







通过前面对ELF文件格式的介绍,使我们对ELF目标文件从整体轮廊到某些局部的细节都有了一定的了解。接下来的问题是:当我们有两个目标文件时,如何将它们链接起来形成一个可执行文件?这个过程中发生了什么?这基本上就是链接的核心内容:静态链接。在这一节里,我们将使用下面这两个源代码文件a.c和b.c作为例子展开分析:
/a.c*/
extern int shared;
int main(){
int a=100;
swap(&a, &shared);
}
/b.c*/
int shared = 1;
void swap(int* a, int* b){
*a ^= *b ^= *a ^= *b;
}
假设我们的程序只有这两个模块a.c和b.c。首先我们使用gcc将a.c分别编译成目标文件a.o和b.o:
$ gcc -c a.c b.c
经过编译以后我们就得到了a.o和b.o这两个目标文件。从代码中可以看到,b.c总其定义了两个全局符号,一个是变量shared,另外一个是函数swap:a.c里面定义了一个全局符号就是main。模块a.c里面引用到了b.c里面的swap和shared。我们接下来要做的就是把a.o和b.o这两个目标文件链接在一起并最终形成一个可执行文件ab。
1 空间与地址分配
对于链接器来说,整个链接过程中,它就是将几个输入目标文件加工后合并成一个输出文件。那么在这个例子里,我们的输入就是目标文件a.o和b.o,输出就是可执行文件ab。我们在前面详细分析了ELF文件的格式,我们知道,可执行文件中的代码段和数据段都是由输入的目标文件中合并而来的。那么我们链接过程就很明显产生了第一个问题:对于多个输入目标文件,链接器如何将它们的各个段合并到输出文件?或者说,输出文件中的空间如何分配给输入文件?
1.1 按序叠加
一个最简单的方案就是将输入的目标文件按照次序叠加起来,如图4-1所示。
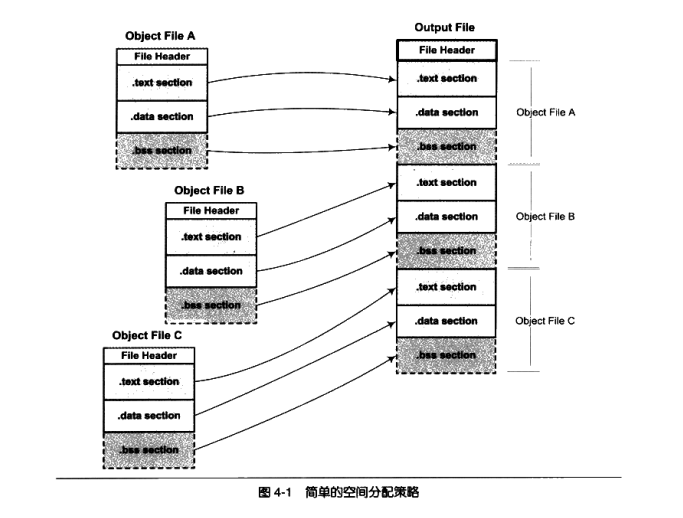
图4-1中的做法的确很简单,就是直接将各个目标文件依次合并。但是这样做会造成一个问题,在有很多输入文件的情况下,输出文件将会有很多零散的段。比如一个规模稍大的应用程序可能会有数百个目标文件,如果每个目标文件都分别有.text段、.data段和.bss段,那最后的输出文件将会有成百上千个零散的段。这种做法非常浪费空间,因为每个段都须要有一定的地址和空间对齐要求,比如对于x86的硬件来说,段的装载地址和空间的对齐单位是页,也就是4096字节。那么就是说如果一个段的长度只有1个字节,它也要在内存中占用4096字节。这样会造成内存空间大量的内部碎片,所以这并不是一个很好的方案
1.2 相似段合并
一个更实际的方法是将相同性质的段合并到一起,比如将所有输入文件的.text合并到输出文件的.text段,接着是.data段、.bss段等,如图4-2所示
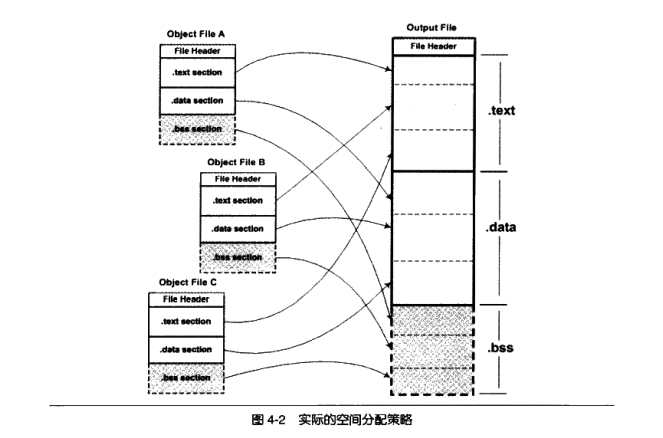
正如我们前文所提到的,“.bss”段在目标文件和可执行文件中并不占用文件的空间,但是它在装载时占用地址空间。所以链接器在合并各个段的同时,也将“.bss”合并,并且分配虚拟空间。从“.bss”段的空间分配上我们可以思考一个问题,那就是这里的所谓的“空间分配”到底是什么空间?
