







管道中的主要概念
DataFrame
管道组件
transformers
estimator
管道组件的属性
管道
怎么运行的
细节
参数
储存和装载管道
代码示例
示例:estimator,transformer和参数
示例:管道
型号选择(超参数调整)
管道中的主要概念
MLlib将机器学习算法的API标准化,以便将多种算法更容易地组合成单个流水线或工作流程。本节介绍了Pipelines API引入的关键概念,其中管道概念主要受到Scikit学习项目的启发。
DataFrame:该ML API使用Spark SQL的DataFrame作为ML数据集,可以容纳各种数据类型。例如,DataFrame可以具有存储文本,特征向量,真实标签和预测的不同列。
Transformer:transformer是一种可以将一个DataFrame转换为另一个DataFrame的算法。例如,ML模型是一个Transformer,它将具有特征的DataFrame转换为具有预测的DataFrame。
Estimator:estimator是一种可以适应DataFrame来生成Transformer的算法。例如,学习算法是在DataFrame上训练并产生模型的estimator。
Pipeline:一条管道链接多个transformer和estimator,以指定ML工作流程。
Paramater:所有transformoer和estimator现在共享用于指定参数的通用API。
DataFrame
机器学习可以应用于各种各样的数据类型,例如向量,文本,图像和结构化数据。 该API采用Spark SQL的DataFrame来支持各种数据类型。
DataFrame支持许多基本和结构化类型; 请参阅Spark SQL数据类型引用以获取支持的类型列表。 除了Spark SQL指南中列出的类型之外,DataFrame还可以使用ML Vector类型。
DataFrame可以从常规RDD隐式或显式创建。 有关示例,请参阅下面的代码示例和Spark SQL编程指南。
DataFrame中的列被命名。 下面的代码示例使用名称,如“text”,“features”和“label”。
管道组件
Transformers
是一种抽象,包括特征transformer和学习模型。在技术上,Transformers实现一种方法transform(),它通常通过附加一列或多列来将一个DataFrame转换成另一个。例如:
feature transformer可以使用DataFrame,读取列(例如文本),将其映射到新列(例如,特征向量)中,并输出附加了映射列的新DataFrame。
学习模型可能需要一个DataFrame,读取包含特征向量的列,预测每个特征向量的标签,并输出一个新的DataFrame,并附加预测标签作为列。
Estimators
estimators抽象学习算法的概念或适合或训练数据的任何算法。技术上,一个estimator实现一个方法fit(),它接受一个DataFrame并产生一个Model,它是一个Transformer。例如,诸如Logistic回归之类的学习算法是一个estimator,调用fit()训练一个Logistic回归模型,它是一个Model,因此是一个Transformer。
管道组件的属性
Transformer.transform()和Estimator.fit()都是无状态的。在未来,可以通过替代概念来支持有状态算法。
transformer或estimator的每个实例都有一个唯一的ID,可用于指定参数(如下所述)。
PipLine
在机器学习中,通常运行一系列算法来处理和学习数据。简单的文本处理工作流可能包括几个阶段:
将每个文档的文本分割成单词。
将每个文档的单词转换为数字特征向量。
使用特征向量和标签学习预测模型。
MLlib表示作为流水线的工作流程,该管道由要按特定顺序运行的一系列流水线阶段(transformer和estimator)组成。我们将使用这个简单的工作流作为本节的运行示例。
怎么运行的
管道被指定为阶段序列,每个阶段都是tranformer或estimator。 这些阶段按顺序运行,输入的DataFrame在通过每个阶段时被转换。 对于Transformer阶段,在DataFrame上调用transform()方法。 对于Estimator阶段,调用fit()方法来生成一个Transformer(它成为PipelineModel的一部分,或者适合Pipeline),并且在DataFrame上调用Transformer的transform()方法。
我们为简单的文本文档工作流程进行了说明。 下图显示了管道的训练时间。
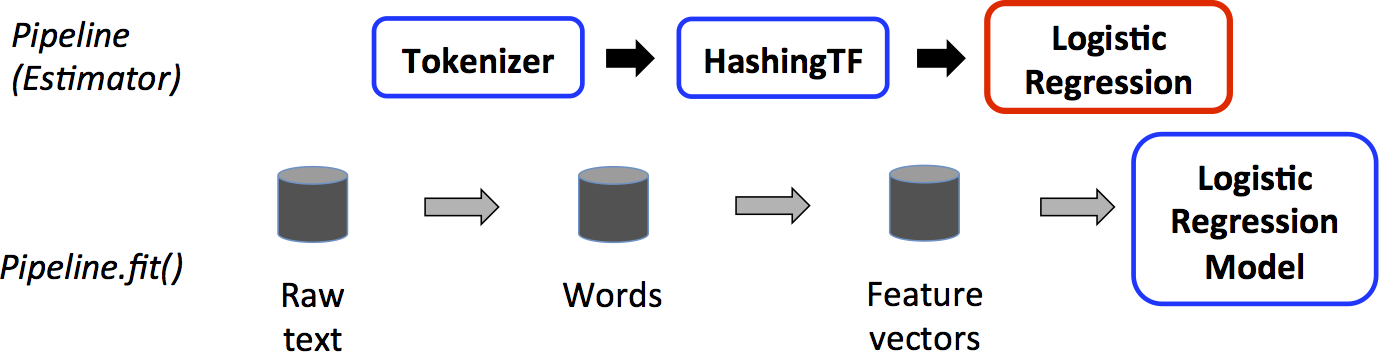
