






背景
在测试的过程中发现,当给集群执行了ceph osd set norecover,ceph -s仍然能够看到集群中有recovery io持续几个小时。
问题复现
Ceph -s命令可以发现:当client io较大的时候,才会出现recovery io。如果没有client io的情况也不会有recovery io。怀疑recovery io是由于client io触发的。
代码分析
在PrimaryLogPG::do_op函数中,即client io必调的函数中会对object进行判断,代码如下:
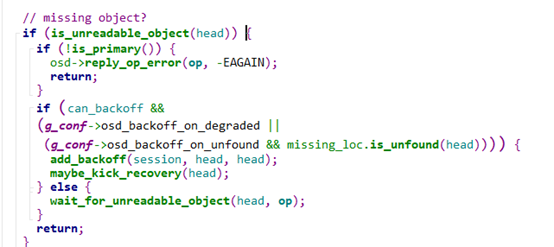
判断当前对象是否可读,如果当前对象在missing列表中,即恢复的队列中,那么会调用wait_for_unreadable_object函数,则继续调用maybe_kick_recovery函数。

Maybe_kick_recovery会判断这个object是主osd上missing的,还是需要副本osd上去删除的,或者push到副本osd上来做响应的recovery处理。
可见,在client io的处理流程是会触发recovery io的。
我们再来看一下norecover的设置,以及生效的流程。执行命令ceph osd set norecover,是在osdmap上设置了CEPH_OSDMAP_NORECOVER flag。当osd收到osdmap的更新会调用pause_recovery,OSDService实例recovery_paused字段设置为true。在整个pg的恢复流程中,会先将pg入队列,然后有shardthreadpool来处理恢复。整个入队列的流程如下:
queue_for_recovery->_maybe_queue_recovery->_recover_now,当_recovery_now为true的时候才会调用_queue_for_recovery将请求插入等待队列进行恢复处理。

如果设置了norecover,则recovery_paused是true,_recover_now是要返false的,pg则无法进入恢复等待队列中
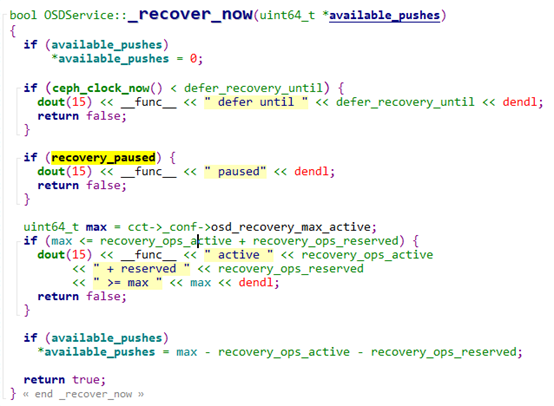
从上面的分析可以看出,设置norecover,可以阻止正常recovery流程的进行,但是client io触发的recovery流程,由于没有调用到_recover_now,所以仍然可以进行。















 2396
2396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