“链接器为目标文件分配地址和空间”这句话中的“地址和空间”其实有两个含义:第一个是在输出的可执行文件中的空间:第二个是在装载后的虚拟地址中的虚拟地址空间。对于有实际数据的段,比如“.text”和“.data”来说,它们在文件中和虚拟地址中都要分配空间,因为它们在这两者中都存在:而对于“.bss”这样的段来说,分配空间的意义只局限于虚拟地址空间,因为它在文件中并没有内容。事实上,我们在这里谈到的空间分配只关注于虚拟地址空间的分配,因为这个关系到链接器后面的关于地址计算的步骤,而可执行文件本身的空间分配与链接过程关系并不是很大。
现在的链接器空间分配的策略基本上都采用上述方法中的第二种,使用这种方法的链接一般都采用一种叫两步链接(Two-pass Linking)的方法。也就是说整个链接过程分两步:
- 第一步 空间与地址分配:扫描所有的输入目标文件,并且获得它们的各个段的长度、属性和位置,并且将输入目标文件中的符号表中所有的符号定义和符号引用收集起来,统一放到一个全局符号表。这一步中,链接器将能够获得所有输入目标文件的段长度,并且将它们合并,计算出输出文件中各个段合并后的长度与位置,并建立映射关系。
- 第二步符号解析与重定位使用上面第一步中收集到的所有信息,读取输入文件中段的数据、重定位信息,并且进行符号解析与重定位、调整代码中的地址等。事实上第二步是链接过程的核心,特别是重定位过程
我们使用ld链接器将a.o和b.o链接起来:
$ ld a.o b.o -e main -o ab
-e main表示将main函数作为程序入口,ld链接器默认的程序入口为_start-o ab表示链接输出文件名为ab,默认为a.out
让我们使用obidump来查看链接前后地址的分配情况,如下所示:
$ objdump -h a.o
...
Sections:
Idx Namne Size VMA LMA File off Algn
0 .text 00000034 00000000 00000000 00000034 2**2
CONTENTS,ALLOC,LOAD,RBLOC,READONLY,CODE
1 .data 00000000 00000000 00000000 00000068 2**2
CONTENTS,ALLOC,LOAD,DATA
2 .bss 00000000 00000000 00000000 00000068 2**2
ALLOC
...
$ objdump -h b.o
Sections:
Idx Namne Size VMA LMA File off Algn
0 .text 0000003e 00000000 00000000 00000034 2**2
CONTENTS,ALLOC,LOAD,RBLOC,READONLY,CODE
1 .data 00000004 00000000 00000000 00000074 2**2
CONTENTS,ALLOC,LOAD,DATA
2 .bss 00000000 00000000 00000000 00000078 2**2
ALLOC
...
$ objdump -h ab
Sections:
Idx Namne Size VMA LMA File off Algn
0 .text 00000072 08048094 08048094 00000094 2**2
CONTENTS,ALLOC,LOAD,RBLOC,READONLY,CODE
1 .data 00000004 08049108 08049108 00000108 2**2
CONTENTS,ALLOC,LOAD,DATA
...
