







Titanic项目
Use machine learning to create a model that predicts which passengers survived the Titanic shipwreck.
基于机器学习建立模型预测泰坦尼克号灾难中哪些乘客得以生存。
p.s.本次练习主要在于熟悉数据分析项目流程、思考方式与实际操作,并未以达到最高准确率为目标
Kaggle入门项目:Titanic overview
参考分析视频:Beginner Kaggle Data Science Project Walk-Through (Titanic)
参考分析笔记:Titanic Project Example Walk Through
关于数据
数据概括
训练数据(training set):
含有关于乘客生存信息的数据,用来建立机器学习模型。建立模型模型时应基于训练数据中关于乘客年龄、客舱等级、亲属数等的属性(详情见数据字段描述)

测试数据(test set):
将模型运用于测试数据中并预测乘客生存与否,将根据上传的测试数据预测结果评判模型准确度
测试数据比训练数据只少了survived一列(需根据模型自行预测)

数据字段描述

官方教程代码
from sklearn.ensemble import RandomForestClassifier
y = train_data["Survived"]
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
predictions = model.predict(X_test)
output = pd.DataFrame({
'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('my_submission.csv', index=False)
print("Your submission was successfully saved!")
按照上述代码运用随机森林得到的结果为0.77511
数据分析
总体思路
- 1.了解数据基本信息,使用 .info() .describe()
- 2.画图展现数据分布便于数据分析、特征分析 e.g.Histograms, boxplots
- 3.分析不同属性的值
- 4.分析不同属性之间的关联性
- 5.思考分析的主题,提出思考的问题
(例如对本次Titanic数据:生存与否与乘客性别有关?与乘客本人经济条件有关?与年龄有关?哪个港口登船的乘客更容易生存?) - 6.特征工程
- 7.处理缺失数据
- 8.整合训练数据和测试数据?
- 8.进行特征缩放 scaling?
- 9.建立模型
- 10.利用交叉验证 CV 对比模型效果
初步分析
import numpy as np
import pandas as pd
train_data = pd.read_csv('/kaggle/input/titanic/train.csv')
