







不管是做游戏也好,软件也好,平时或多或少都会用到一些排序算法,而对于很多人来说估计直接就冒泡排序了。。甚至有些连冒泡都得百度。不论对错,多会几种排序总是没错的,不同的情况选用不同算法,这样出来的效率也相对来说高些。下面分别介绍下冒泡排序、选择排序、快速排序、桶排序这几种基础排序算法。(lua语言示例)
首先是冒泡排序,这是大多数程序员首先接触到的一种排序算法,很简单也很容易理解,顾名思义就是要让被排序的数像水泡一样冒上来。但其实不常用的话还是会记不住那两个循环里面的参数。。。
为了便于记忆,来拆一下这个算法:(按从小到大排序)
第一步
遍历要排序的数组A,每相邻的两个数之间进行比较,若 A[i]<A[i-1] 则交换两个数。那么这样 一次遍历之后,这个数组中最大的数就会“冒泡”到数组末尾。代码如下:
for i=2,#_array do --也可以 for i=1,#array-1 do 下面就得是 i和i+1了
if _array[i-1] > _array[i] then
local t = _array[i-1];
_array[i-1] = _array[i];
_array[i] = t;
end
end 第二步
第一步完成了一次冒泡动作并确定了一个数的位置,接下来想要确定所有数的位置只需要完成#_array次冒泡动作就可以。完整代码如下:
function Sort:BubbleSort(_array)
for j=#_array,1,-1 do
for i=2,j do --这里循环到j的原因是一次遍历就会确定数组末的一个数,所以不需要每次都遍历整个数组
if _array[i-1] > _array[i] then
local t = _array[i-1];
_array[i-1] = _array[i];
_array[i] = t;
end
end
end
end图片是整个冒泡排序的过程:

以上是冒泡排序,接下来介绍一下选择排序,这个算法其实是根据冒泡改进而来的,自己地下可以去搜索引擎上了解下算法复杂度的相关概念,计算机执行遍历语句是需要资源开销的,而执行交换语句需要的开销要更多,上面我们看一下冒泡算法发现没遍历一次都会有一次交换。这样其实会浪费很多不必要的资源,因为一次冒泡动作就是为了确定一个最大(最小值)并放大数组的开头(结尾);这样的话把代码简化一下,如下:
local min = 1 -- minIndex
for i=1,#_array do
if _array[i] < _array[min] then
min = i
end
end
local t = _array[min];
_array[min] = _array[1] --确定最小值以后 跟数组开头交换
_array[1] = t;这段代码是不是也完成了相同的功能?(Amazing!。。) ok,如同冒泡排序,进行相应次的交换知道确定整个数组中所有元素的位置,完整代码如下:
function Sort:SelSort(_array)
local min = 1
for j=1,#_array do
for i=j,#_array do
if _array[i] < _array[min] then
min = i
end
end
local t = _array[min];
_array[min] = _array[j]
_array[j] = t;
end
end图片是选择排序算法的整个过程:
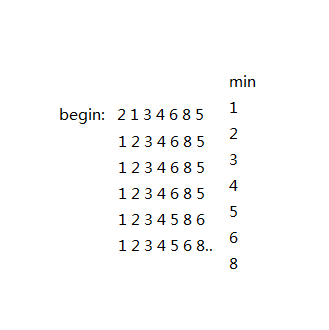
选择排序介绍到这里,下面是快速排序(听名字就很快,反正比冒泡快),这个算法的原理先解释一下:选取要排序数组的首个元素作为排序的标杆K,
一、首先从右到左(#A →A[1])遍历(i做下标,即i- -),如果遇到比K小的元素,则进行交换,然后终止此次遍历。
二、开始从左到右遍历(A[1]→#A) (j做下标,即j++),继续与K进行比较交换,不过这次是需要比K大的元素。
三、重复一二步骤直到第一步没有遇到比K小的元素(j>=i),那么就会确定K现在所在的位置及之前的元素已经排好顺序。(脑补不了就在纸上画画)
四、选取剩下的数组的首个元素作为新的K然后以上步骤迭代即可。
这次先上图:

代码:
function Sort:quickSort(_array,_left,_right) -- left right 是数组的首和末
if _left >= _right then --跳出此次递归
return;
end
local first = _left;
local last = _right;
local key = _array[first]
while first < last do
while first < last and _array[last] >= key do --步骤一
last = last - 1;
end
_array[first] = _array[last];
-- Sort:swap(_array,first,last);
while first < last and _array[first] <= key do --步骤二
first = first + 1;
end
_array[last] = _array[first];
-- Sort:swap(_array,last,first);
end
_array[first] = key;
Sort:quickSort(_array,_left,first - 1) --递归,人肉调试一下就会明白过程
Sort:quickSort(_array,first+1,_right)
end 快速排序就介绍到这里,接下来是桶排序,这个算是最容易理解的一种排序算法了,有点投机的意思。使用本算法的前提是要确定要排序的所有元素的范围。比如我们要排序的数组是10个随机生成的1-10之间的整数,那么要用桶排序就需要先准备10个桶1-10,然后遍历数组,把元素扔到相对应的桶里。一次遍历几个确定所有元素的位置,最后按桶的顺序输出即可(没有的不输出)。这个算法的优点是时间复杂度低,只需要一次遍历即可,还可以统计每个元素的数量;缺点是如果排序元素的范围不确定不可行,范围太大需要的桶开销也会很大,而且还可能有很多浪费(比如排序1 2 3 9999),而且像小数这种类型的数据也不可行。比较适合用于元素量很大,而范围又不大的数据,(最常见的是每年的中高考成绩排序,数量很大但范围确定,这时候用上述三种算法效率都比较低)。
代码:
function Sort:TSort(_array,_begin,_end)
local T = {} ;
for i=_begin,_end do
T[i] = 0;
end
for i=1,#_array do
T[_array[i]] = T[_array[i]]+1;
end
local II = 1;
for i=1,#T do
for j=1,T[i] do
_array[II] = i;
II = II + 1;
end
end
end这个算法比较简单,就不上图了,大概就是这四种比较基础的算法,我写的比较粗浅,想要了解更多就去买些算法书或者自行百度(google)。平时用到排序的话,大概分析下需求挑选看哪个算法比较合适,最好不要一上来就各种冒泡。。一般来说:快速排序是最快的。
PS:以上代码用的是lua语言编写,_array是要排序的数组,注意这里的数组是引用传递型的,如果用值传递的话,就在函数内部新建一个数组然后return出去就可以。
最后,恩,欢迎各位砸意见。















 705
705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









