







本地知识库+语言大模型=知域问答
本项目实质为本地知识库构建及应用,内容包含:
- 本地知识库构建及应用相关知识的介绍
- 离线式本地知识库构建及应用
- 在线式本地知识库构建及应用
本地知识库构建及应用相关知识的介绍
本地知识库
本地知识库通常是指存储在本地计算机或服务器上的数据库或数据集,用于提供本地环境下的知识和信息。
本地知识库构建思路
- 收集知识,如txt文件等;
- 对文本进行切分;
- 将文本转化为向量;
- 将向量保存到本地向量数据库或者在线向量数据库;
- 与LLM联系构建问答应用。
其实算法的整体思路也是这些步骤,明显只靠LLM是不够的,我们还需要一些其他功能将LLM应用起来,langchain就提供了一整套框架帮我们更好的应用LLM。
LangChain介绍
langchain是一个开发基于语言模型应用程序开发框架,链接面向用户程序和LLM之间的中间层。利用LangChain可以轻松管理和语言模型的交互,将多个组件链接在一起,比如各种LLM模型,提示模板,索引,代理等等。
langchain-ChatGLM
langchain-ChatGLM项目就是参考了Langchain的思路,实现了本地知识库构建及应用,我们一起看下langchain-ChatGLM搭建本地知识库的流程。
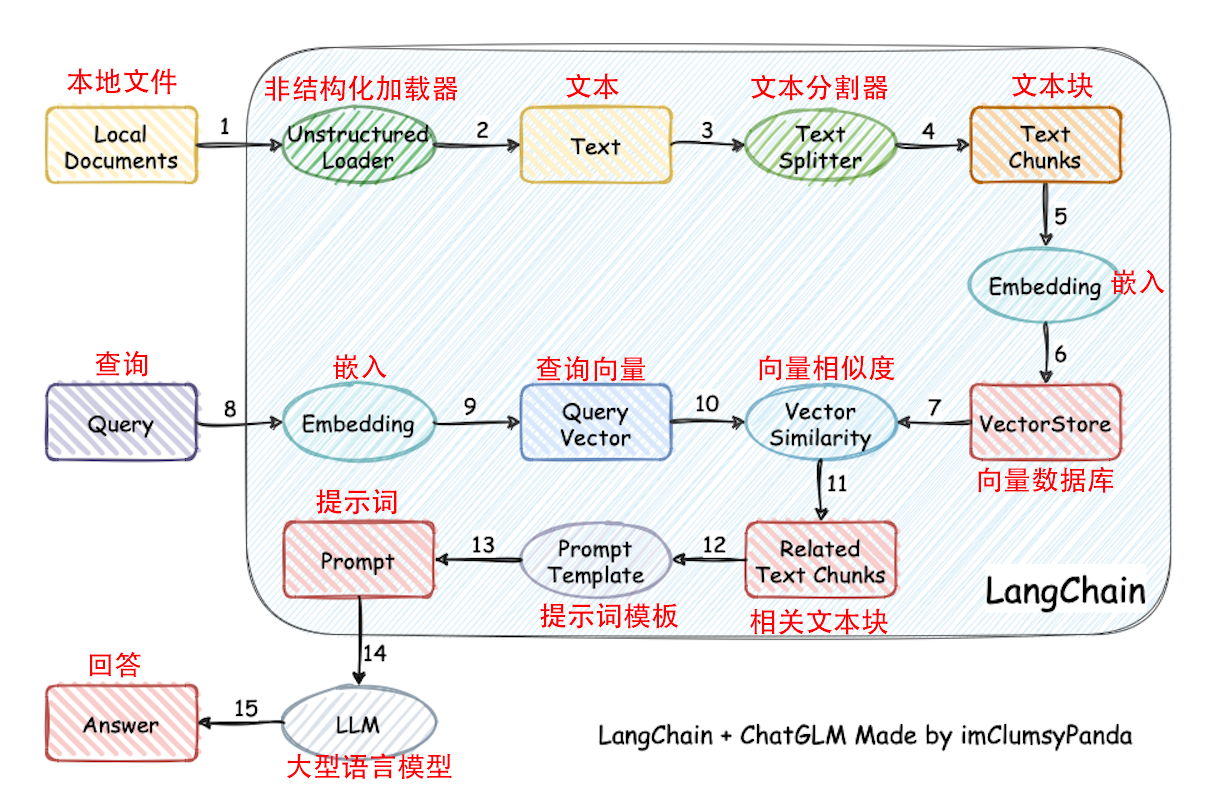
解释上图的langchain-ChatGLM项目流程如下:
(1-2)准备本地知识库文档,使用Unstructured Loader类加载文件,获取文本信息。
(3-4)对文本进行分割,将大量文本信息切分为chunks。
(5)选择一种embedding算法,对文本向量化,embedding算法有很多,选择其中一种即可。
(6)将知识库得到的embedding结果保存到数据库,保存到数据库后就不需要在执行上述步骤了。
(8-9)将问题也用同样的embedding算法,对问题向量化。
(10)从数据库中查找和问题向量最相似的N个文本信息。
(11)得到和问题相关的上下文文本信息。
(12)获取提示模板。
(13)得到输入大模型的prompt比如:"结合以下信息:" + 上下文文本信息 + "回答" + question + "输出规范:不要回答‘根据给出的信息、以上仅供参考、可以去哪里了解更多信息之类的’"。
(14)将prompt输入到LLM得到答案。
环境安装
In [ ]
# 创建持久化安装路径
!mkdir /home/aistudio/packages
!pip install langchain -t /home/aistudio/packages
# 加载文档
!pip install unstructured -t /home/aistudio/packages
# 解析表格
!pip install tabulate -t /home/aistudio/packages
# 使用sentence_transformers进行embedding
!pip install sentence_transformers -t /home/aistudio/packages
# 向量数据库
!pip install chromadb -t /home/aistudio/packages
!pip install supabase -t /home/aistudio/packages
# EB SDK
!pip install erniebot -t /home/aistudio/packages
# openai
!pip install openai -t /home/aistudio/packagesIn [ ]
# 执行完上面的环境安装部分后,以后再运行该项目只需要执行以下代码即可,无需重复安装环境
import sys
sys.path.append('/home/aistudio/packages')离线本地知识库搭建及应用
离线本地知识库构建及应用,离线本地知识库向量存储(VectorStore)使用的是Chroma。
切分文本
In [ ]
from langchain.document_loaders import UnstructuredFileLoader # 非结构化文件夹加载器,用于加载本地文件,目前,Unstructured支持加载文本文件、幻灯片、html、pdf、图像等
from langchain.text_splitter import RecursiveCharacterTextSplitter # 递归字符文本分割器,通过不同的符号递归地分割文档
# 导入文本
loader = UnstructuredFileLoader("bengbengbeng/lvzhe.txt")
# 将文本转成 Document 对象
data = loader.load()
print(f'documents:{len(data)}')
# 初始化分割器
# chunk_size每个分片的最大大小,chunk_overlap分片之间的覆盖大小,可以保持连贯性
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(data)
print("split_docs size:", len(split_docs), type(split_docs))文本生成Embedding
使用HuggingFaceEmbeddings生成Embedding数据
In [ ]
from langchain.vectorstores import Chroma # 围绕 ChromaDB 嵌入平台的包装器
from langchain.embeddings.huggingface import HuggingFaceEmbeddings # 文本嵌入模型
import IPython # 一个python的交互式shell
import sentence_transformers # 一个用于最先进的句子、文本和图像嵌入的 Python 框架
# 初始化 hugginFace 的 embeddings 对象
embeddings = HuggingFaceEmbeddings(model_name&# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











