持的功能有哪些。
窗口函数的语法形如:
window_function (expression) OVER (
[ PARTITION BY part_list ]
[ ORDER BY order_list ]
[ { ROWS | RANGE } BETWEEN frame_start AND frame_end ] )
使用样例形如:
select name, grade, class, score,
rank() over (PARTITION by grade order by score desc) as rank
from student;
使用注意事项:over后括号不可少
window_function over (…) as column_name
窗口函数约束
与普通函数不同,窗口函数中不能使用DISTINCT关键字。
窗口函数只能出现在SELECT语句结果集中与ORDER BY子句中。
Unlike ordinary functions, window functions cannot use the DISTINCT keyword. Also, Window functions may only appear in the result set and in the ORDER BY clause of a SELECT statement.
支持哪些window_function
窗口函数有两种,一种是集合窗口函数,一种是内置窗口函数。
Window functions come in two varieties: aggregate window functions and built-in window functions.
集合窗口函数列表:List of built-in aggregate functions
avg(X)
count(*)
count(X)
group_concat(X)
group_concat(X,Y)
max(X)
min(X)
sum(X)
total(X)
内置窗口函数列表:
row_number()
rank()
dense_rank()
percent_rank()
cume_dist()
ntile(N)
lag(expr)
lag(expr, offset)
lag(expr, offset, default)
lead(expr)
lead(expr, offset)
lead(expr, offset, default)
first_value(expr)
last_value(expr)
nth_value(expr, N)
窗口函数测试
先构造一些数据,和参考资料上类似,也基于分数score来排序的数据吧。
分别获取年级排名和班级平均分两项的值。
create table student(id number, name varchar(20), grade number, class number, score);
insert into student values(1, “lily”, 1, 1, 90);
insert into student values(2, “lucy”, 1, 1, 80);
insert into student values(3, “jenny”, 1, 2, 60);
insert into student values(4, “aron”, 1, 2, 80);
insert into student values(5, “rock”, 2, 1, 90);
insert into student values(6, “jim”, 2, 1, 90);
insert into student values(7, “jacky”, 3, 1, 90);
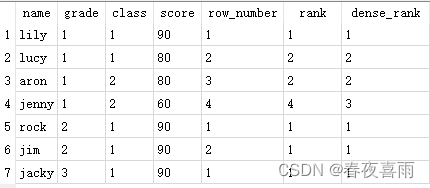
数据中有三个grade年级,获得年级内的排名ranking:
使用row_number()函数获得partition中序号
使用rank()函数获得排名
使用dense_rank()函数获得稠密排名
select name, grade, class, score,
row_number() over (PARTITION by grade order by score desc) as row_number,
rank() over (PARTITION by grade order by score desc) as rank,
dense_rank() over (PARTITION by grade order by score desc) as dense_rank
from student;
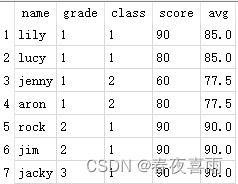
获得各年级班级的平均分,使用avg(score):
select name, grade, class, score,
avg(score) over (PARTITION by grade order by class) as avg
from student;
个人认识
窗口函数特点:
a. 首先是原结果集的内容是不变的,查询出来多少行多少列,这些内容不会减少。
还是这么多行;
b. 窗口函数所起的作用就是,首先会对结果集做一些分区处理partition,然后基于某列排序order,并基于窗口函数的不同,对结果集的一些内容进行使用,使用后形成新的列。
从开发者的角度来说:
查询数据时,先忽略掉窗口函数,使用查询语句从数据库中查询出结果集;
有了结果集之后,参考窗口函数的逻辑,使用partition分区+order对数据集排序,然后读取数据,附加一些计算,形成新的列附加到数据集后面。
所以窗口函数应该对查询效率影响不大,结果集通常也不会太大,并且已经查询出的结果集位于内存中,纯内存操作速度也是非常快的。
(Owed by: 春夜喜雨 http://blog.csdn.net/chunyexiyu)


















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