以上,顶行代表一个三级管道。前两个(Tokenizer和HashingTF)是transformer(蓝色),第三个(Logistic回归)是一个estimator(红色)。底行表示流经管道的数据,其中柱面指示DataFrames。在原始DataFrame上调用Pipeline.fit()方法,它具有原始文本文档和标签。 Tokenizer.transform()方法将原始文本文档分割成单词,向DataFrame添加一个带有单词的新列。 HashingTF.transform()方法将单词列转换为特征向量,将这些向量的新列添加到DataFrame。现在,由于Logistic回归是一个estimator,管道首先调用LogisticRegression.fit()来生成一个Logistic回归模型。如果流水线有更多的阶段,那么在将DataFrame传递到下一个阶段之前,它会在DataFrame上调用LogisticRegressionModel的transform()方法。
管道是一个estimator。因此,在Pipeline的fit()方法运行之后,它会生成一个PipelineModel,它是一个Transformer。此管道模型在测试时使用;下图说明了这种用法。
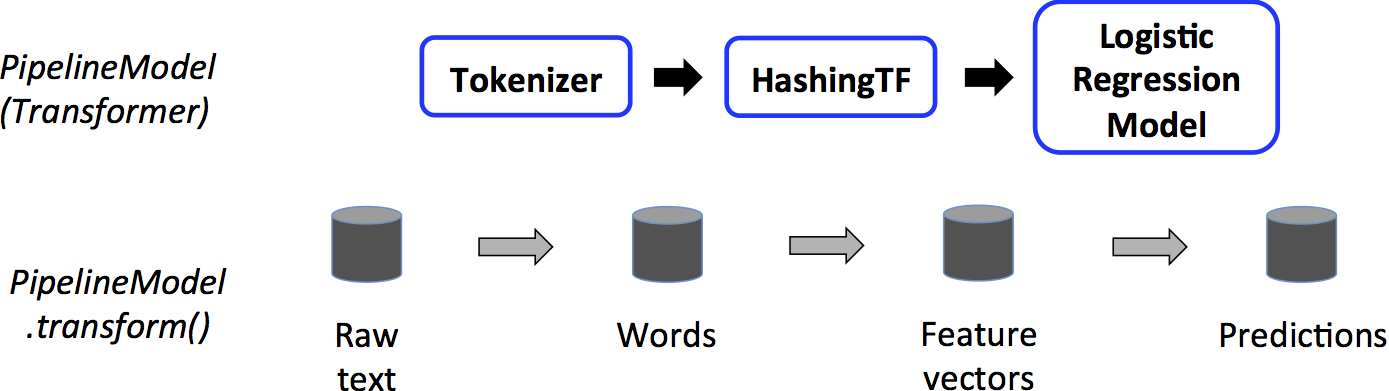
在上图中,PipelineModel具有与原始流水线相同的级数,但原始流水线中的所有estimator都已成为transformer。 当在测试数据集上调用PipelineModel的transform()方法时,数据按顺序传递通过拟合的管道。 每个阶段的transform()方法更新数据集并将其传递到下一个阶段。
管道和管道模型有助于确保培训和测试数据通过相同的功能处理步骤。
细节
DAG管道:管道的阶段被指定为有序数组。这里给出的示例全部用于线性管道,即每个阶段使用前一阶段生成的数据的管道。只要数据流图形成定向非循环图(DAG),就可以创建非线性流水线。该图当前是根据每个阶段(通常指定为参数)的输入和输出列名隐含指定的。如果管道形成DAG,则必须按拓扑顺序指定阶段。
运行时检查:由于管道可以对具有不同类型的DataFrames进行操作,因此不能使用编译时类型检查。管道和管道模型,而不是在实际运行流水线之前进行运行时检查。此类型检查是使用DataFrame模式完成的,这是DataFrame中列的数据类型的描述。
独特的管道阶段:管道的阶段应该是唯一的实例。例如,相同的实例myHashingTF不应该被插入管道两次,因为流水线阶段必须有唯一的ID。然而,不同的实例myHashingTF1和myHashingTF2(都可以是HashingTF类型)可以放在同一个管道中,因为不同的实例将被创建为不同的ID。
参数
MLlib的estimator和transformer使用统一的API来指定参数。
Param是具有独立文档的命名参数。 ParamMap是一组(参数,值)对。
将参数传递给算法有两种主要方法:
设置一个实例的参数。例如,如果lr是LogisticRegression的一个实例,可以调用lr.setMaxIter(10)使lr.fit()最多使用10次迭代。该API类似于spark.mllib软件包中使用的API。
将ParamMap传递给fit()或transform()。 ParamMap中的任何参数将覆盖先前通过setter方法指定的参数。
参数属于estimator和transformer的特定实例。例如,如果我们有两个LogisticRegression实例lr1和lr2,那么我们可以使用指定的maxIter参数来构建ParamMap:ParamMap(lr1.maxIter - > 10,lr2.maxIter - > 20)。如果在管道中存在maxIter参数的两个算法,这将非常有用。
储存和装载管道
通常情况下,将模型或管道保存到磁盘以供将来使用是值得的。 在Spark 1.6中,模型导入/导出功能已添加到Pipeline API中。 大多数基本的transformer都被支持,还有一些更基本的ML型号。 请参阅算法的API文档,以查看是否支持保存和加载。
代码示例
本节将给出说明上述功能的代码示例。 有关更多信息,请参阅API文档(Scala,Java和Python)。
示例:estimator,transformer和参数
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.ml.param.ParamMap
import org.apache.spark.sql.Row
// Prepare training data from a list of (label, features) tuples.
