






第一次写,是直接写还是先走程序。
1、都是些废话
最近失业了,晚上睡不着,实在没事干。所以来练习下爬虫技术,第一次创作,写的不好,勿喷。
2、正式开始
想要练习下全站试爬虫,找了几个网站,觉得还是从最简单的开始,因为本人喜欢看小说,所以就以全书网为例。根据自己实践证明,全书网没有做任何反爬技术(适用于初学者)。
3、分析网站并编写代码
3.1、获取最大分类
网址为:http://www.quanshuwang.com/ (百度搜索全书网,打开第一个),首先分析网站,个人经验,以类目区分,很明显可以发现它的第一级类目(最大分类)

所以,第一步拿到它的类目信息(链接或者ID),右键查看网页源代码,可以清楚的看到,它的分类全部放在源码里面。通过查找发现,ul表现后面class值为唯一值,直接利用xpath,一步到位
html.xpath('//ul[@class="channel-nav-list"]/li/a/@href')
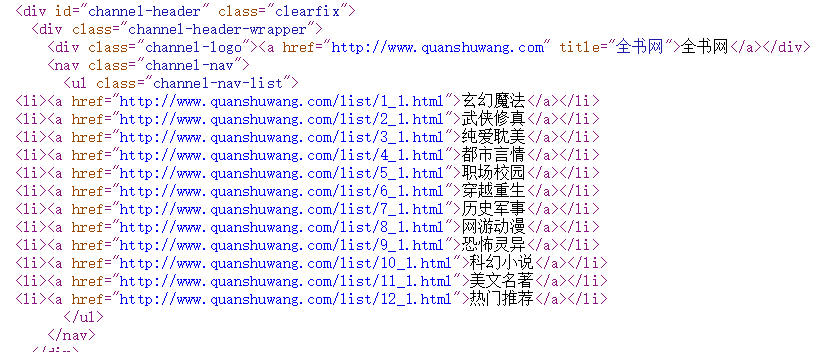
到此,一级类目已经拿到(第一部分代码已经完成)。
3.2、获取页码链接
拿到分类链接不要着急,喝杯茶,休息一下。通过这些链接发现,这些链接都是每个分类下的第一页的,所以要拿到它最大页码,做个循环拿到所有页码链接。先打开第一页链接,通过源码发现它的页码放在<div class="pagelink"标签下,继续用xpath获取第一页当中存在的页码的字段,得到结果:
['1', '<<', '2', '3', '4', '5', '6', '7', '8', '9', '10', '>', '>>', '951']
列表最后一个就是它的最大页码。
我们打开第二页可以发现,链接:http://www.quanshuwang.com/list/1_2.html ‘_’ 符号后面改变,
所以,做一个循环,获取它所有的页码链接,代码:
- link_list = []
- htm = requests.get(url).text
- html = etree.HTML(htm)
- max_page = html.xpath('//div[@class="pagelink"]/a/text()')[-1]
- for page in range(1,int(max_page)+1):
- link_list.append(url.replace('_1','_{}'.format(str(page))))
3.3、获取小说ID
有了所有页码的链接,就可以获取小说的名字和ID了,分析网站之后发现,我们所需要的链接形式为:http://www.quanshuwang.com/book/146/146582,手动点击需要跳转两次,但是仔细研究,可以发现book后面的code好像就是最后的ID去掉后面三位。所有我们先从它的页面链接中拿到ID和标题(最后保存文件的时候要用)。

观察源码,发现
<a target="_blank" title="至高审判长" href="http://www.quanshuwang.com/book_146582.html"
这句当中,有标题,有链接,但是我们要的的ID,所以用一个re,拿到标题和ID(因为要分割ID),最后在将ID分割,得到code。
- book_list = []
- htm = requests.get(url).content.decode('gbk')
- code_list=re.findall(r'target="_blank"title="(.*?)"href="http://www.quanshuwang.com/book_(.*?).html"',str(htm))
- for code in code_list:
- f_code = code[1].replace(code[1][-3:],'')
- book_list.append([f_code,code])
3.4、获取章节
有了book链接,打开链接我们发现,它所有的章节都放在一个网页当中,所以我们可以轻易的就得到他的章节链接,获取章节比较简单,直接xpath获取。
html.xpath('//li/a/@href')[12:]
解释一下为什么要写[12:]。我是直接从li标签下面获取的,所以多了前面12个分类的链接,通过列表索引分割就OK了。
3.5、获取正文
这里才是最想要的部分,它的内容好像全放在标签<section中,所以直接用bs4就可以定位到,但是我们得到的内容都是中文乱码,从下面这句发现,网页编码格式是‘gbk’,所以做个解码就行了,最后对拿到的内容清洗一下,去掉多余的标签就OK。
- <meta http-equiv="Content-Type" content="text/html; charset=gbk" />
到此结束
4、整理代码
一共有十二个分类,所以我开了十二个线程,可以由于网络原因,至今代码还在运行。所以想看小说了,不要找我,我还没下载完,推荐你一个更好的方法,直接在网页下载会比较快一点。哦,忘了,全书网好像不能下载,要不然我爬它干啥。
其实,直接在线看是最快的,反正你流量多,反正我用的WiFi。
部分代码:
- import requests
- from lxml import etree
- import re
- from bs4 import BeautifulSoup
- import threading
- #分类链接
- def get_cal():
- url = 'http://www.quanshuwang.com/'
- htm = requests.get(url).text
- html = etree.HTML(htm)
- link = html.xpath('//ul[@class="channel-nav-list"]/li/a/@href')
- return link
- #页码链接
- def get_url(url):
- link_list = []
- htm = requests.get(url).text
- html = etree.HTML(htm)
- max_page = html.xpath('//div[@class="pagelink"]/a/text()')[-1]
- for page in range(1,int(max_page)+1):
- link_list.append(url.replace('_1','_{}'.format(str(page))))
- return link_list
- #小说id
- def get_book_link(url):
- book_list = []
- htm = requests.get(url).content.decode('gbk')
- code_list = re.findall(r'target="_blank" title="(.*?)" href="http://www.quanshuwang.com/book_(.*?).html"',str(htm))
- for code in code_list:
- f_code = code[1].replace(code[1][-3:],'')
- book_list.append([f_code,code])
- return book_list
- #获取章节
- def get_dir(code):
- url = 'http://www.quanshuwang.com/book/{}/{}'.format(code[0],code[1][1])
- htm = requests.get(url).content.decode('gbk')
- html = etree.HTML(str(htm))
- return html.xpath('//li/a/@href')[12:]
- #获取章节内容
- def get_content(url):
- htm = requests.get(url).content.decode("gbk")
- html = BeautifulSoup(str(htm),'lxml')
- content = html.select("section")[0].get_text()
- del_ = re.findall(r'style6(.*?)style4',str(content),re.S)[0]
- return content.replace(del_,'').replace('style6style4();','').replace('style5();','').replace('\r\n','').replace('加入书签举报错误','')















 463
463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