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
#查看训练数据相关信息
train_data.info()
训练数据信息如下:
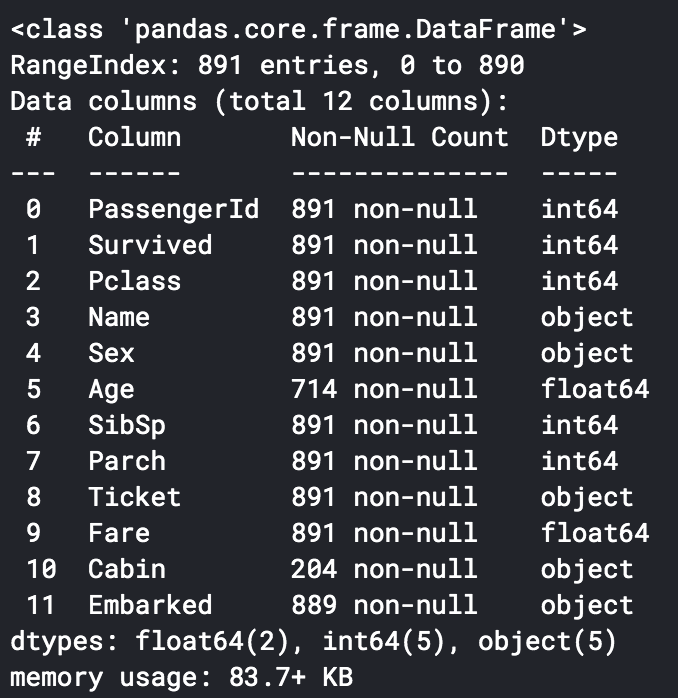
可以看出Age字段与Cabin字段有较多缺失数据,Embarked字段有2条缺失数据
#进一步查看数据的统计信息
train_data.describe()
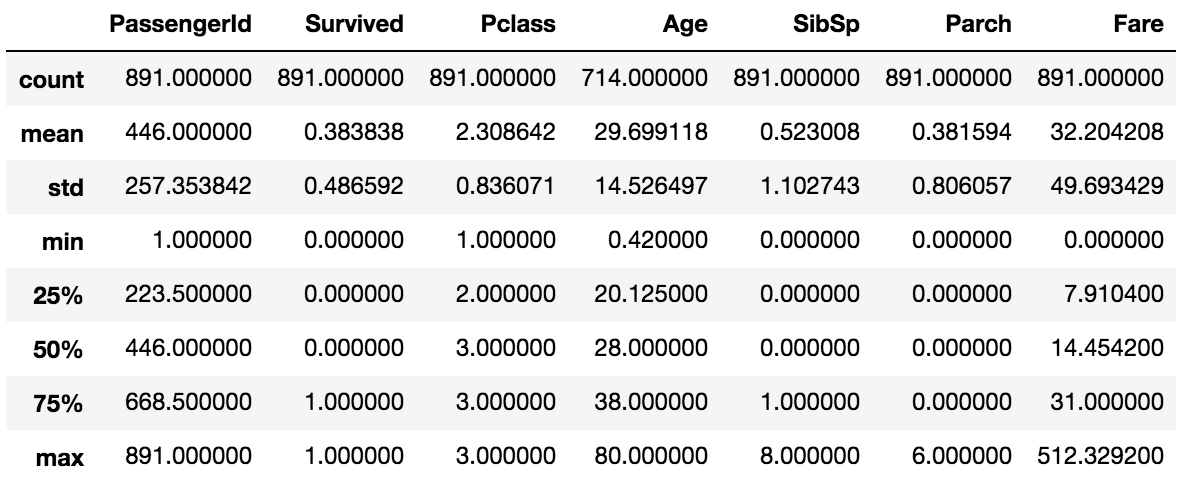
数值型数据
针对数值型数据 (numeric data):
- 通过画矩形图了解数据分布情况(histogram)
- 画图探索不同数据的相关性
- 运用透视表比较生存率与不同变量之间的关系(pivot table)
import matplotlib.pyplot as plt
#提取数值型属性
df_num = train_data[['Age','SibSp','Parch','Fare']]
#画矩形图
for i in df_num.columns:
plt.hist(df_num[i])
plt.title(i)
plt.show()
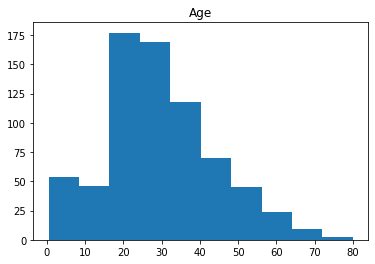
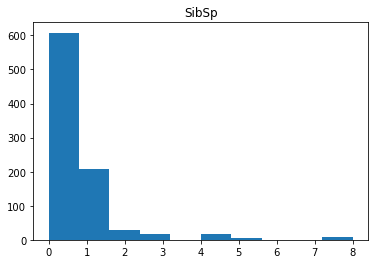
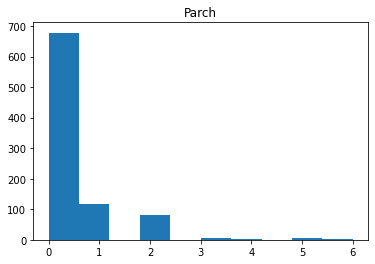
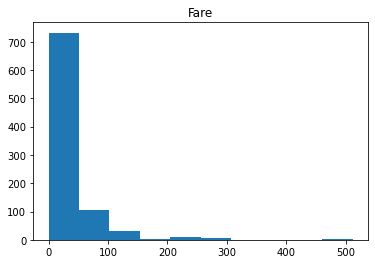
Age接近正态分布,其他三个属性无特殊分布。Fare属性值的分布较广,考虑在后期进行数据标准化(normalization)处理。
import seaborn as sns
# 画图探索不同数据的相关性
print(df_num.corr()) #相关系数
sns.heatmap(df_num.corr()) #使用热图查看相关系数分布情况
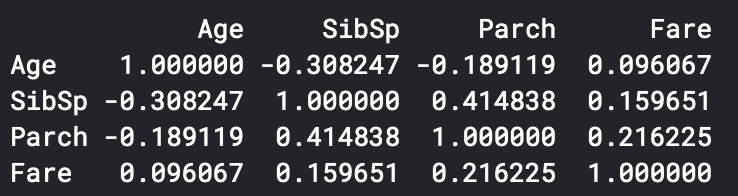

可以看出SibSp与Parch有一定的相关性,即家庭成员一起出游的可能性较大
(属性相关性分析在回归分析中很重要,因为要避免因为不同属性有较强相关性从而对模型造成影响)
# 用透视图观察存活率与同变量之间的关系
pd.pivot_table(train_data, index = 'Survived', values = ['Age','SibSp','Parch','Fare'])
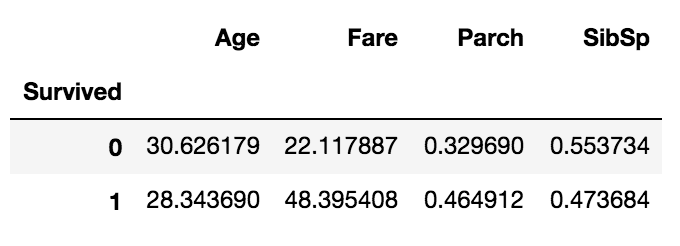
对于Age属性,可以推测也许年轻的人有更大的概率生存
对于Fare属性,可以推测也许付钱更多的人有更大的概率生存
对于Parch属性,可以推测也许有父母小孩一同登船的人有更大概率生存
对于SibSp属性,可以推测也许有兄弟姐妹或配偶登船的人生存几率更小
补充:
