







内容简介
- 通过构造一个一维的数据集,使用代码对其完成批量梯度下降计算(BGD)
- 再构造一个多维数据集,同样是用代码完成批量梯度下降计算
- 在此过程中,需要注意构造数据的形状,通过衰减衰减对算法优化等
前置内容请看
1. 梯度下降求解 一元数据(一个维度数据)
1.1 首先构造数据
import numpy as np
import matplotlib.pyplot as plt
# 随机生成100个值填充X,特征值
X = np.random.rand(100, 1)
# 随机生成 w系数(斜率,权重),b截距
w, b = np.random.randint(1, 10, size =2)
# 在截距上增加随机正太分布值,模拟真实数据
# 这里是对100个数据,在b上增加不同的随机值
y = w * X + (b + np.random.randn(100, 1))
# 打点观察数据
plt.scatter(X, y)
- X:100行1列的随机数
- w,b:随机生成的斜率(系数,权重)与截距
- np.random.randn(100, 1):100个随机正态分布数据,加到b上,形成数据的最终有浮动的截距,模拟真实数据。
模拟数据打点图如下:

1.2 截距要作为偏置项,与X中的元素统一处理
将b作为偏置项,截距对应的系数相当于1
X = np.concatenate([X, np.full(shape = (100,1), fill_value=1)], axis=1)
X[:10]
观察前X中10个数据,不光有随机生成的x(第一列),还增加了作为偏置项的b(第二列)
array([[0.65470457, 1. ],
[0.67191477, 1. ],
[0.44127458, 1. ],
[0.96462493, 1. ],
[0.48987496, 1. ],
[0.2383499 , 1. ],
[0.03313414, 1. ],
[0.52140433, 1. ],
[0.65856641, 1. ],
[0.99781758, 1. ]])
至此,数据准备完成
1.3 设置循环次数,学习率
# 循环次数
epoches = 100000
# 学习率,暂时设置成固定值,下面1.7会通过逆时衰减函数优化
eta = 0.01
1.4 随机初始化theta(要求解的系数/斜率/权重)
# 需要求解的系数,初始用随机数赋值,”瞎蒙“
theta = np.random.randn(2, 1)
1.5 开始循环
for i in range(epoches):
# 求出梯度
# BGD用全体样本数据计算,X是个矩阵
g = X.T.dot(X.dot(theta) - y)
theta = theta - eta * g
print('真实斜率,截距:', w, b)
print('梯度下降计算出的斜率,截距:', theta)
1.6 得到计算结果
真实斜率,截距: 9 5
梯度下降计算出的斜率,截距: [[9.34389628]
[4.77139965]]
可以看到,随机生成的w=9,b=5
当斜率加上随机正态分布的波动数据后,通过地图下降求解出的w=9.34389628,b=4.77139965,基本比较精确。
1.7 优化eta,逆时衰减
随着训练次数的增加,会越逼近最优解,那么学习率也应该随之逐渐减小。
这样能够避免出现左右跳跃震荡。
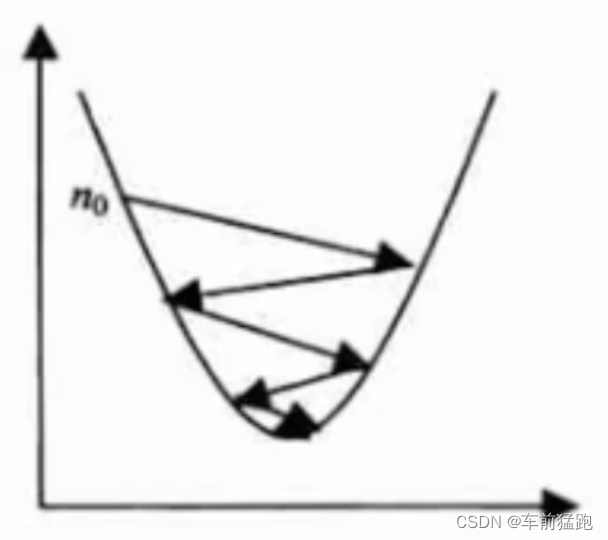
在代码中加入根据迭代次数增加而动态减小的逆时衰减函数
t0, t1 = 5, 1000
# 逆时衰减函数
def inverse_decay(times):
return t0/(times + t1)
1.8 完整代码如下:
import numpy as np
import matplotlib.pyplot as plt
# 随机生成100个值填充X,特征值
X = np.random.rand(100, 1)
# 随机生成 w系数(斜率,权重),b截距
w, b = np.random.randint(1, 10, size =2)
# 在截距上增加随机正太分布值,模拟真实数据
# 这里是对100个数据,在b上增加不同的随机值
y = w * X + (b + np.random.randn(100, 1))
