






数据结构
class OpHistory {
set<pair<utime_t, TrackedOpRef> > arrived;//按照达到时间从早到晚排序
set<pair<double, TrackedOpRef> > duration;//按照op的duration从小到大排序
Mutex ops_history_lock;//保护上面2个变量
bool shutdown;//osd down的时候设置
uint32_t history_size;//历史op保留的最大个数
uint32_t history_duration//历史op保留的最长时间
};
保存一定时间内已经完成的历史op信息。
Class OpTracker {
Class RemoveOnDelete{
OpTracker *tracker;
};
atomic64_t seq;//每个请求有个递增的id,初始为0
struct ShardedTrackingData {
Mutex ops_in_flight_lock_sharded;
xlist<TrackedOp *> ops_in_flight_sharded;
};
vector<ShardedTrackingData*> sharded_in_flight_list;//保存TrackedOp的分片列表
uint32_t num_optracker_shards;//分片列表的数量,不能动态修改
OpHistory history;//历史TrackedOp的实例
float complaint_time;//检查trackedop是否需要告警的时间阈值
int log_threshold;//每次check输出的最大的告警日志数量
public:
bool tracking_enabled;//是否要开启op跟踪
CephContext *cct;
};
整个op跟踪的管理类
class TrackedOp {
xlist<TrackedOp*>::item xitem;//在OpTracker中xlist中的一个item
protected:
OpTracker *tracker;
utime_t initiated_at;//请求到达的时间
list<pair<utime_t, string> > events; //op经历过的事件点及对应时间
mutable Mutex lock; //保护events
string current; //当前的事件
uint64_t seq; //OpTracker分配的seq
uint32_t warn_interval_multiplier; //限制输出op warning
};
单个op跟踪的实例父类
struct OpRequest : public TrackedOp {
int rmw_flags;//op flag指的是CEPH_OSD_RMW_FLAG_READ等
private:
Message *request; /// the logical request we are tracking
osd_reqid_t reqid;//客户端的请求id
uint8_t hit_flag_points;//带了哪些flag,指的是flag_reached_pg等,目前没有用到
uint8_t latest_flag_point;//最新的flag,目前没有用到
utime_t dequeued_time;//出op_shardedwq队列的时间
};
单个op跟踪的具体的实例
关键函数实现
OpTracker::RemoveOnDelete::operator()(TrackedOp *op)
TrackedOp的智能指针被释放的时候调用。
1.标记当前TrackedOp为done。
2.调用unregister_inflight_op将TraackedOp从OpTracker的sharded_in_flight_list对应的分片中释放
3.将TrackedOp加入到history实例中。
void OpHistory::cleanup(utime_t now)
在OpHistory::insert或OpHistory::dump_ops函数中会调用,及插入一个新的TrackedOp或者dump所有TrackedOp的时候。
该函数遍历OpHistory的arrived和duration列表,先删除时间上已经超出的TrackedOp。默认History会保存600s内的请求。在删除过多的op,默认History只保存20个请求。
bool OpTracker::check_ops_in_flight(std::vector<string> &warning_vector)
这个函数由osd的tick线程调用,定时的check还未完成的TrackerOp是否正常。
该函数遍历所有分片获取最老的op的时间保存在oldest_op,以及统计当前的op的总数量,保存在total_ops_in_flight。如果最老的op到当前时间比complaint_time要小,或者没有op则都正常,直接返回false。否则继续遍历所有分片,将TrackedOp到达时间小于complaint_time的慢请求找出来,保存在warning_vector中,并记录个数。当个数超过log_threshold则不再循环。
这里还有个小技巧是warning_vector先预留了第一个index,当全部统计完,再把统计信息保存在第一条里。
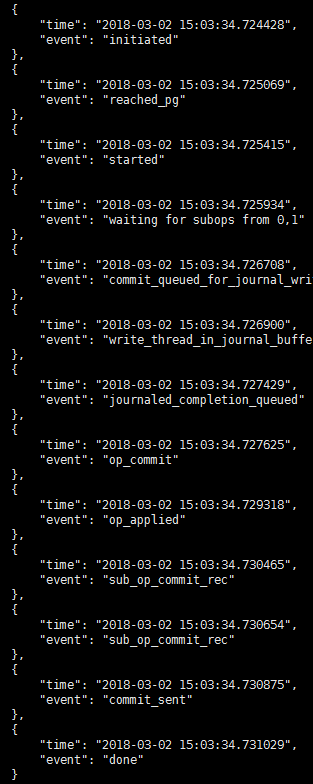
Event事件总结
常用event事件
| Event事件 | 含义 |
| Initiated | TrackedOp的构造函数中设置的事件,初始化事件 |
| reached_pg | 刚出osd的op_shardedwq队列 |
| started | 调用的地方很多,正常的主osd的io流程在do_op中调用,检查完所有的异常,开始调用execute_ctx |
| waiting for subops from | 主osd把请求发送给副本osd的时候 |
| commit_queued_for_journal_write | 请求准备进日志队列的时候 |
| write_thread_in_journal_buffer | 日志数据已经在buffer中准备好,还未写 |
| journaled_completion_queued | 日志已经写完了,回调进入队列 |
| op_commit | 多副本场景的写commit返回 |
| op_applied | 多副本主osd的apply返回 |
| sub_op_commit_rec | 多副本场景主osd处理副本osd的commit消息返回 |
| commit_sent | 当3副本请求的commit都返回的时候,具体由最晚的一个副本返回触发。 |
| sub_op_applied_rec | 多副本场景主osd处理副本osd的apply消息返回,正常的读写副本不会返回apply消息 |
| waiting for rw locks | 读写流程都会在do_op函数中获取下相关的锁,如果拿不到锁,该请求会被保存在objectcontext中,等待释放锁后再处理 |
Io流程的event事件时序
正常情况:
当写磁盘慢的情况读请求:
















 9779
9779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









