







一、前言
在自然语言处理(NLP)领域,模型架构的不断发展极大地推动了技术的进步。从早期的循环神经网络(RNN)到长短期记忆网络(LSTM)、Transformer再到当下火热的Mamba(放在下一节),每一种架构都带来了不同的突破和应用。本文将详细介绍这些经典的模型架构及其在PyTorch中的实现,由于我只是门外汉(想扩展一下知识面),如果有理解不到位的地方欢迎评论指正~。
个人感觉NLP的任务本质上是一个序列到序列的过程,给定输入序列 ,要通过一个函数实现映射,得到输出序列
,这里的x1、x2、x3可以理解为一个个单词,NLP的具体应用有:
-
机器翻译:将源语言的句子(序列)翻译成目标语言的句子(序列)。
-
文本生成:根据输入序列生成相关的输出文本,如文章生成、对话生成等。
-
语音识别:将语音信号(序列)转换为文本(序列)。
-
文本分类:尽管最终输出是一个类别标签,但在一些高级应用中,也可以将其看作是将文本序列映射到某个特定的输出序列(如标签序列)。
二、RNN和LSTM
2.1 RNN
循环神经网络(RNN)是一种适合处理序列数据的神经网络架构。与传统的前馈神经网络(线性层)不同,RNN具有循环连接,能够在序列数据的处理过程中保留和利用之前的状态信息。网络结构如下所示:
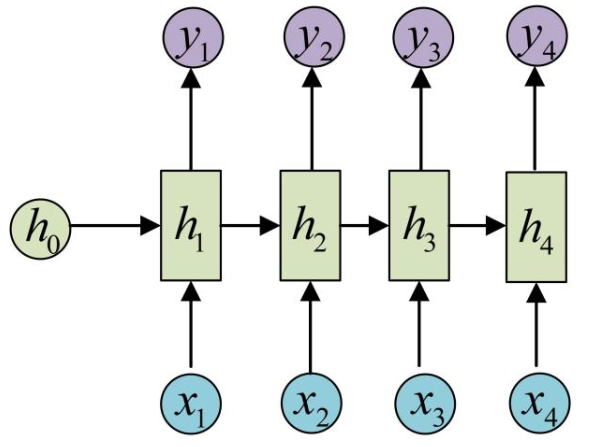
RNN的网络结构
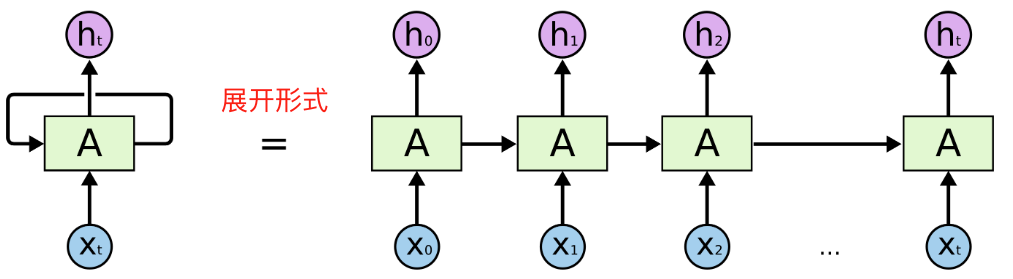
x和隐藏状态h的计算过程
RNN通过在网络中引入循环连接,将前一个时间步的输出作为当前时间步的输入之一,使得网络能够记住以前的状态。具体来说,RNN的每个时间步都会接收当前输入和前一个时间步的隐藏状态,并输出新的隐藏状态。其核心公式为:
-
𝑥𝑡 是当前时间步的输入。
-
ℎ𝑡 是当前时间步的隐藏状态。
-
ℎ𝑡−1 是前一个时间步的隐藏状态(如果是第一个输入,这项是0)。
-
𝑦𝑡 是当前时间步的输出。
-
𝑊ℎ𝑥𝑊ℎℎ𝑊ℎ𝑦 都是权重矩阵,是可以共享参数的。
-
𝑏ℎ 𝑏𝑦 是偏置。
-
𝜎𝜙 是激活函数。
2.1.1 RNN的优点
-
处理序列数据:RNN可以处理任意长度的序列数据,并能够记住序列中的上下文信息。
-
参数共享:RNN在不同时间步之间共享参数,使得模型在处理不同长度的序列时更加高效。
2.1.2 RNN的缺点
-
梯度消失和爆炸:在训练过程中,RNN会遇到梯度消失和梯度爆炸的问题,导致模型难以训练或收敛缓慢。
-
长距离依赖问题:RNN在处理长序列数据时,容易遗忘较早的上下文信息,难以捕捉长距离依赖关系。
-
不能并行训练:每个时间步的计算需要依赖于前一个时间步的结果,这导致RNN的计算不能完全并行化,必须按顺序进行。这种顺序性限制了RNN的训练速度,但是推理不受影响(尽管推理过程同样受到顺序性依赖的限制,但相比训练过程,推理的计算量相对较小,因为推理时不需要进行反向传播和梯度计算。推理过程主要集中在前向传播,即根据输入数据通过模型得到输出。因此,推理过程中的计算相对较快,尽管不能并行化,但在许多实际应用中仍然可以达到实时或接近实时的性能)。
关于长距离依赖问题的理解:
在RNN中,每个时间步的信息会被传递到下一个时间步。然而,随着序列长度的增加,早期时间步的信息需要通过许多次的传递才能影响到后续时间步。每次传递过程中,信息可能会逐渐衰减。这种逐步衰减导致RNN在处理长序列数据时,早期时间步的信息可能被遗忘或淹没在新信息中。
同时,在训练RNN时,通过时间反向传播算法(Backpropagation Through Time, BPTT)来更新参数。这一过程中,梯度会从输出层反向传播到输入层。然而,长序列中的梯度在多次反向传播时,容易出现梯度消失(梯度逐渐变小,趋近于零)或梯度爆炸(梯度过大,导致数值不稳定)的现象。梯度消失会导致模型难以学习和记住长距离依赖的信息,梯度爆炸则会导致模型参数更新不稳定。
2.1.3 代码实现
以下的实现都是基于文本分类任务进行的:
import torch
import torch.nn as nn
class TextRNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers, dropout, num_classes):
super(TextRNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.rnn = nn.RNN(embedding_dim, hidden_dim, num_layers, batch_first=True, dropout=dropout)
self.fc = nn.Linear(hidden_dim, num_classes)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.embedding(x)
rnn_out, hidden = self.rnn(x)
x = self.dropout(rnn_out[:, -1, :])
x = self.fc(x)
return x如果不用torch自带RNN的api的话,下面是自搭版本:
import torch
import torch.nn as nn
class CustomRNNLayer(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(CustomRNNLayer, self).__init__()
self.hidden_dim = hidden_dim
self.i2h = nn.Linear(input_dim + hidden_dim, hidden_dim)
self.h2o = nn.Linear(hidden_dim, hidden_dim)
self.tanh = nn.Tanh()
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = self.tanh(self.i2h(combined))
output = self.h2o(hidden)
return output, hidden
class TextRNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers, dropout, num_classes):
super(TextRNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









