







从学习C语言开始,就了解编译,链接,装载,静态库,共享库,动态库等等这些概念,网上关于这个的文章有很多,但各有侧重,现在趁做Linux内核这门课的实验的机会,做一个系统的总结吧。
一、预处理、编译、链接
我们平常编写的源文件(.C文件)是不能直接放到机器上运行的,它只不过是一个带”.c”后缀的文本文件而已,需要经过一定的处理才能转换成机器上可运行的可执行文件。
基本过程用下面这个图(就不自己画了,借用 elfprincexu 的 )表示:
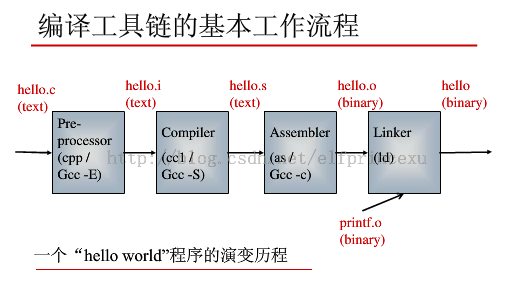
从图上可知,整个代码的编译过程分为编译和链接两个过程。
其中编译过程又分为两个阶段:编译和汇编。
编译
编译是读取源程序(字符流),对之进行词法和语法的分析,将高级语言指令转换为功能等效的汇编代码,源文件的编译过程主要包含两个阶段:
第一阶段是:预处理阶段
在编译之前,需要经过预处理过程。预处理阶段将根据已放置的文件中的预处理指令来对源文件进行一些修改。#define、#include指令就是预处理指令。
预处理阶段主要是以下几方面的处理:
头文件包含指令,它把#include包含进来的.h 文件插入到#include所在的位置,把头文件中的定义统统加入到它所产生的输出文件中。
宏定义指令,如#define Max 100;
把源程序中使用到的用#define定义的宏用实际的字符串代替。条件编译指令,如#ifdef、 #ifndef、#else、#elif、#endif等。
这些伪指令的引入使得程序员可以通过定义不同的宏来决定编译程序对哪些代码进行处理。预编译程序将根据有关的文件,将那些不必要的代码过滤掉。预编译程序可以识别一些特殊的符号。预编译程序对于在源程序中出现的这些串将用合适的值进行替。预编译程序对源程序进行一些替换,生成一个没有宏定义、没有条件编译指令、没有特殊符号的输出文件。下一步,此输出文件将作为编译程序的输出而被翻译成为机器指令。
需要注意的一点的是预处理阶段并不属于预编译过程,
第二个阶段是:编译、优化
经过预编译得到的输出文件中只有常量,一般都是一些指令。
编译程序首先检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,把代码翻译成等价的中间代码(汇编码)。
汇编
接下来就是汇编过程了,就是把汇编代码翻译成目标机器指令的过程,这一过程得到的就是目标文件。
通常一个目标文件中至少有两个段:代码段和数据段;
代码段:该段中所包含的主要是程序的指令。该段一般是可读和可执行的,但一般却不可写;
数据段:主要存放程序中要用到的各种全局变量或静态的数据。
UNIX环境下主要有三种类型的目标文件:
- 可重定位文件:其中包含有适合于其它目标文件链接来创建一个可执行的或者共享的目标文件的代码和数据。
- 共享的目标文件:这种文件存放了适合于在两种上下文里链接的代码和数据。第一种是链接程序可把它与其它可重定位文件及共享的目标文件一起处理来创建另一个目标文件;第二种是动态链接程序将它与另一个可执行文件及其它的共享目标文件结合到一起,创建一个进程映象。
- 可执行文件:它包含了一个可以被操作系统创建一个进程来执行的文件。
汇编程序生成的实际上是第一种类型的目标文件。对于后两种还需要其他的一些处理方能得到,这个就是链接程序的工作了。
链接
由汇编程序生成的目标文件并不能立即就被执行,可能在程序中调用了某个库文件中的函数(比如printf)等等,这就是链接程序的工作了。链接程序将有关的目标文件彼此相连接,也即将在一个文件中引用的符号同该符号在另外一个文件中的定义连接起来,使得所有的这些目标文件成为一个能够按操作系统装入执行的统一整体。
链接方式通常有两种:静态链接和动态链接。
对于不同链接方式,有相应的函数库,通常库分为:静态库,动态库。
静态链接与静态库
- 静态库就是一些目标文件的集合,以.a结尾。静态库在程序链接的时候使用,链接器会将程序中使用。
- 到函数的代码从库文件中拷贝到可执行程序中。一旦链接完成,在执行程序的时候就不需要静态库了。
- 由于每个使用静态库的可执行文件都需要拷贝所用函数的代码,所以静态链接的文件会比较大。
动态链接与动态库
动态库是共享库。根据装载的方式不同,动态链接分为两种:
- 装载时动态链接:这程序链接时候并不像静态库那样在拷贝使用函数的代码,而只是作些标记。然后在程序开始启动运行的时候,动态地加载所需模块;当程序执行时,利用链接信息加载库函数代码并在内存中将其链接入调用程序的执行空间中,其主要目的是便于代码共享。(共享动态链接库的原理可以看看这篇文章 http://blog.chinaunix.net/uid-26983585-id-3364514.html )
- 运行时动态链接:程序运行前并不知道将会调用哪些动态库函数,在运行过程中根据需要决定应调用哪个函数,而不是像上一种方式在程序启动的时候加载。与这种方式对应的库称为动态加载库。
共享库链接出来的文件比静态库要小得多,但是,由于动态链接方式运行时需要动态加载库函数,所以效率不如静态链接。
我们可以自己创建库文件,可以参考这两篇文章: gcc编译动态和静态链接库 , GCC编译器下的-L与-l的区别 .
二、ELF文件格式
ELF是一种用于二进制文件、可执行文件、目标代码、共享库和核心转储的标准文件格式。是UNIX系统实验室(USL)作为应用程序二进制接口(Application Binary Interface,ABI)而开发的,也是Linux的主要可执行文件格式。
ELF文件由4部分组成,分别是
- ELF头(ELF header),是对elf文件整体信息的描述,在32位系统下是56的字节,在64位系统下是64个字节。
- segment表,这个表是加载指示器
- elf的主题,对于可执行文件来说,最主要的就是数据段和代码段。
- section表,对可执行文件来说,没有用,在链接的时候有用,是对代码段数据段在链接时的一种描述。
实际上,一个文件中不一定包含全部内容,而且他们的位置也未必如同所示这样安排,只有ELF头的位置是固定的,其余各部分的位置、大小等信息由ELF头中的各项值来决定。
elf文件的组成可以使用下图来描述