VMA表示Virtual Memory Address,即虚拟地址,LMA表示Load Memory Address,即加载地址,正常情况下这两个值应该是一样的,但是在有些嵌入式系统中,特别是
在那些程序放在ROM的系统中时:LMA和VMA是不相同的。这里我们只要关注VMA即可。
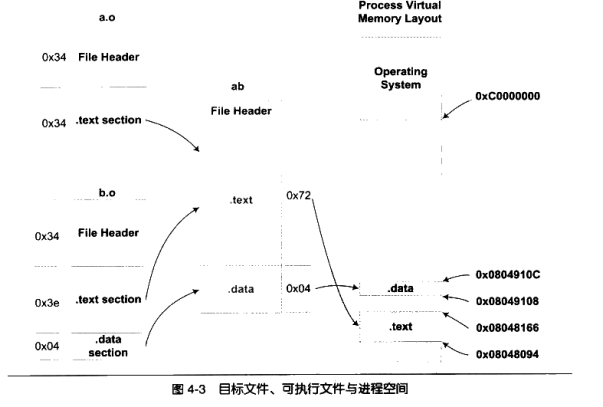
链接前后的程序中所使用的地址已经是程序在进程中的虚拟地址,即我们关心上面各个段中的VMA(Virtual Memory Address)和Size,而忽略文件偏移(File off)。我们可以看到,在链接之前,目标文件中的所有段的VMA都是0,因为虚拟空间还没有被分配,所以它们默认都为0。等到链接之后,可执行文件ab中的各个段都被分配到了相应的虚拟
地址。这里的输出程序“ab”中,“.text”段被分配到了地址0x08048094,大小为0x72字节;“.data”段从地址0x08049108开始,大小为4字节。整个链接过程前后,目标文件各段的分配、程序虚拟地址如图4-3所示。


1.3 符号地址的确定

2 符号解析与重定位
2.1 重定位
/*a.c*/
extern int shared;
int main(){
int a=100;
swap(&a,&shared);
}
/*b.c*/
int shared=1;
void swap( int* a, int*b){
*a ^= *b^= *a^=*b;
}
在完成空间和地址的分配步骤以后,链接器就进入了符号解析与重定位的步骤,这也是静态链接的核心内容。在分析符号解析和重定位之前,首先让我们来看看a.o里面是怎么使用这两个外部符号的,也就是说我们在a.c的源程序里面使用了shared变量和swap函数,那么编译器在将a.c编译成指令时,它如何访问shared变量?如何调用swap函数?
使用objdump的-d参数可以看到a.o的代码段反汇编结果:
$objdump -d a.o
a.o: file format elf32-i386
Disassembly of section .text:
00000000 <main>:
0: 8d 4c 24 04 lea 0x4(%esp), %ecx
4: 83 e4 f0 and $0xfffffffo, %esp
7: ff 71 fc pushl 0xfffffffc(%ecx)
a: 55 push %ebp
b: 89 e5 mov %esp,%ebp
d: 51 push %ecx
e: 83 ec 24 sub $0x24, %esp
11: c7 45 f8 64 00 00 00 movl $0x64,0xfffffff8(%ebp)
18: c7 44 24 04 00 00 00 movl $0x0,0x4(%esp)
1f: 00
20: 8d 45 f8 lea 0xfffffff8(%ebp), %eax
23: 89 04 24 mov %eax, (%esp)
26: e8 fc ff ff call 27 <main+0x27>
2b: 83 c4 24 add $0x24,%esp
2e: 59 pop %ecx
2f: 5d pop %ebp
30: 8d 61 fc lea 0xfffffffc(%ecx), %esp
33: c3 ret
我们知道在程序的代码里面使用的都是虚拟地址,在这里也可以看到“main”的起始地址为0x00000000,这是因为在未进行前面提到过的空间分配之前,目标文件代码段中的起始地址以0x00000000开始,等到空间分配完成以后,各个函数才会确定自己在虚拟地址空间中的位置。
我们可以很清楚地看到“a.o”的反汇编结果中,“a.o”共定义了一个函数main。这个函数占用0x33个字节,共17条指令;最左边那列是每条指令的偏移量,每一行代表一条指令(有些指令的长度很长,如第偏移为0x18的mov指令,它的二进制显示占据了两行)。shared的地址为四个00:
18: c7 44 24 04 00 00 00 movl $0x0,0x4(%esp)
1f: 00
swap的位置为fc ff ff:
26: e8 fc ff ff call 27 <main+0x27>
对于shared的引用是一条mov指令,这条指令总共8个字节,它的作用是将shared的地址赋值到ESP寄存器+4的偏移地址中去,前面4个字节是指令码,后面4个字节是shared的地址,我们只关心后面的4个字节部分,如图4-4所示。
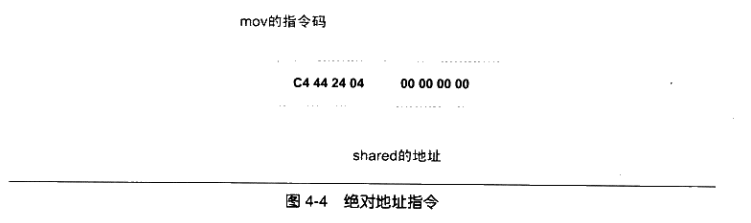
当源代码a.c在被编译成目标文件时,编译器并不知道shared和swap的地址因为它们定义在其他目标文件中。所以编译器就暂时把地址0看作是shared的地址,我们可以看到这条mov指令中,关于shared的地址部分为0x00000000.
