







原文链接:https://blog.csdn.net/ACL_lihan/article/details/104020259
补充:
问题:为什么奖励R是正数,概率pθ就会变大?
理解1:
如果采取action得到正奖励,那就需要提高在s下采取a的概率p(a,s),才会让总的R变大,反之如果采取action得到负奖励,那就需要减少在s下采取a的概率p(a,s),才会让总的R变大
理解2:
借用分类中交叉熵损失函数,loss = argmin -ylg y’ = argmax ylg y’
类比上面损失函数,若R大于0,要argmax的话,则概率p(a,s)也要越大,
反之,若R大于0,要argmax的话,则概率p(a,s)也要越小
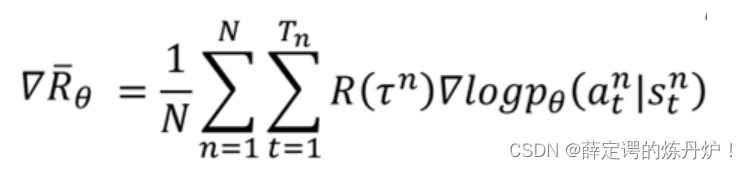
【李宏毅深度强化学习笔记】1、策略梯度方法(Policy Gradient)(本文)
【李宏毅深度强化学习笔记】2、Proximal Policy Optimization (PPO) 算法
【李宏毅深度强化学习笔记】3、Q-learning(Basic Idea)
【李宏毅深度强化学习笔记】4、Q-learning更高阶的算法
【李宏毅深度强化学习笔记】5、Q-learning用于连续动作 (NAF算法)
【李宏毅深度强化学习笔记】6、Actor-Critic、A2C、A3C、Pathwise Derivative Policy Gradient
【李宏毅深度强化学习笔记】8、Imitation Learning
-------------------------------------------------------------------------------------------------------
【李宏毅深度强化学习】视频地址:https://www.bilibili.com/video/av63546968?p=1
课件地址:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS18.html
-------------------------------------------------------------------------------------------------------
回顾
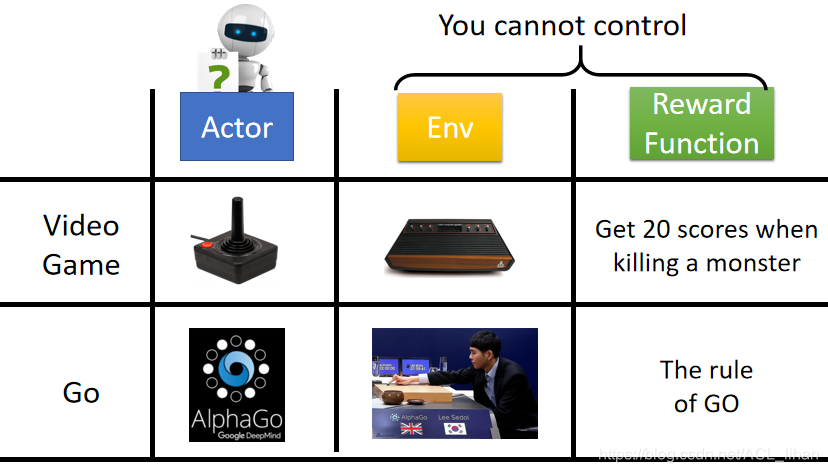
在强化学习中,主要有三个部件(components):actor、environment、reward function。其中env和reward function是事先就定好的,你不能控制的。唯一能调整的是actor的policy,使actor能获得最大的reward。

policy是actor中起决策作用的一个东西,决定了actor的行为。就是说输入什么状态(state)要输出什么动作(action)。
这里以来代表policy。在深度强化学习中,policy是通常使用network来实现,network中会包含很多参数,这里就用
来统一代表这些参数。
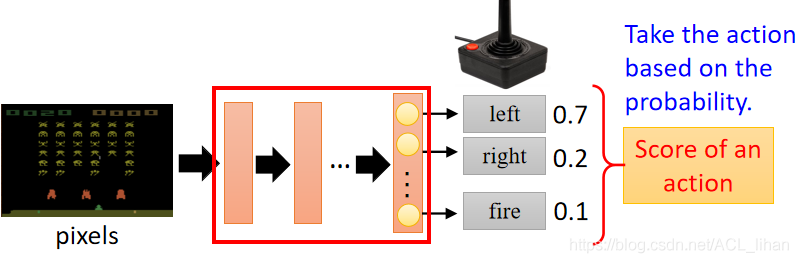
这里以游戏画面作为输入,经过红框的网络(policy)决策后,得出采取各种动作的几率,所以最终得出做left这个动作。
(类似于图像分类,看到什么图像,分成哪几类。只是这里的类别是要做出的动作)
一个例子:

初始的游戏画面作为 ,针对
采取的动作为
,行动后会得到一个reward记为
。之后会看到下一个游戏画面
...

