






前言
本文实现的RAG极其简易,仅用于本人研究,可能无法满足实际应用。代码较为透明,便于对过程、结果进行后续处理,感兴趣者可以参考。
一、模型加载
本文使用的计算卡为寒武纪MLU370-X8,大模型调用可参考小军军军军军军(小军军军军军军-CSDN博客)发布的系列文章。在此以Qwen1.5-7B-chat为例,加载过程如下:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import torch_mlu
import pandas as pd
import numpy as np
import os
import matplotlib.pyplot as plt
device = "mlu"
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen1.5-7B-Chat",#根据自己所使用的大模型及路径填写
torch_dtype=torch.float16,
device_map="balanced_low_0"
).eval()
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-7B-Chat")完成model和tokenizer加载后,通过下列代码实现基础大模型输出功能:
def resp(input):
messages = [
{"role": "system", "content": "YOUR SYSTEM PROMPT"},
{"role": "user", "content": input}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response二、数据准备
本人研究过程中使用的外挂数据为简单的列表形式,列表中的一项为一条数据,例如:
texts = [
' Increased economic policy uncertainty can lead to reduced investment, which may decrease PM2.5 pollution.',
' Higher economic policy uncertainty can hinder corporate innovation, potentially increasing PM2.5 pollution.',
' The overall impact of economic policy uncertainty on PM2.5 pollution is determined by the combined effect of these two channels.',
' Empirical evidence suggests that as economic policy uncertainty increases, PM2.5 pollution levels have significantly decreased.',
]如需读取文件,可使用pandas、numpy等读取本地文件,并转化为列表格式。
三、知识库embedding
根据喜好从Huggingface上下载embedding模型,并加载。本文以BAAI/bge-large-en-v1.5为例进行演示:
embedding = HuggingFaceEmbeddings(model_name="BAAI/bge-large-en-v1.5")
embeddings_texts = embedding.embed_documents(texts)
embeddings_texts = np.array(embeddings_texts).astype("float32")词嵌入后,数据准备中的列表将转化为array格式如下:
其中array中的每项对应一条数据,embedding后,array形状为(样本量,embedding维度),以本文案例为例,查询array形状为:
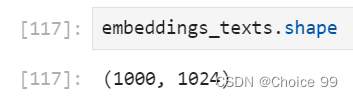
即embedding后,每条数据被转化为1024维词向量。
四、计算查询内容余弦相似度
定义余弦相似度计算函数,功能为输入两个文本向量,返回两向量间的余弦相似度:
def cosine_similarity(vec1, vec2):
dot_product = np.dot(vec1, vec2.T)
norm_vec1 = np.linalg.norm(vec1)
norm_vec2 = np.linalg.norm(vec2)
return dot_product / (norm_vec1 * norm_vec2)计算效果如下:

可以看出,“This is an example.”和“This is an example, too.”句意相似,返回向量间余弦相似度为0.93,而“This is an example.”和“I like doing research!”句意差别较大,余弦相似度仅有0.49。
五、RAG基础功能实现
实现RAG基础功能步骤大体为:
- 计算query与数据库中所有数据之间的余弦相似度
- 选择top k个数据库中的数据,作为大模型的提示
- 输入内容,结合先前提示,得到大模型输出
其中步骤1代码为:
def get_query_similarity(query,embeddings_texts):
query1 = [query]
embeddings_query = embedding.embed_documents(query1)
embeddings_query = np.array(embeddings_query).astype("float32")
sims = []
for each in embeddings_texts:
similarity = cosine_similarity(each, embeddings_query[0])
sims.append(similarity)
return sims步骤2代码为:
def get_query_res(query,embeddings_texts,topk,orig_texts):
similarities = get_query_similarity(query,embeddings_texts)
idx = find_positions_of_max_k(similarities,topk)
return_res = []
for each in idx:
return_res.append(orig_texts[each])#仅输出匹配的文本
#return_res.append([orig_texts[each],similarities[each]])#输出匹配的文本及余弦相似度
return return_res其中find_positions_of_max_k功能为从列表中找出排名前k的值,并返回其位置,具体代码为:
def find_positions_of_max_k(numbers,topk):
nums_array = np.array(numbers)
indices = np.argsort(nums_array)
max_indices = indices[-topk:]
max_indices = max_indices[::-1]
return max_indices步骤三代码为:
def RAG_Response(query,topk,embeddings_texts,orig_texts):
query_res = get_query_res(query=query,embeddings_texts = embeddings_texts,topk = 10,orig_texts=answer)
query_res_concat = ""
for each in query_res:
query_res_concat = query_res_concat+"\n"+each
INPUT = f'''Please answer the questions strictly based on the references I gave you after ### #, not on your own knowledge. Note that the references I give you may contain content unrelated to the question. Please answer strictly according to my questions, filtering and eliminating irrelevant references.
references:### \n {query_res_concat}
question:{query}
'''
res = resp(INPUT)
return res,query_resRAG_Response函数可根据输入的query查询知识库中相应的文本,并将文本放入INPUT中作为大模型输入的一部分,返回大模型的回答以及参考的知识库中相应文本。代码中,embeddings_texts为使用embedding模型嵌入后的词向量数据,orig_texts为原始数据。
直接获取大模型回答,可使用如下代码:
response,references = RAG_Response(query=query,topk=10,embeddings_texts=embeddings_question,orig_texts=answer)
print(f"Output:{response}\n references:{references}")结果如下:

实现对话功能则将上述代码放置于While True循环中即可。















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