另外一个是偏移为0x26的指令的一条调用指令,它其实就表示对swap函数的调用,如图4-5所示。
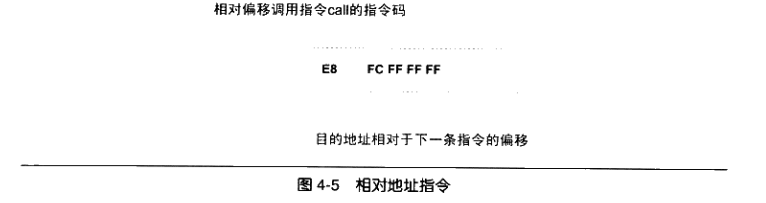
这条指令共5个字节,前面的0xE8是操作码(OperationCode),从Intel的IA-32体系软件开发者手册(IA-32 Intel Architecture Software Developer’s Manual)可以查阅到,这条指令是一条近址相对位移调用指令(Call near, relative, displacement relative to next instruction), 后面4个字节就是被调用函数的相对于调用指令的下一条指
令的偏移量。在没有重定位之前,相对偏移被置0xFFFFFFFC(小端),它是常量-4的补码形式。
26: e8 fc ff ff call 27 <main+0x27>
2b: 83 c4 24 add $0x24,%esp
让我们来仔细看这条指令的含义。紧跟在这条call指令后面的那条指令为add指令,add指令的地址为0x2b,而相对于add指令偏移为-4的地址即0x2b-4=0x27。所以这条
call指令的实际调用地址为0x27。我们可以看到0x27存放着并不是swap函数的地址,跟前面shared一样,0xFFFFFFFC只是一个临时的假地址,因为在编译的时候,编译器并
不知道swap的真正地址。
编译器把这两条指令的地址部分暂时用地址0x00000000和0xFFFFFFFC代替着把真正的地址计算工作留给了链接器。我们通过前面的空间与地址分配可以得知,链接器在完成地址和空间分配之后就已经可以确定所有符号的虚拟地址了,那么链接器就可以根据符号的地址对每个需要重定位的指令进行地位修正。我们用objdump来反汇编输出程序ab的代码段,可以看到main函数的两个重定位入口都已经被修正到正确的位置:
$objdump -d ab
ab: file format e1f32-1386
Disassembly of section .text:
08048094 <main>:
8048094: 8d 4c 24 04 lea 0x4(%esp), %ecx
8048098: 83 e4 f0 and $0xfffffffo, %esp
804809b: ff 71 fc pushl 0xfffffffc(%ecx)
804809e: 55 push %ebp
804809f: 89 e5 mov %esp,%ebp
80480a1: 51 push %ecx
80480a2: 83 ec 24 sub $0x24, %esp
80480a5: c7 45 f8 64 00 00 00 movl $0x64,0xfffffff8(%ebp)
80480ac: c7 44 24 04 08 01 04 movl $0x0,0x4(%esp)
80480b3: 08
80480b4: 8d 45 f8 lea 0xfffffff8(%ebp), %eax
80480b7: 89 04 24 mov %eax, (%esp)
80480ba: e8 09 00 00 00 call 27 <main+0x27>
804805f: 83 c4 24 add $0x24,%esp
80480C2: 59 pop %ecx
80480c3: 5d pop %ebp
80480C4: 8d 61 fc lea 0xfffffffc(%ecx), %esp
80480c7: c3 ret
080480C8 <swap>:
8048008: 55 push %ebp
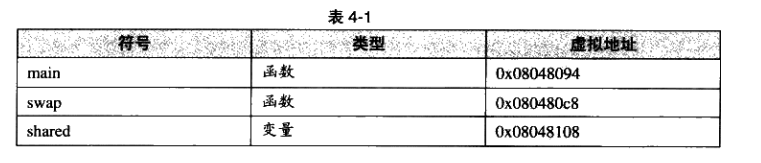
经过修正以后,shared和swap的地址分别为0x08049108和0x00000009(小端字节序)。关于shared很好理解,因为shared变量的地址的确是0x08049108。对于swap来说稍显嗨涩。我们前面介绍过,这个call指令是一条近址相对位移调用指令,它后面跟的是调用指令的下一条指令的偏移量,call指令的下条指令是add,它的地址是0x080480bf,所以“相对于add指令偏移量为0x00000009的地址为0x080480bf+9=0x080480c8,即刚好是swap函数的地址。有兴趣的读者可以阅读后面的“指令修正方式”一节,那里我们将更加详细介绍指令修正时的地址计算方式。
2.2 重定位表






2.3 符号解析

















 2211
2211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









