







简介
本文从原理上介绍了三种梯度下降的方法,相同点,异同点,优缺点。
内容包含了数学公式的推导与说明
1. 梯度下降的3种方法
梯度下降分三类,原理基本相同,操作方式略有区别
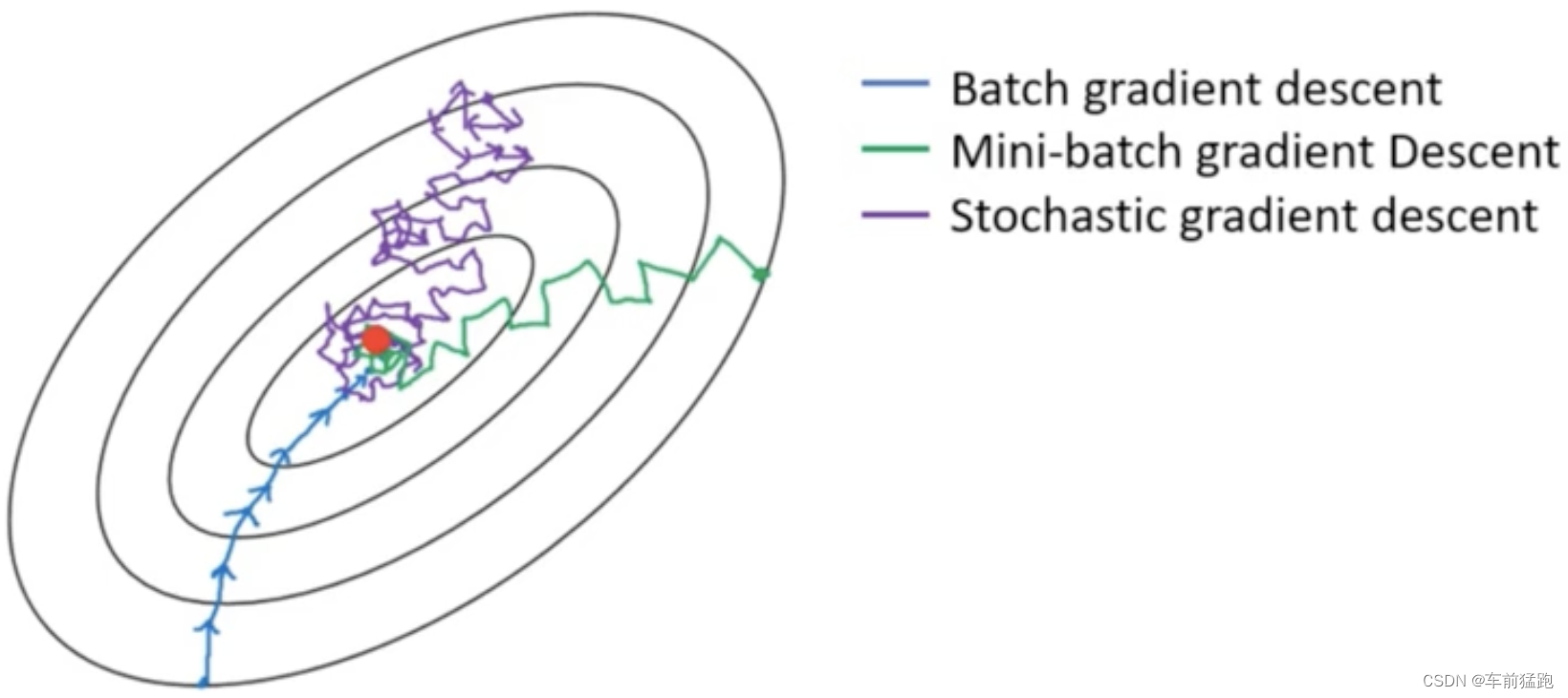
- 批量梯度下降BGD(BatchGradient Descent):使用全量数据进行特征抽取,模型训练
- 小批量梯度下降MBGD(Mini-Batch Gradient Descent):从全量数据中随机抽取部分数据进行特征抽取,模型训练
- 随机梯度下降SGD(Stochastic Gradient Descent):从全量样本数据中随机抽取1个样本进行模型训练
1.1 梯度下降的操作步骤分为以下4步
- 随机赋值,Random随机数生成 θ \theta θ,随机一组数值 w 0 、 w 1 . . . w n w_0、w_1...w_n w0、w1...wn
- 求梯度g(默认认为数据符合正态分布,g对应最小二乘法公式),梯度代表曲线某点上的切线的斜率,沿着切线往下就相当于沿着坡度最陡峭的方向下降
if(g) < 0: θ \theta θ变大,if(g>0): θ \theta θ变小- (x = x - eta * g(x))
- 判断是否收敛convergence,如果收敛跳出迭代,如果没有达到收敛,回第2步再次执行2~4步。
- 收敛的判断标准是:随着迭代进行损失函数Loss,变化非常微小甚至不再改变,即认为达到收敛
1.2 三种梯度下降不同,体现在第二步中:
- BGD是指在每次迭代使用所有样本来进行梯度的更新
- MBGD是指在每次迭代使用一部分样本(所有样本1000个,使用其中100个样本)来进行梯度的更新
- SGD是指每次迭代随机选择一个样本来进行梯度更新
2. 线性回归梯度更新公式
复习一下:最小二乘法公式:
J ( θ ) = 1 2 ∑ i = 1 n ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta) = \frac12 \sum\limits_{i=1}^{n}(h_{\theta}(x^{(i)}) - y^{(i)})^2 J(θ)=21i=1∑n(hθ(x(i))−y(i))2
矩阵写法:
J ( θ ) = 1 2 ( X ⋅ θ − y ) T ( X ⋅ θ − y ) J_(\theta) = \frac12(X\cdot\theta-y)^T(X\cdot\theta - y) J(θ)=21(X⋅θ−y)T(X⋅θ−y)
2.1 求解上面梯度下降的第2步,即推导出损失函数的导函数来。
θ j n + 1 = θ j n − η ∗ ∂ J ( θ ) ∂ θ j \theta_j^{n+1} = \theta_j^{n} - \eta * \frac{\partial {J(\theta})}{\partial \theta_j} θjn+1=θjn−η∗∂θj∂J(θ)
这是对第 j j j个系数的梯度更新公式,n+1,n表示次数(不是次幂)
∂ J θ ∂ θ j = ∂ ∂ θ j 1 2 ( h θ ( x ) − y ) 2 \frac{\partial{J\theta}}{\partial \theta_j} = \frac{\partial}{\partial {\theta_j}}{\frac12 (h_{\theta}(x) - y)^2} ∂θj∂Jθ=∂
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 578
578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