# 打点观察数据
plt.scatter(X, y)
# 将b作为偏置项,截距对应的系数相当于1
X = np.concatenate([X, np.full(shape = (100,1), fill_value=1)], axis=1)
# 取前10个元素观察
X[:10]
# 循环次数
epoches = 100000
# 学习率
#eta = 0.01
t0, t1 = 5, 1000
# 逆时衰减函数
def inverse_decay(times):
return t0/(times + t1)
# 需要求解的系数(1个x的w,1个b),初始用随机数赋值,”瞎蒙“
theta = np.random.randn(2, 1)
for i in range(epoches):
# 求出梯度
# BGD用全体样本数据计算,X是个矩阵
g = X.T.dot(X.dot(theta) - y)
eta = inverse_decay(i)
theta = theta - eta * g
print('真实斜率,截距:', w, b)
print('梯度下降计算出的斜率,截距:', theta)
2. 求解 多元数据(多个维度数据)
实际生产活动中,更多情况下是要对多个维度数据进行求解。比如:影响身高的因素会有多个。下面例子中模拟8个维度的数据。
2.1 构造数据
import numpy as np
import matplotlib.pyplot as plt
# 与1元的区别:生成100行,8列数据
X = np.random.rand(100, 8)
# 随机生成 w系数(斜率,权重),b截距
# 与1元的区别:生成8个w斜率,形状:8行1列,为了下面与X的100行8列进行矩阵点乘运算
w = np.random.randint(1, 10, size =(8, 1))
# 截距还是一个
b = np.random.randint(1, 10, size =1)
# 在截距上增加随机正太分布值,模拟真实数据
# 与1元的区别:w*x改成矩阵点乘:w.dot(X),
y = X.dot(w) + (b + np.random.randn(100, 1))
# 打点观察数据,打不了,8维数据不好展示
# plt.scatter(X, y)
# 将b作为偏置项,截距对应的系数相当于1
X = np.concatenate([X, np.full(shape = (100,1), fill_value=1)], axis=1)
数据构造完毕,下面进行计算的代码,基本与1元部分一样
但是要注意的是,8元数据+1个截距 = 9个维度,那么下面计算代码中的theta的形状,需要将(2,1)改成(9,1)
2.2 通过10000次梯度下降计算8元数据的8个斜率与1个截距
# 循环次数
epoches = 100000
# 学习率
#eta = 0.01
t0, t1 = 5, 1000
# 逆时衰减函数
def inverse_decay(times):
return t0/(times + t1)
# 与1元的区别:需要求解的系数(8个x的w,1个b),初始用随机数赋值,”瞎蒙“
theta = np.random.randn(9, 1)
for i in range(epoches):
# 求出梯度
# BGD用全体样本数据计算,X是个矩阵
g = X.T.dot(X.dot(theta) - y)
eta = inverse_decay(i)
theta = theta - eta * g
print('真实斜率,截距:', w, b)
print('梯度下降计算出的斜率,截距:', theta)
2.3 运行结果如下:
真实斜率,截距: [[8]
[1]
[1]
[4]
[1]
[7]
[5]
[6]] [5]
梯度下降计算出的斜率,截距: [[7.81126992]
[0.59311965]
[1.4014495 ]
[4.2119818 ]
[0.63484884]
[6.8117345 ]
[5.12227223]
[5.91108641]
[5.42760976]]
前8个数据是w,第9个是b
















 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