关于pd.pivot_table 函数:pd.pivot_table(df,index=[“A”,“B”], values=[“C”])
按照index内的变量进行分组,再利用values定义关心的域,透视表默认计算列内数据的平均值
也可以通过(aggfunc= )函数列元素进行计数或求和:
pd.pivot_table(df,index=[“A”,“B”], values=[“C”], aggfunc=np.sum)
属性型数据
针对属性型数据( Categorical Data):
- 观察不同属性的分布情况(bar charts)
- 运用透视表比较生存率与不同变量之间的关系(pivot table)
df_cat = training[['Survived','Pclass','Sex','Ticket','Cabin','Embarked']]
#可以通过柱状图判断不同属性值的分布情况
for i in df_cat.columns:
sns.barplot(df_cat[i].value_counts().index,df_cat[i].value_counts()).set_title(i)
plt.show()
属性分布情况如下:
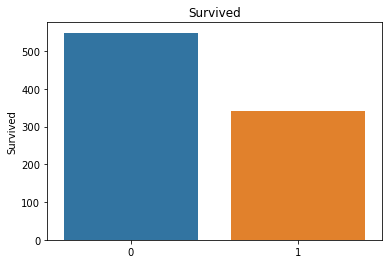
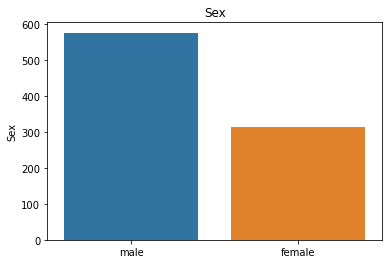
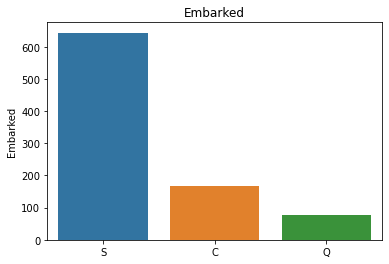
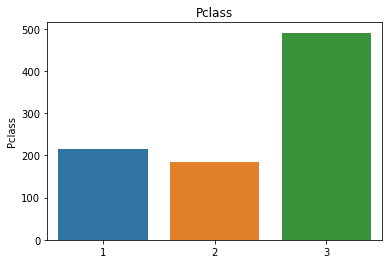
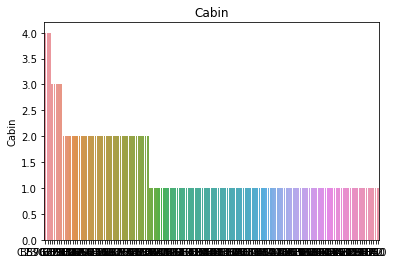
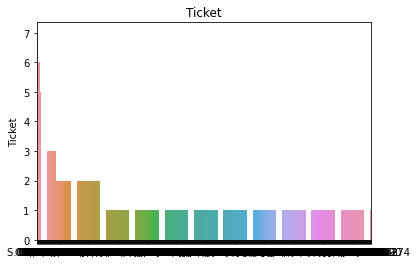
# 用透视图分析三个属性与是否生存之间的关系,此处使用了 aggfunc ='count' 方法
print(pd.pivot_table(train_data, index = 'Survived', columns = 'Pclass', values = 'Ticket' ,aggfunc ='count'))
print()
print(pd.pivot_table(train_data, index = 'Survived', columns = 'Sex', values = 'Ticket' ,aggfunc ='count'))
print()
print(pd.pivot_table(train_data, index = 'Survived', columns = 'Embarked', values = 'Ticket' ,aggfunc ='count'))
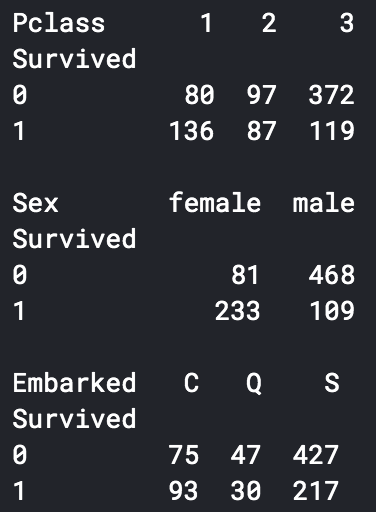
可以看出一等舱的乘客生存概率更大,女性生存概率更大,在S处登船的乘客生存概率更大
特征工程
1.对于Cabin属性:可以分析Cabin属性内值的个数(购票数)、Cabin属性的字母值(舱位号)与生存率之间是否有关联
