







论文链接: VirtualPainting: Addressing Sparsity with Virtual Points and Distance-Aware Data Augmentation for 3D Object Detection
代码链接: 暂时为空
作者: Sudip Dhakal,Dominic Carrillo,Deyuan Qu,Michael Nutt,Qing Yang,Song Fu
第一单位: University of North Texas Denton
一、研究背景
多模态传感器融合网络设计的核心挑战在于将激光雷达鸟瞰图与摄像机视图相整合。 主流的方法可以分为5类:
以对象为中心的融合、连续特征融合、BEV变换(显式LSS/隐式BEVFormer)、detection seeding和PointPainting。
(1)以对象为中心的融合: 模态具有不同的主干,每个视图中都有一个主干,并且通过在每个模态中从一组共享的 3D 提案中应用ROI池化,在对象提案级别进行融合。这允许端到端优化,但往往缓慢且麻烦(MV3D)。
(2)连续特征融合: 允许在图像和激光雷达主干的所有步幅之间共享特征信息。这些方法可以与单状态检测设计一起使用,但需要先验地为每个样本计算从点云到图像的映射。这一系列方法的一个微妙但重要的缺点是“特征模糊”。发生这种情况是因为鸟瞰视图中的每个特征向量对应于图像视图中的多个像素,反之亦然。 ContFuse 提出了一种基于 kNN、双线性插值和学习 MLP 的复杂方法来解决这个问题,但核心问题仍然存在。
