









最近在学习网络相关知识,看到一篇博文写的挺好,学习下!
文章转载自:http://blog.csdn.net/horkychen/article/details/50823594
网络的优劣会影响网络交互的延迟时间、稳定性和速度,从用户体验上集中表现为打开页面的速度缓慢。比如在较差的网络并发的请求数会被降低,以避免网络性能因为阻塞而进一步恶化。
针对不同网络品质的优化的前提就是要有一种方法来度量网络的品质。
目前度量网络的品质的方法如果仅以网络连接类型来区分,比如2G, 3G, Wifi等,无法有效感知到当时的网络状态。在同一网络连接类型下,网络的品质仍有大幅波动,可能会因为阻塞以及线路上问题导致延迟上抖动(jitter)、丢失数据包、数据包损坏等情况。在现实场景中,比如繁忙时段,或者处在信号不好的区域时(如交通工具上),使用网络类型来判断当时的网络品质会有很大偏差。
本文基于对一段时间的网络数据的记录,进行算法处理,可以测出一个衡量当时网络状态的指标(MI: Measurement Index)。具体应用到移动设备上时,考虑到计算量的问题,可以使用近似算法减小计算的复杂度。
目前的使用的算法是结合历史数据进行统计,即运行指数平滑算法。这样理论上因为同时使用了本次及之前的历史的数据进行计算,可以将单次统计的数据量减少。
网络数据的定义是通过模拟测试环境录制得来。其中包括两个主要内容:
1. 定义网络评测的参数
2. 定义网络状态区间范围
在实际应用时,还需要考虑数据采集的区间和数据量,以及数据的平滑处理。
网络评测的参数
经过对比评估以下六个参数对应于latency和bandwidth的设定,得到数据如下:
1. Speed, 传输速率:由收完数据的时间除去所收取的数据大小。
2. Header Received: 收到响应头的时间 (即TTFB)。
3. Connected: 连接到主机的时间。
4. Sent: 在Java层完成调用完成发送请求的时间。
5. DNS Resolved: DNS解析的时间。
6. Finished: 整个请求完成的时间。
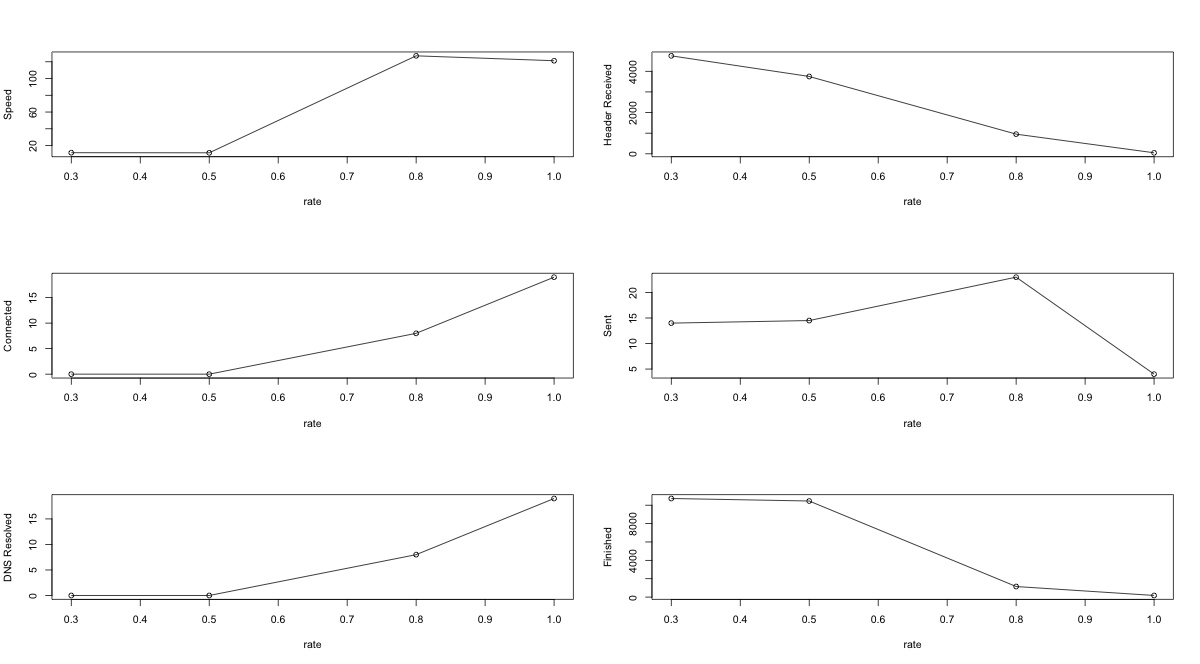
对比分析各参数中位数与网络状态(rate)后,发现以下参数与网络状态的关联关系,其中Header Received的关联关系为正相关。
所以定义由Header Received时间定为网络衡量指标
定义网络状态区间范围
关于网络状态范围,由于网络的波动性,不能限定在具体的一个值的区分。这里使用K中值分类法(R Script: compareData.R)。
