







原文网址:
http://cpmarkchang.logdown.com/posts/279710-neural-network-neural-turing-machine
Introduction
Recurrent Neural Network 在进行Gradient Descent 的时候,会遇到所谓的Vanishing Gradient Problem ,也就是说,在后面时间点的所算出的修正量,要回传去修正较前面时间的参数值,此修正量会随着时间传递而衰减。
为了改善此问题,可以用类神经网路模拟记忆体的构造,把前面神经元所算出的值,储存起来。例如: Long Short-term Memory (LSTM) 即是模拟记忆体读写的构造,将某个时间点算出的值给储存起来,等需要用它的时候再读出来。
除了模拟单一记忆体的储存与读写功能之外,也可以用类神经网路的构造来模拟Turing Machine ,也就是说,有个Controller ,可以更精确地控制,要将什么值写入哪一个记忆体区块,或读取哪一个记忆体区块的值,这种类神经网路模型,称为Neural Turing Machine 。
如果可以模拟Turing Machine ,即表示可以学会电脑能做的事。也就是说,这种机器学习模型可以学会电脑程式的逻辑控制与运算。
Neural Turing Machine
Neural Turing Machine 的架构如下:
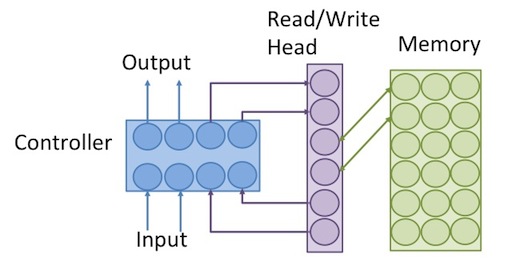
可分为几个部分:
Input: 从外部输入的值。
Output: 输出到外部的值。
Controller: 相当于电脑的IO和CPU,可以从外部输入值,或从记忆体读取值,经过运算,再将算出的结果输出去,或写入记忆体, Controller 可以用feed forward neural network 或者recurrent neural network (相当于有register的CPU)来模拟。
Read/Write Head: 记忆体的读写头,相当于pointer ,是要被读取或被写入的记忆体的address。
Memory: 记忆体,相当于电脑的RAM,同一个地址可对应到一整排的记忆体单位,就像电脑一样,用8个bit组成的一个byte,具有同一个memory address。
以下细讲每一部份的数学模型。
Memory
memory 是一个二维阵列。如下图,一个memory block 是由数个memory cell 所构成。同一个block 中的cell 有相同的address 。如下图中,共有
n
个block , 每个block 有

操作Memory 的动作有三种:即Read , Erase 和Add 。
Read
Read 是将记忆体里面的值,读出来,并传给controller 。由于记忆体有很多个memory block ,至于要读取哪个,由读写头( Read/Write Head )来控制,读写头为一个向量 w ,其数值表示要读取记忆体位置的权重,满足以下条件:
读写头内部各元素
wi
的值介于0 到1 之间,且加起来的和为1 ,这可解释为,读写头存在的位置,是用机率来表示。而读出来的值,为记忆体区块所储存的值,乘上读写头在此区块
i
的机率
其中,
r
为Read vector ,即从记忆体读出来的值,
M(i)
为记忆体
i
区块的值, 而
例如下图中, w(0)=0.9 , w(1)=0.1 ,即表示,读写头在位置0 的机率为0.9,在位置1 的机率为0.1 。

将上图中记忆体内部的值 M(i) ,以及读写头位置的值 w(i) ,代入公式(1),即可得出
Erase
如果要删除记忆体内部的值,则要进行Erase ,过程跟Read 类似,都需要用读写头w 来控制。但删除的动作,需要控制去删除掉哪个memory cell 的值,而不是一次就把整个memory block 的值都删除。所以需要另一个erase vector e 来选择要被删除的cell 。 erase vector 为一向量,如下:
其中,
j
为一个介于0~m-1 之间的数, m 为block size 。向量元素的值
其中, w 是用来控制要清除哪个memory block 而 e 是要控制清除这个block 里面的哪些cell ,如下图所示:

上图中,根据
w
和
e
这两个向量所选择的结果, 在
M
中,共有四个cell 的值被削减了,分别位于左上角和左下角,用较明亮的背景色表示其位置。
将上图中
w
、
e
和
M
中的值,代入公式(2) ,可得出此结果,如下:
Add
将新的值写入记忆体的动作为 add 。之所以称为add (而非write )因为这个动作是会把记忆体内原本的值,再「加上」要写入的值。至于要把哪些值加到记忆体,则需要有一个add vector ,其维度和memory block 的大小 m 相同。 Add 的公式如下:
过程如下图所示:

