






数据预处理时往往涉及多个文件,所以使用多个线程对文件进行处理能够加快整体的运行速度。而线程的操作往往对队列的操作。因为文件处理可以排成队列进行操作。
下面将先上一段对队列基本操作的代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#队列的基本操作 创建--初始化--出队--执行加1操作--入队--输出
import tensorflow as tf
#创建
q = tf.FIFOQueue(2, "int32") #队列元素个数 类型
#初始化enqueue_many
init = q.enqueue_many(([0, 10],))
#出队dequeue第一个元素
x = q.dequeue()
y = x+1
#入队enqueue
q_inc = q.enqueue([y])
with tf.Session() as sess:
init.run() #初始化运行
for _ in range(5): #运行五次队列操作
v, _ = sess.run([x, q_inc])
print(v)
可以看到输出结果如图:
下面将对其的线程的基本操作,献上源码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#tensorflow提供的线程操作函数主要是tf.Coordinator tf.QueueRunner;
#其中tf.Coordinator函数用法如下面代码的批注:
import tensorflow as tf
import numpy as np
import threading
import time
#线程终止判断函数 should_stop()函数返回true时停止;也可以通过request_stop通知其他线程停止,且将should_stop()置为true
def MyLoop(coord, worker_id):
while not coord.should_stop():
if np.random.rand() <0.1:
print("Stoping from id : %d\n"% worker_id,)
coord.request_stop()
else :
print("working on id : %d\n"%worker_id,)
time.sleep(1)
#申明类协同多个线程
coord = tf.train.Coordinator()
#申明创建5个线程
threads = [threading.Thread(target=MyLoop, args=(coord, i, )) for i in range(5)]
#启动所有线程
for t in threads:
t.start()
#等待所有线程退出
coord.join(threads)
书上的部分xrange(5)已被更改后运行结果如图:
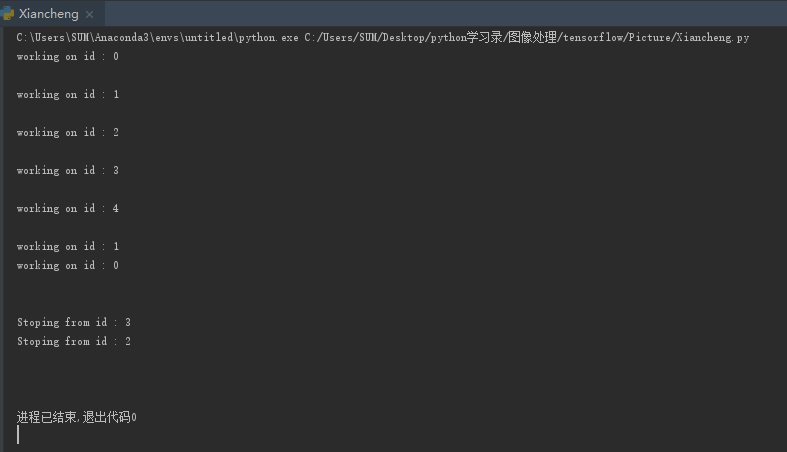
下面将来份多线程同时写入一个队列的操作:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#创建五个同时执行入队操作的线程,来实现对同一个队列的操作 tf.Coordinator tf.QueueRunner
import tensorflow as tf
#申明一个队列
queue = tf.FIFOQueue(100, "float")
#定义线程操作
enqueue_op = queue.enqueue([tf.random_normal([1])])
#创建多个同时操作的线程]
qr = tf.train.QueueRunner(queue, [enqueue_op]*5) #操作队列名称 操作方式 线程数
#将线程加入到制定集合
tf.train.add_queue_runner(qr)
#定义出队
out_tensor = queue.dequeue()
with tf.Session() as sess:
coord = tf.train.Coordinator() #启动线程
threads = tf.train.start_queue_runners(sess=sess, coord=coord) #启动数据集合上的线程
for _ in range(3):
print(sess.run(out_tensor)[0])
#停止线程
coord.request_stop()
coord.join(threads)
运行结果可以看到已经随机插入了三个数入队:
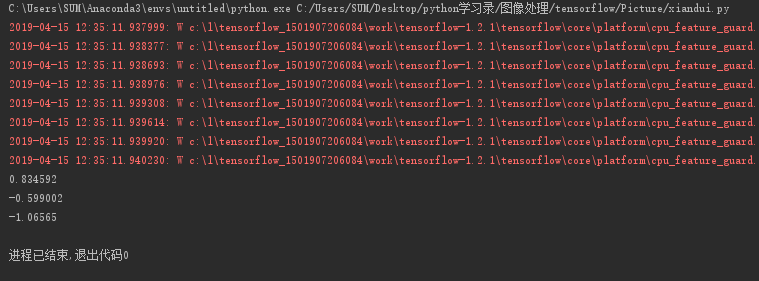
哈哈哈,你学会了吗?















 192
192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