经过很多轮 后游戏结束了,从开始到结束玩的这一次游戏称为一个episode,将每一个episode的 reward 相加就能得到Total reward:
。actor 的目标就是将 Total reward R 最大化。

把每一个episode的所有s和a的序列,叫做Trajectory
在给定policy的参数 的情况下,可以计算每一个
存在的概率
。
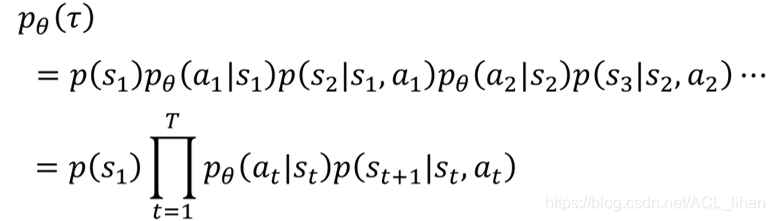
其中 代表的是environment,一般我们没办法控制这一部分。我们能控制的是采取不同的
(policy网络的参数),进而影响
,最终对
产生影响。

给定一个 可以得到一局游戏的 R,我们要做的就是调整actor中的参数,使得
最大化。但是注意
不是常量 scalable,而是随机变量 random variable,因为采取哪个action是有随机性的,而环境给出哪个state也是有随机性的。
所以对于 R 我们要算它的期望 。穷举所有的trajectory
并计算每个
出现的概率,最后算
。或者这样理解:从
的分布中采样(sample)出一个
,然后计算
的期望。
那很明显我们要做的就是最大化Expected Reward,所以可以采用policy gradient来做。
Policy Gradient:

为了使 最大化,我们需要做gradient ascent(注意不是gradient descent!),即对
求梯度。注意
中
是不可微的,但不影响。
是无法计算的,所以sample出N个
,对每个
求
再求和取平均。
上面提到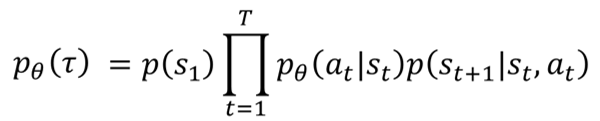 ,而
,而 由环境决定,我们无法知道,而且这一项本来也和
没关系,只能对
计算梯度,本质上就是对
计算梯度。
所以最后 改写为
。
最后的 :若在
下执行
使得
为正,则增加概率
;为负则减少概率。

在实际实验中,我们会让actor去和environment做互动,产生左边的数据。左边的方框是做sample,获得很多 (s, a) 的pair(代表在s下采取a,得到 )。然后将这些数据送入训练过程中计算
。然后更新模型的参数
。
注意数据只用一次,就是说更新一次参数后前面收集的所有数据就不能再用了,效率比较低。因为policy gradient ascend是on-policy的算法,具体说明可以看我的另一篇文章,前半段有讲on-policy和off-policy(https://blog.csdn.net/ACL_lihan/article/details/103989581)。
以下是policy gradient的两个小技巧:
技巧1:add a baseline
蓝色柱子的代表在某一state下,采取三种动作的概率,绿色箭头则代表每种动作的Reward,长的标示Reward比较大。
之前约定的做法:假如执行 action a 后 R 为正,则提高 action a 出现的概率;R 为负,则降低 action a 出现的概率。
但是可能某个游戏不管什么执行动作得到的 reward 都是正的(比如0-20),则若执行 action a 后 R 的增加量大,则 action a 出现概率增加得大;执行 action b 后R的增加量小,则 action b 出现概率增加得小。(注意在reward恒为正的情况下,看起来无论如何执行某 action 的概率都会增加,只是增加多少的问题) 因为所有action出现的概率和为1,那么在理想情况下,在归一化后相当于 action a 出现概率上升而 action b 出现概率下降。(即增加得少的归一化后相当于下降,增加得多的归一化后才上升)
问题是在sample中可能有些动作没有sample到,比如 action a(我们不知道这个action得到的reward是大是小),但归一化后 action a 出现的概率会必然下降(因为 action b/c 出现的概率无论如何都会上升,这样就把 action a 出现的概率给压下去了),这显然是不妥的。

为了解决这个问题,我们希望reward不要总是正的,将所以 ,b是一个baseline,这样如果一个 reward 是一个很小的正值,减掉b后就会变负。
可以用
的平均值代替。

技巧2:assign suitable credit

由上图可知,在同一场游戏中,不管其中的某个 action 是好是坏,总会乘上相同的权重 R,这显然也是不公平的。
比如上图左边部分,整场游戏的 reward 是+3,按规定其中三个 都要被乘上 3 的权重,但是
未必见得好,因为执行
后的即时得分是 -2。如果我们sample的次数够多,可能会看出
不够好,这个问题能够得到解决。但是实际中可能没办法搜集足够多的数据,所以在sample次数不够多的情况下,我们希望每个action的权重不同。

解决的方法是,不把整场游戏的 R(+5+0+-2=+3)作为统一权重,而将执行该动作后剩下序列的【reward之和】作为该动作的权重。比如对于 ,它的权重应该为(+0-2=-2)。即执行某个 action 前得到多少 reward 都跟该 action 无关,该 action 只影响之后的游戏过程。
所以把权重中的 换成
,其中 t 代表该 action 执行的时刻,
代表游戏结束的时刻,即把当前的 r 以及之后每一步的 r 做一个求和。

还需要考虑的一点是,当前的 action 对之后游戏的影响会随之时间推移而减弱,所以我们要有 discount,在求和的每一步都乘上一个小于1的 (比如0.9),这样 action 之后的动作越多,即时分数乘上的
越多,越往后得到reward就会打上更大的折扣。
把 这一项称作Advantage Function
![]() ,也叫优势函数。它表示在actor在
,也叫优势函数。它表示在actor在下采取
,相较于其它action(同样对于
)有多好。
上标 代表 采用参数为
的policy 的 actor 。
最后总结:
1、介绍了actor、environment、reward function
2、在深度强化学习中,policy可以看成是参数为的网络,输入state,输出采取各种action的概率
3、一轮游戏叫做episode
4、trajectory={s1,a1,s2,a2,……},在给定policy的参数 的情况下,可以计算每一个
存在的概率
。
5、总的expected reward=
6、使用policy gradient ascend求 expected reward的最大值

![]()
7、采集一次数据,更新一次参数后,要重新采集一次数据。














 806
806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