(3)BEV变换: 图像、激光雷达(显式LSS/隐式BEVFormer)转换为鸟瞰图表示形式(统一的特征空间)并融合。
(4)detection seeding: 先验地从图像中提取语义并用于在点云中进行seed(感兴趣区域)检测。 Frustrum PointNet 和 ConvNet 使用 2D 检测来限制视锥体内的搜索空间,而 IPOD 使用语义分割输出来seed(感兴趣区域) 3D 提议。这提高了精确度,但对召回率施加了上限。
(5)PointPainting: 采用了相机衍生的特征来装饰原始 LiDAR 点云,以提高对象检测性能。然而,还是难以解决 LiDAR 点云数据固有的稀疏性问题,这主要是因为稀疏分布对象的相机衍生特征丰富的点较少。(原来的PointPainting方法尽管补充了来自图像的语义,但是对于稀疏的点云仍然没有很好的处理办法)
 图中黄色圆圈表示图像投影中缺少点云,而红色边界框表示稀疏点云导致的后续检测失败。
图中黄色圆圈表示图像投影中缺少点云,而红色边界框表示稀疏点云导致的后续检测失败。
现有的解决方案:
为了处理LiDAR数据的稀疏性,一些方法采用了生成虚拟点的方法——通过在现有的LiDAR点周围引入「补充点」来增强稀疏点云。
但是作者认为还是有不足之处,即没有关注训练数据质量。
本文贡献:
(1)提出VirtualPainting,方法通用