val training = spark.createDataFrame(Seq(
(1.0, Vectors.dense(0.0, 1.1, 0.1)),
(0.0, Vectors.dense(2.0, 1.0, -1.0)),
(0.0, Vectors.dense(2.0, 1.3, 1.0)),
(1.0, Vectors.dense(0.0, 1.2, -0.5))
)).toDF("label", "features")
// Create a LogisticRegression instance. This instance is an Estimator.
val lr = new LogisticRegression()
// Print out the parameters, documentation, and any default values.
println("LogisticRegression parameters:\n" + lr.explainParams() + "\n")
// We may set parameters using setter methods.
lr.setMaxIter(10)
.setRegParam(0.01)
// Learn a LogisticRegression model. This uses the parameters stored in lr.
val model1 = lr.fit(training)
// Since model1 is a Model (i.e., a Transformer produced by an Estimator),
// we can view the parameters it used during fit().
// This prints the parameter (name: value) pairs, where names are unique IDs for this
// LogisticRegression instance.
println("Model 1 was fit using parameters: " + model1.parent.extractParamMap)
// We may alternatively specify parameters using a ParamMap,
// which supports several methods for specifying parameters.
val paramMap = ParamMap(lr.maxIter -> 20)
.put(lr.maxIter, 30) // Specify 1 Param. This overwrites the original maxIter.
.put(lr.regParam -> 0.1, lr.threshold -> 0.55) // Specify multiple Params.
// One can also combine ParamMaps.
val paramMap2 = ParamMap(lr.probabilityCol -> "myProbability") // Change output column name.
val paramMapCombined = paramMap ++ paramMap2
// Now learn a new model using the paramMapCombined parameters.
// paramMapCombined overrides all parameters set earlier via lr.set* methods.
val model2 = lr.fit(training, paramMapCombined)
println("Model 2 was fit using parameters: " + model2.parent.extractParamMap)
// Prepare test data.
val test = spark.createDataFrame(Seq(
(1.0, Vectors.dense(-1.0, 1.5, 1.3)),
(0.0, Vectors.dense(3.0, 2.0, -0.1)),
(1.0, Vectors.dense(0.0, 2.2, -1.5))
)).toDF("label", "features")
// Make predictions on test data using the Transformer.transform() method.
// LogisticRegression.transform will only use the 'features' column.
// Note that model2.transform() outputs a 'myProbability' column instead of the usual
// 'probability' column since we renamed the lr.probabilityCol parameter previously.
model2.transform(test)
.select("features", "label", "myProbability", "prediction")
.collect()
.foreach { case Row(features: Vector, label: Double, prob: Vector, prediction: Double) =>
println(s"($features, $label) -> prob=$prob, prediction=$prediction")
}示例:管道
该示例遵循上述附图中所示的简单文本文档管道。
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.{HashingTF, Tokenizer}
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
// Prepare training documents from a list of (id, text, label) tuples.
val training = spark.createDataFrame(Seq(
(0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),
(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0)
)).toDF("id", "text", "label")
// Configure an ML pipeline, which consists of three stages: tokenizer, hashingTF, and lr.
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.001)
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr))
// Fit the pipeline to training documents.
val model = pipeline.fit(training)
// Now we can optionally save the fitted pipeline to disk
model.write.overwrite().save("/tmp/spark-logistic-regression-model")
// We can also save this unfit pipeline to disk
pipeline.write.overwrite().save("/tmp/unfit-lr-model")
// And load it back in during production
val sameModel = PipelineModel.load("/tmp/spark-logistic-regression-model")
// Prepare test documents, which are unlabeled (id, text) tuples.
val test = spark.createDataFrame(Seq(
(4L, "spark i j k"),
(5L, "l m n"),
(6L, "spark hadoop spark"),
(7L, "apache hadoop")
)).toDF("id", "text")
// Make predictions on test documents.
model.transform(test)
.select("id", "text", "probability", "prediction")
.collect()
.foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) =>
println(s"($id, $text) --> prob=$prob, prediction=$prediction")
}模型选择(超参数调整)
使用ML管道的一大优点是超参数优化。 有关自动模式选择的更多信息,请参阅“ML调整指南”
http://spark.apache.org/docs/latest/ml-pipeline.html
SPARK MLLIB















 1484
1484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