将数据分为四个簇,依次取出其设定范围。再以目前测试发现最大值分布在12000左右(约为6000延迟), 所以使用13000,即最大延迟数,进行归一化处理。
下图表示的为分为四个簇的情况(每一项数据为一个URL测试5次所得结果):
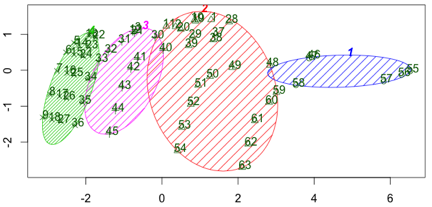
其中cluster 4最佳,cluster 1为最差的区间, 为保守起见,在目前的实现将cluster 1与cluster 2合并来看。
定义数据分析的时间段
依次采集分析2x1URL, 5x1URL,5x2URLs, 5x4URLs及3x1URL数据。对比各种情况下数据聚合的情况。其中2x1URL 表现数据不足,四个簇不能很好的分隔:
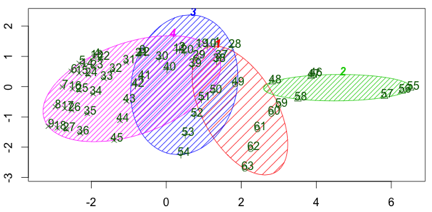
这时的每一项值的数据量为50条左右。
当3x1URL时,每一项值的数据量为80条上下,四个簇重合部分已经有很好的改善:
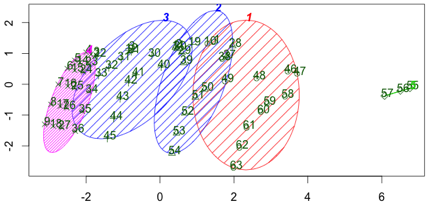
由上面可知,如果使用独立样本进行计算,50笔数据较难获得有效的样本数据,至少需要80笔数据,才能得出较合适的统计。而移动网络下,特别是2G网络下,80个请求会耗时太久,不利于及时体现当前网络数据。
目前的使用的算法是结合历史数据进行统计,即运行指数平滑算法。这样理论上因为同时使用了本次及之前的历史的数据进行计算,可以将单次统计的数据量减少。
定义数据的样本大小及采集周期
目前选定最小采集样本为15笔请求,包含失败的请求,其中失败的请求视为一次最大延迟记录(取值见上面的讨论)。 最小采集周期为30秒,最大采集周期为4分钟。
考虑到网络的变化特性,一是不能太快跳变,二是及时逼近。另外在移动网络下,数据量可能达不到采集的要求,必须有效地利用历史数据。所以系数的选择需要考虑到两个方面:一是收敛速度,二是兼顾历史数据(利用历史数据进行计算,并避免数据不准导致的误判。)。
这里存在三个变量: 采集的周期(t),采集的样本数(n)及平滑系数(a)。
采集样本数是指最小可以用于统计运算的数据数量。根据模拟测试(R脚本为simulatorPhase.R), 判断数据集的大小的波动性可以在平滑系数的辅助下达到一定的稳定性(平滑系数越小,数据分布越稳定,但收敛速度越慢.)。 比如下图中使用样本数15、平滑系数0.3的组合可以达到样本数20、平滑系数0.4组合的标准差范围。(平滑系数越大标准差越大!)