(2)集成距离感知的数据增强(Distance Aware Data Augmentation, DADA)的技术
(3)KITTI 和nuScenes 显示3D和BEV检测基准有提升
二、整体框架
如图所示,整体框架包括五个不同的模块:
(1)一个2D语义分割模块,负责计算每个像素的分割分数
(2)一个基于图像的深补全网络“PENet”,生成LiDAR虚拟点云
(3)虚拟绘图过程,使用语义分割分数绘制虚拟和原始LiDAR点
(4)距离感知数据增强(DADA)组件,采用距离感知采样策略,主要从附近的密集对象中生成稀疏训练样本
(5)一个3D检测器,用于得到最终的检测结果。
 VirtualPainting网络架构图
VirtualPainting网络架构图
三、核心方法
3.1 基于图像的语义网络
由于相机拍摄的2D图像在纹理、形状和颜色信息方面非常丰富。这种丰富性为点云提供了宝贵的互补信息,从而提升了3D检测的效果。要利用这种协同作用,可以采用语义分割网络生成像素级的语义标签。作者使用了BiSeNet2分割模型,以多视图图像为输入,并为前景实例和背景提供每个像素的分类标签。(这一模块是非常灵活的,可以融合各种语义分割网络以生成语义标签)
 特别的是网络最后的Aggregation Layer实现了双向信息引导(left = left1 * torch.sigmoid(right1)right = left2 * torch.sigmoid(right2))