上图中,位于
M
的左上角,共有四个cell 的值被增加了。
将上图中
Controller
Controller 为控制器,它可以用类神经网路之类的机器学习模型来代替,但其实可以把它当成是黑盒子,只要可以符合下图中所要求的input 、 output 以及各种参数的值,就可以当controller 。

上图中, controller 根据外部环境的输入值input,以及read vector r ,经过其内部运算,会输出output 值到外在环境,还有erase vector e 和add vector a ,来控制记忆体的清除与写入。但还缺少了读写头向量 w 。
如果要产生读写头向量 w , 需要透过一连串的Addressing Mechanisms 的运算,最后即可得出读写头位置。而controller 则负责产生出Addressing Mechanisms 所需的参数。
Addressing Mechanism
controller 会产生五个参数来进行addressing mechanisms ,这些参数分别为: k,β,g,s,γ 。其中, k 和 s 为向量,其余参数为纯量,这些参数的意义,在以下篇章会解释,整个addressing mechanisms 的过程如下图所示。

上图中,总共有四个步骤,这四个步骤共需要用到这五种参数,经过了这一连串的过程之后,最后所产生出的 w 即为读写头位置,如上图左下角所示。以下细讲每个步骤在做什么。
Content Addressing
首先,是找出记忆体中跟参数memory key k 值最相近的记忆体区块。
读写头的位置
w
,就先根据记忆体区块中,跟
其中,
K[k,M(i)]
表示memory key
k
跟记忆体区块
M(i)
的cosine similarity ,即两向量的夹角,如果
k
跟
M(i)
的内容越接近的话,则
K[k,M(i)]
算出来的值会越大。最后算出来的值
w(i)
,即是
k
跟
M(i)
的相似度,除以记忆体内所有区块相似度,标准化的结果。
cosine similarity 的公式如下:
经过了cosine similarity 后,越相似的向量,值会越大,而参数 β 是个大于0的参数,可用来控制 w 内的元素值,集中与分散程度,如下图所示:

上图中,向量 k 中的值,与记忆体中第三行区块的值最相似(用较浅色的背景表示)。但如果 β 很大(例如: β=50 ),算出来的 w 值会集中在第三个位置,也就是说,只有第三个位置的值是1,其他都是0(用较浅色的背景表示),如上图的左下方。如果 β 很小(例如: β=0 ),则算出来的 w 值会平均分散到每个元素之中,如上图的右下方。
Interpolation
读写头其实也是有「记忆」的,也就是说,目前时间点的 wt ,也可能会受到上个时间点 wt−1 的影响,要达到这样的效果,就是用content addressing 所算出的值 wt ,和上个时间点的读写头位置` wt−1 做interpolation ,公式如下:
其中,参数
g
用来表示

如果 g=1 ,则 w 的值会完全取决于这个时间点content addressing 所算出的值,如上图的左下方,若 g=0 ` , w 会完全取决于上个时间点的值,如上图的右下方。
Convolutional Shift
如果要让读写头的位置可以稍微往左或往右移动,这就要用Convolutional Shift 来做调整。参数 s 是一个向量,用convolutional shift ,来将 w 的值往左或往右平移,公式如下:
举个例子,如果 s 中有三个元素: s−1,s0,s1 ,则 w(i) 经过了以上公式后,结果如下:
根据此公式, w(i) 的值,如下图所示:

也就是说, s−1=1 时,可让原本的 wi+1 往左移一格,移到 wi ,若` s1=1 时,可让原本的 wi−1 往右移一格,移到 wi 。
举个例子,如果 s−1=1,s0=0,s1=0 ,则 w 中的值,全部往左移动一格,若碰到边界则再循环到最右边,如下图左方所示。如果 s−1=0,s0=0,s1=1 ,则 w 中的值,全部往右移动一格。若 s−1=0.5,s0=0,s1=0.5 ,则 w 为往左和往右移动后的平均,如下图右方所示。

Sharpening
此过程是再一次调整 w 的集中与分散程度,公示如下:
其中, γ 的功能和Content Addressing 中的 β 是一样的,但是经过了接下来的Interpolation 跟Convolutional Shift 之后, w 里面的集中度又会改变,所以要再重新调整一次。

Experiment: Repeat Copy
关于Neural Turing Machine 的学习能力,可以参考以下例子。
在训练资料中,给定一个区块的data (如下图左上角红色区块)做为input data ,将这个区块复制成七份,做为output data 。则Neural Turing Machine 有办法学会这个「复制」过程所需的运算程序,也就是重复跑七次输出一样的东西。


从上图中,可看到读写头的移动,重复走了相同的路径,走了七次,依序将记忆体中储存的 input data 的值,读出来并输出到output 。
有个完整的 Neural Turing Machine 套件,以及此实验的相关程式码于:https://github.com/fumin/ntm
Reference
Alex Graves, Greg Wayne, Ivo Danihelka. Neural Turing Machines. 2014















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