(该图片来自Linux C编程作者宋劲斌)
program header table 实际上就是segment table。 segments 是从运行的角度来描述elf文件, sections是从链接的角度来描述elf文件的。
三、装载程序
当我们在Linux的命令行下输入一个命令执行某个ELF程序时,shell进程会调用fork()创建一个新的进程,然后新的进程调用execve()来执行ELF文件,原先的shell进程继续返回等待刚才启动时新进程结束,然后继续等待用户输入命令。随着一个新进程的出现,操作系统会为它创建一个独立的虚拟地址空间。
在进入execve()系统调用之后,Linux内核就开始进行真正的装载工作。在内核中,execve()系统调用相应的入口是sys_execve(),作用:参数的检查复制;调用do_execve(),流程:查找被执行的文件,读取文件的前128个字节以判断文件的格式是elf还是其它;调用search_binary_handle(),流程:通过判断文件头部的魔数确定文件的格式,并且调用相应的装载处理程序。ELF可执行文件的装载处理过程叫load_elf_binary()。
简单的分析下linux内核代码
search_binary_handler:
int search_binary_handler(struct linux_binprm *bprm)
{
...
retry:
read_lock(&binfmt_lock);
//查找 linux_binfmt
list_for_each_entry(fmt, &formats, lh) {
if (!try_module_get(fmt->module))
continue;
read_unlock(&binfmt_lock);
bprm->recursion_depth++;
//对于 elf 文件,执行的就是 load_elf_binary
retval = fmt->load_binary(bprm);
read_lock(&binfmt_lock);
...
}load_elf_binary
static int load_elf_binary(struct linux_binprm *bprm)
{
//获取elf头信息
loc->elf_ex = *((struct elfhdr *)bprm->buf);
if (loc->elf_ex.e_phentsize != sizeof(struct elf_phdr))
goto out;
if (loc->elf_ex.e_phnum < 1 ||
loc->elf_ex.e_phnum > 65536U / sizeof(struct elf_phdr))
goto out;
size = loc->elf_ex.e_phnum * sizeof(struct elf_phdr);
retval = -ENOMEM;
elf_phdata = kmalloc(size, GFP_KERNEL);
if (!elf_phdata)
goto out;
...
//获取可执行文件的解析器
for (i = 0; i < loc->elf_ex.e_phnum; i++) {
if (elf_ppnt->p_type == PT_INTERP) {
...
}
...
if (elf_interpreter) {
unsigned long interp_map_addr = 0;
elf_entry = load_elf_interp(&loc->interp_elf_ex,
interpreter,
&interp_map_addr,
load_bias);
if (!IS_ERR((void *)elf_entry)) {
interp_load_addr = elf_entry;
elf_entry += loc->interp_elf_ex.e_entry;
}
if (BAD_ADDR(elf_entry)) {
retval = IS_ERR((void *)elf_entry) ?
(int)elf_entry : -EINVAL;
goto out_free_dentry;
}
reloc_func_desc = interp_load_addr;
allow_write_access(interpreter);
fput(interpreter);
kfree(elf_interpreter);
} else {
elf_entry = loc->elf_ex.e_entry;
if (BAD_ADDR(elf_entry)) {
retval = -EINVAL;
goto out_free_dentry;
}
}
}load_elf_binary()的主要流程如下:
检查ELF可执行文件格式的有效性。
找到动态链接器的路径,为动态链接准备。
读取可执行文件的程序头,并且创建虚拟空间与可执行文件的映射关系。
初始化ELF进程环境。
将系统调用的返回地址修改成ELF可执行文件的入口点,这个入口点取决于程序的链接方式,对于静态链接的ELF可执行文件,它就是ELF文件的文件头中e_entry所指的地址;对于动态链接的ELF可执行文件,程序入口点就是动态链接器。
动态链接基本分为三步:先是启动动态链接器本身,然后装载所有需要的共享对象,最后重定位和初始化。
参考文章:
http://blog.chinaunix.net/uid-23592843-id-223539.html
http://www.360doc.com/content/13/0817/07/7377734_307732604.shtml

















 879
879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