特别的是网络最后的Aggregation Layer实现了双向信息引导(left = left1 * torch.sigmoid(right1)right = left2 * torch.sigmoid(right2))
该网络主要由三个组成部分构成:
(1)Detail分支: 该分支的网络层数较少,但是特征图的尺寸比较大,因此适用于提取空间细节信息。
(2)Semantic分支: 该分支相对比较深,而且特征图的尺寸相对较小,具有较大的感受野,因此适用于提取高级语义信息。
(3)特征融合模块: 这个模块被用来融合Detail分支和Semantic分支的特征,以便充分利用两个分支的信息。
3.2 PENet用于生成虚拟点
附近对象在LiDAR扫描中的几何形状通常相对完整,而对于远距离对象则恰恰相反。此外,由于2D图像数据与3D LiDAR数据之间的固有差异,导致了数据增强技术的不足。
因此,作者采用PENet将2D图像转换为3D虚拟点云。该转换操作统一了图像和原始点云的表示,使模型能够像处理原始点云数据一样处理图像。
 PENet
PENet
PENet论文提出一个两分支的架构,包括:一个颜色主导分支和深度主导分支来开发和融合这个信息。更具体地来讲,一个分支输入颜色信息和一个稀疏深度图来预测一个稠密深度图。另外一个分支输入稀疏深度图和先前预测的深度图,输出一个较好的稠密深度图。从两个分支预测的深度图是互补的,因此它们是自适应融合。 另外,PENet论文也提出一个简单几何卷积层去编码3D几何线索。这个几何编码框架进行多个阶段不同形态的融合,获得较好的深度补全结果。作者进一步实施扩展和加速 CSPN++ 来精细融合深度图。所提出的全模型在当时KITTI深度补全竞赛中排名第一。