采集样本为20,平滑系数为0.4(总数据量4000),结果的标准差为579.87(非定值):
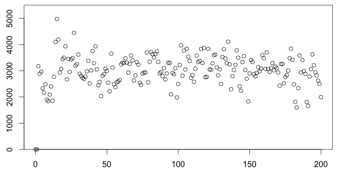
采集样本为15,平滑系数为0.4(总数据量4000),结果的标准差为589.16(非定值):
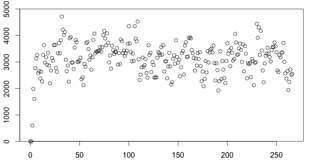
采集样本为15,平滑系数为0.3(总数据量4000),结果的标准差为576.41(非定值):
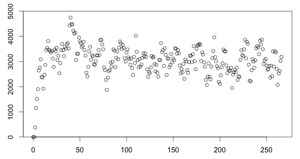
采集样本为15,平滑系数为0.6(总数据量4000),结果的标准差为872.23(非定值):
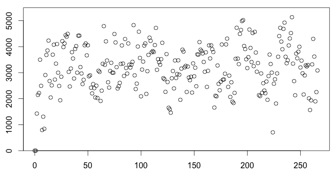
采集周期是指最小的数据采集时间,在此时间内只负责收集数据,不进行计算。在采集周期内可能并不会收集到足够的数据,就会延长到一个最大采集周期。
采集的周期的大小取决于最小采集样本的大小。目前设定为30秒。
最大采集周期的选定,取值于移动网络下,以无图模式一分钟浏览一个新浪新闻页面,达到采集样本数量的时间,即4分钟。
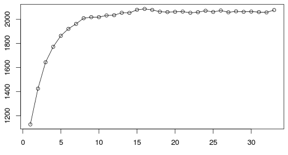
下图为上述参数在实际测试过程中观察到的Measurement Index分布的情况, 在数据演化将近6次(约3分钟)后维持到6385上下。
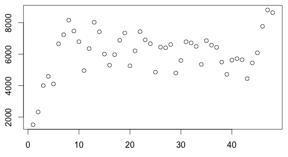
定义数据的平滑系数
不同的平滑系数会一个处理波动时的浮动范围,表示无法明确判别的区域,归为较好的网络处理。由此定义了实现时使用的模糊区间。
测试对比了多个候选的系数。以0.3及0.65为例说明如下。
平滑系数:0.3
指数0.3是假设网络环境相对稳定,但受网络抖动的影响会有波动。
在计算时选择经过多样本获得的历史数据的比重大于新取得的单样本数据。缺点是会造成逼近速度变缓, 近8次逼近到目标值(相差200以内)。
再模拟两次数据统计的波动。单次统计数据约为2000,若分成两次统计,可能会遇到一次3500,后一次500的大幅波动。应用系数0.3后统计结果保持在平均值2000的上下200的范围, 对应于指数上下浮动0.03。
以下为其示意图:
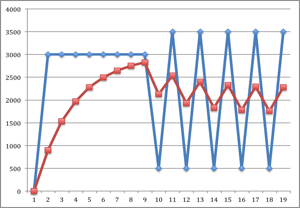
8次逼近所需时间视最小采集周期而定,一般情况下约为4分钟时间。
考虑大幅波动时的标准差,以3000~1500的波动为例,其标准差为:447.56。
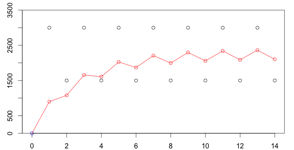
系数0.3最大的优势在于适应小样本数据的情况。详细之前的讨论。为了弥补主要的缺点,将在一个网络下第一次计算时,先使用系数0.5, 再调整为0.3。效果如下:
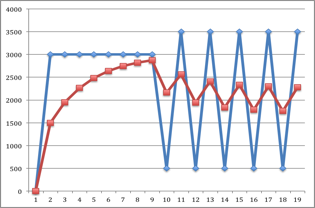
以下为实际测试结果(latency:2000,bandwidth 80kbps, standard MI:~2500):
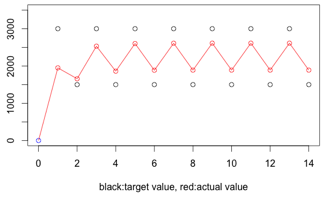
平滑系数:0.65
当选取0.65作为系数时,当前值所占的比重更高。需要3次运算逼近到设定值(130以内,占比小于1%)。
如上模拟两次数据统计的波动。这时统计结果保持在平均值2000的上下约800(逼近于777)的范围。即设定的界定值前后800对应于性能指数上下浮动0.06。
考虑大幅波动时的标准差,以3000~1500的波动为例,其标准差为:381.9。较系数取0.5时并没引入太多的误差,却将收敛所用的次数降低了2次。
与实际场景的对应
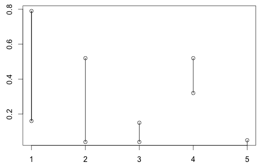
与现实场景的对应关系如下(收集的现场数据):
| Scenario | Latency | Index |
| 包含地铁繁忙时间的数据(2G) | 500~6000 | 19~100 |
| 地铁一般场景(2G) | 100~400 | 5~64 |
| 公司座位 | 200~500 | 32~52 |
| 3G&Wifi | 50~80 | 0~4 |
下面为其分布示意图(横轴依次代表上表中的五项,请忽略第3项数据):














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