df_cat.Cabin
#分析Cabin内值的个数,0代表Cabin属性为空,1代表有1个值,2代表有2个值
train_data['cabin_multiple'] = train_data.Cabin.apply(lambda x: 0 if pd.isna(x) else len(x.split(' ')))
train_data['cabin_multiple'].value_counts()
结果如下:
0 687
1 180
2 16
3 6
4 2
#运用透视表分析Cabin值的个数与存活率的关系
pd.pivot_table(train_data, index = 'Survived', columns = 'cabin_multiple', values = 'Ticket' ,aggfunc ='count')
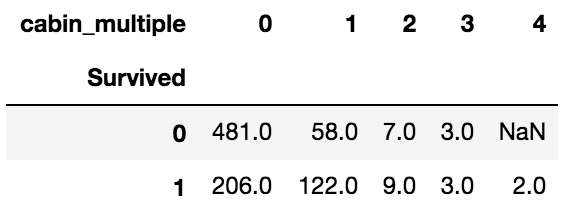
#增加cabin_adv属性表示Cabin字母值
train_data['cabin_adv'] = train_data.Cabin.apply(lambda x: str(x)[0])
print(train_data.cabin_adv.value_counts())
结果如下:其中n代表值为null,此处将缺失值(null)作为一类进行进行分析
n 687
C 59
B 47
D 33
E 32
A 15
F 13
G 4
T 1
#利用透视表分析Cabin字母值与存活率的关系
pd.pivot_table(train_data,index='Survived',columns='cabin_adv', values = 'Name', aggfunc='count')
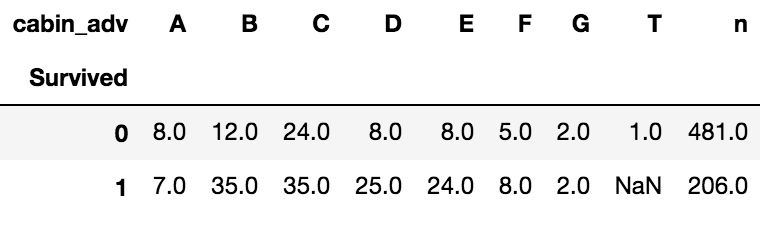
可以看出没有Cabin值的多数乘客未能生存,有特定Cabin值的乘客存活率更高
2.对于Ticket属性:分为单纯数字的票号和非数字(含字母)的票号:
#纯数字的票号numeric_ticket=1
train_data['numeric_ticket'] = train_data.Ticket.apply(lambda x: 1 if x.isnumeric() else 0)
train_data['numeric_ticket'].value_counts()
结果如下:
1 661
0 230
3.对于Ticket属性:分为单纯数字的票号和非数字(含字母)的票号:
模型准备
1.选取保留的属性(去除姓名、乘客编号),更改进行特征工程时分析的属性,保留属性:‘Pclass’, ‘Sex’,‘Age’, ‘SibSp’, ‘Parch’, ‘Fare’, ‘Embarked’, ‘cabin_adv’, ‘c
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