3.3 绘制虚拟点
(1)利用从PENet深补全网络得到的密集填充的深度图,通过已知投影,可以生成一组虚拟点。将它们与原始LiDAR点对齐,有效地生成一个包含N个点的增强的LiDAR点云。
(2)分割网络产生C个类别的分数(跟具体数据集有关系)。
(3)增强的LiDAR点投影到图像上,并将与相应的像素坐标(h, w)对应的分割分数附加到增强的LiDAR点上,从而创建绘制好的LiDAR点。这一转换过程涉及齐次变换,

3.4 距离感知的数据增强
本文提出一种采样策略,同时考虑了激光雷达扫描机制和场景遮挡。
对于一个附近的真实框及其内部点,引入一个随机距离偏移,然后将这些点转换为球坐标系,并将它们体素化为与LiDAR的角分辨率一致的球形体素。在每个体素内,计算点之间的距离。如果点距离非常接近,几乎可以忽略不计,低于预定义的阈值,就计算这些点的平均值。这导致了一组采样点,这些点密切模仿了实际扫描点的分布模式。
此外,随机删除密集LiDAR点的一部分来模拟遮挡,来间接地解决训练期间遮挡样本稀缺的问题。

3.5 任意的3D检测器
在最后阶段,3D检测器以绘制增强点云的形式作为输入。由于Backbones或其他组件没有改变,所以将绘制好的点云作为输入到任何3D检测器(如PointRCNN、VoxelNet、PVRCNN、PointPillars等),都可以直接获得最终检测结果。

四、实验结果
