







 本文详细分析了Ceph中Pg状态机的转换过程,包括Pg的Peering流程,涉及GetInfo、GetLog、GetMissing和Active四个阶段。文中介绍了Pg状态机的基本概念,如临时PG、acting set和up set等,并讲解了up_thru和past_interval的作用。此外,还讨论了状态机的状态响应事件和主要流程,阐述了如何在不同阶段处理数据交互和同步。
本文详细分析了Ceph中Pg状态机的转换过程,包括Pg的Peering流程,涉及GetInfo、GetLog、GetMissing和Active四个阶段。文中介绍了Pg状态机的基本概念,如临时PG、acting set和up set等,并讲解了up_thru和past_interval的作用。此外,还讨论了状态机的状态响应事件和主要流程,阐述了如何在不同阶段处理数据交互和同步。
数据结构
pg_interval_t{
vector<int32_t> up, acting;//当前pg_interval的up和acting的osd列表
epoch_t first, last;//该interval的起始和结束epoch
bool maybe_went_rw;//在这个阶段是否可能有数据读写
int32_t primary;//主osd
int32_t up_primary;//up状态的主osd
}
PriorSet {
Const bool ec_pool;//是否是ec pool
set<pg_shard_t> probe; //需要probe的osd
set<int> down; //当前是down的osd
map<int, epoch_t> blocked_by; //导致pg_down为true的osd及对应osdmap的epoch
bool pg_down; //pg是否为down
boost::scoped_ptr<PGBackend::IsRecoverablePredicate> pcontdec;//判断pg是否可恢复的函数指针
}
pg_info_t {
spg_t pgid;//pgid和shardid信息
eversion_t last_update; // last object version applied to store.当前osd最新的一次更新
eversion_t last_complete; // last version pg was complete through.要保证所有osd都更新的版本号
epoch_t last_epoch_started;// last epoch at which this pg started on this osd //最新的一次变成active后的epoch
version_t last_user_version; // last user object version applied to store
eversion_t log_tail; // oldest log entry.
hobject_t last_backfill; //backfill的object指针,正常情况为hobject_t::get_max()
interval_set<snapid_t> purged_snaps;
pg_stat_t stats;//统计信息
pg_history_t history;//历史版本
pg_hit_set_history_t hit_set;//cache tier相关
};
pg_log_t{
eversion_t head; // 最新的pg_log_entry版本
eversion_t tail; // 最老的pg_log_entry
eversion_t can_rollback_to;//可以回滚的版本
eversion_t rollback_info_trimmed_to;//回滚场景可以trim的版本
list<pg_log_entry_t> log; //具体的pg_log_entry信息
};
pg_missing_t {
map<hobject_t, item> missing;//丢失对象和版本
map<version_t, hobject_t> rmissing;
};
class MissingLoc {
map<hobject_t, pg_missing_t::item> needs_recovery_map;//需要恢复的对象和版本信息
map<hobject_t, set<pg_shard_t> > missing_loc;//表示该对象在哪些osd上存在
set<pg_shard_t> missing_loc_sources;//存在missing对象的osd列表
PG *pg;
set<pg_shard_t> empty_set;
};
概要分析
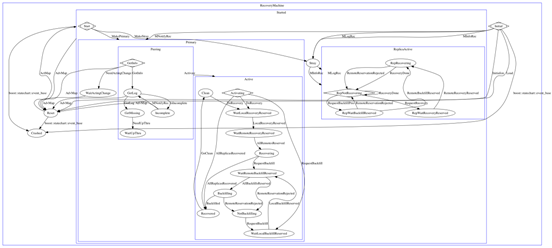
Pg状态机的总体状态转换图
Peering过程中的交互图
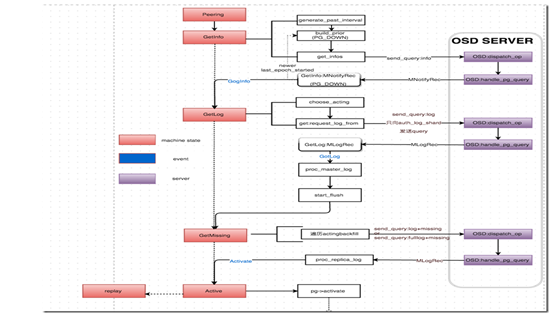
整体来看peering分为4个阶段:Getinfo,Getlog,Getmissing,Active。必要的时候在getmissing之后会有个waitupThru。
Getinfo:pg的主osd收集其他从osd上pg_info_t的信息。
GetLog:选出拥有权威日志的osd,如果不是主则从该osd拉去权威日志给主osd。
GetMissing:主osd去其他osd上拉取pg_entry_t,通过和权威日志对比pg_entry_t来判断各个osd上缺失的object信息。
Active:激活主osd和从osd
基本概念
临时PG、acting set和up set
acting set为pg对应的osd列表,其中列表第一个为主osd。一般情况下acting set和up set是一样的。假设一个pg的acting为[1,2,3]。当1挂了后up为[4,2,3]。这个时候由于4是新加入该pg的osd,上面并没有数据,且需要进行backfill。这个时候会产生一个临时pg。则up为[4,2,3]。但是acting还是为[2,3]。
Up_thru
简单举例:当某个pg对应的osd列表为[1,2],min_size为1。当osd.1和osd.2依次挂掉,可能会有2种情况:
情况1:osd.1挂了,osd.2还未完成peering阶段,osd.2紧接着挂了。这个时候数据无法写入osd.2。
情况2:osd.1挂了,osd.2完成peering进入active后挂了。这个时候该pg存在一个时间窗口可以正常写入数据。
当osd.1重新启动后,如果是情况1,因为没有新数据写入,则pg可以正常完成peering。如果是情况2,有可能一部分数据只在osd.2上存在,则无法完成peering。
为了区分情况1和情况2,所以引入up_thru。up_thru记录了每个osd完成peering的epoch值,osdmap会维护up_thru[osd]的数组。
引入up_thru后,假设初始的up_thru为0。则情况1中up_thru[osd.2]为0,而情况2中up_thru[osd.2]不为0。
Osdmap维护
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