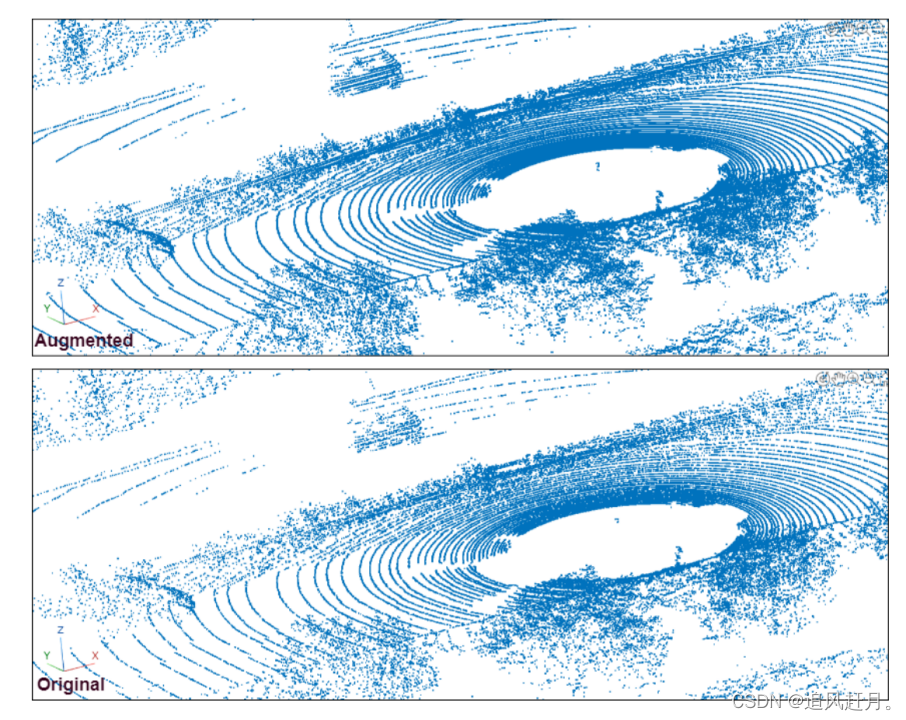 增强的LiDAR点云和原始LiDAR点云的对比图
增强的LiDAR点云和原始LiDAR点云的对比图
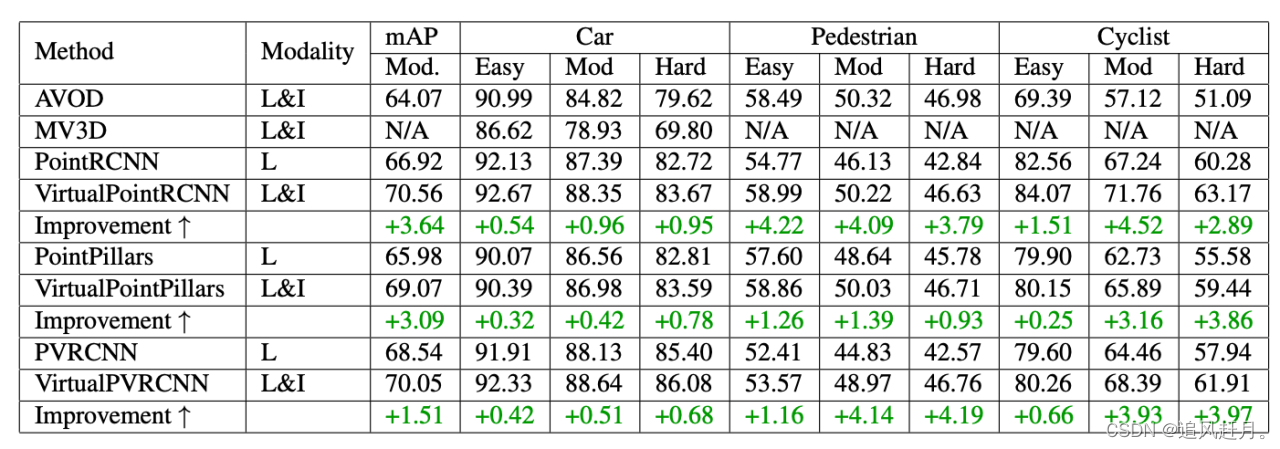
KITTI测试集上的BEV检测基准的结果
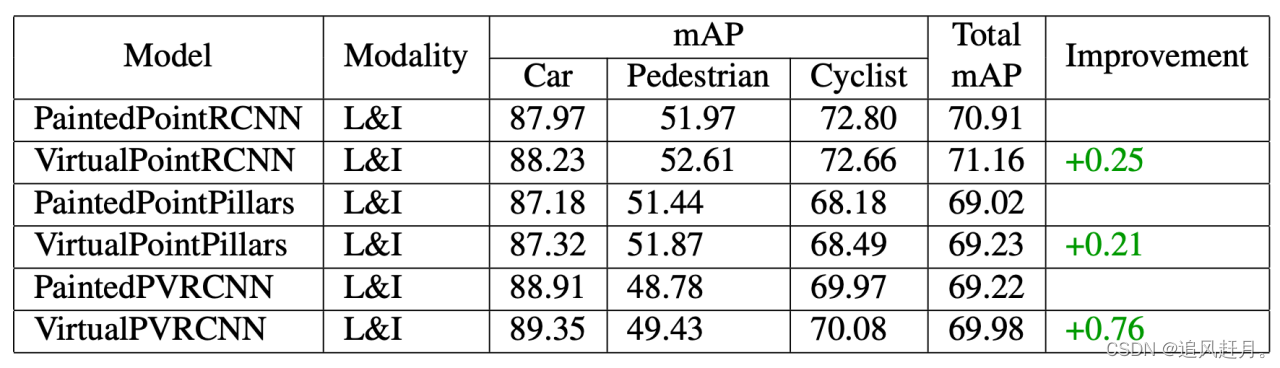
基于VirtualPainting的模型与基于Painting的模型的比较
 nuScenes测试集上的性能比较
nuScenes测试集上的性能比较
 不同的多模态和单模态框架的推理速度
不同的多模态和单模态框架的推理速度
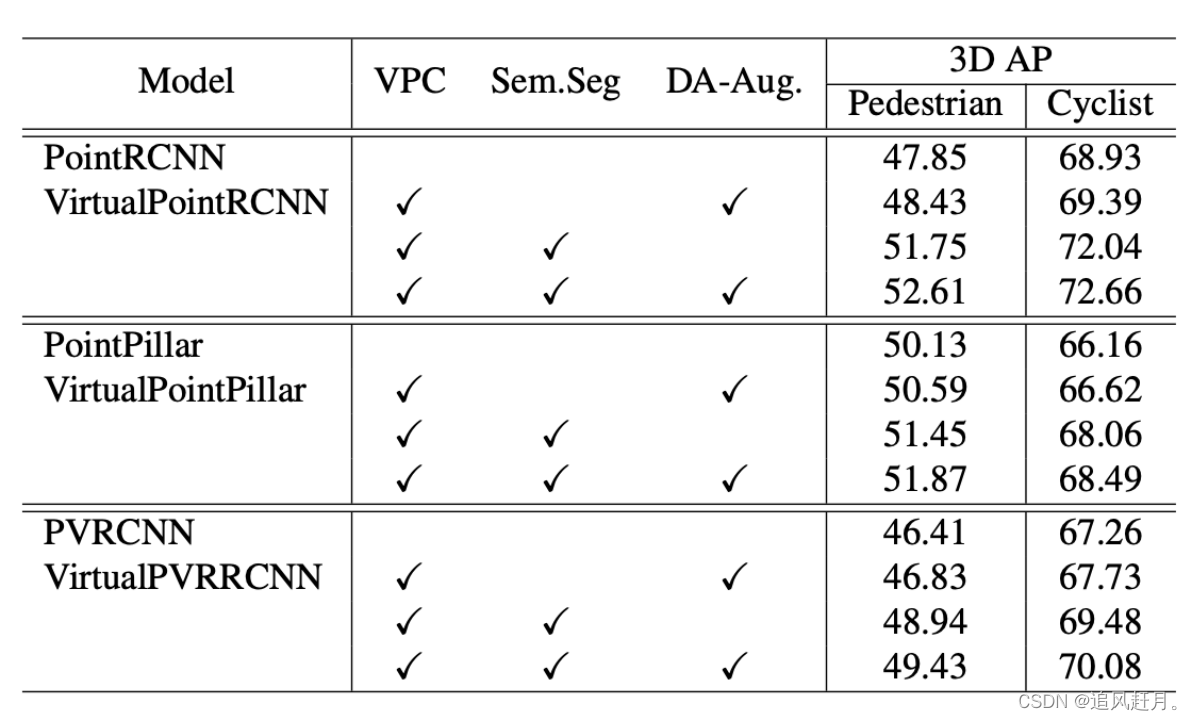
KITTI测试集上不同组件的影响
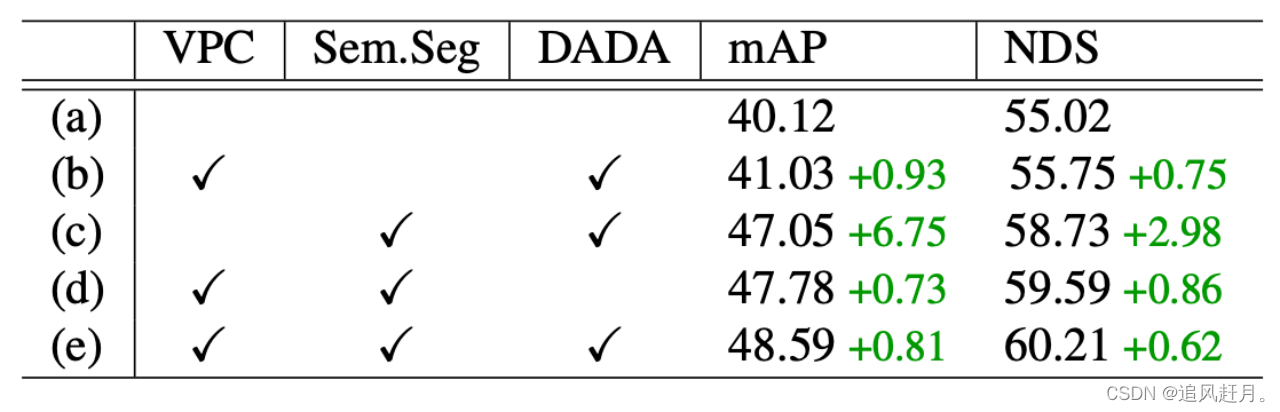 nuScenes数据集上的消融研究
nuScenes数据集上的消融研究
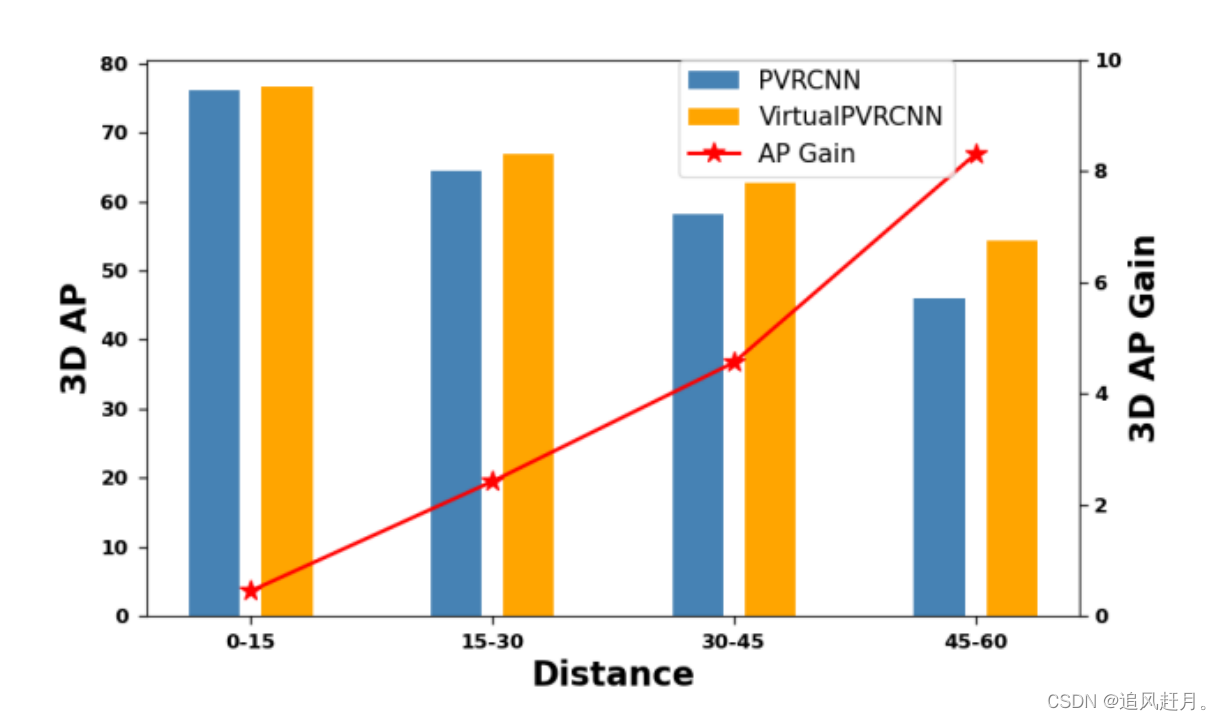
不同检测距离(KITTI测试集)上的性能提升和自行车类别的3D AP
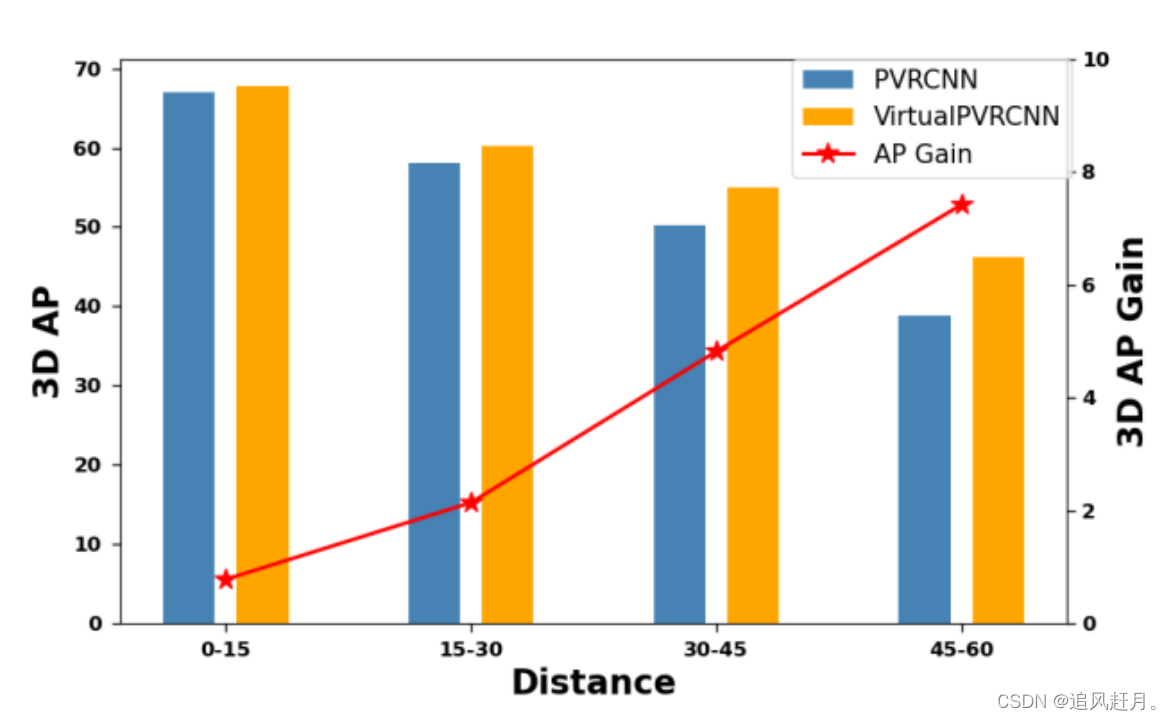
不同检测距离(KITTI测试集)上的性能提升和行人类别的3D AP
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









