







1.前言
Text2SQL(或称NL2SQL)是一种自然语言处理技术,旨在将自然语言(Natural Language)问题转化为关系型数据库中可执行的结构化查询语言(Structured Query Language,SQL),从而实现对数据库的查询和交互。这项技术的核心目标是通过自然语言描述,无需用户具备SQL语法知识,即可完成复杂的数据库查询任务
具体来说,Text2SQL的任务包括以下步骤:
-
1. 输入分析:用户以自然语言形式输入问题,例如“查找平均工资高于整体平均工资的部门名称”。
-
2. 语义解析:系统将输入的自然语言问题解析为数据库中的结构化查询语句。
-
3. SQL生成:根据解析结果生成对应的SQL语句,如“SELECT department_name FROM departments WHERE average_salary > (SELECT AVG(salary) FROM employees)”。
-
4. 执行与反馈:系统执行SQL查询并返回结果,同时可能对结果进行进一步的解释或分析。
Text2SQL的应用领域广泛,包括智能客服、数据分析、金融、医疗、教育等,能够显著提高用户与数据库交互的效率和便利性。此外,随着大型语言模型(LLMs)的发展,Text2SQL技术在处理复杂查询和多轮对话方面也取得了显著进展。
前期也给大家介绍过关于dify整合数据库实现图表生成的案例,同样也给大家实现过dify案例分享-基于database插件实现Text2sql的数据库查询图表工作流
有小伙伴和提出问题SQL 是写到大模型的提示词里面,如果想查询其他的语句,之前的工作流text2sql的方案就有问题。是的当时为了方便演示所以我们做了3个业务场景,并且把SQL 语句都已经提前写好了。当时的目的主要还是给大家提供演示方便,因为考虑到很多非技术人员对SQL 语句的编写是不熟悉的。此外目前的主流的text2sql方案也有不成熟的的。今天就带大家实现一个简单基于企业知识库的 AI Agent 的text2sql方案。当然这个方案也是属于比较简单的方案。话不多说下面带大家看一下效果。
工作流AI Agent演示效果
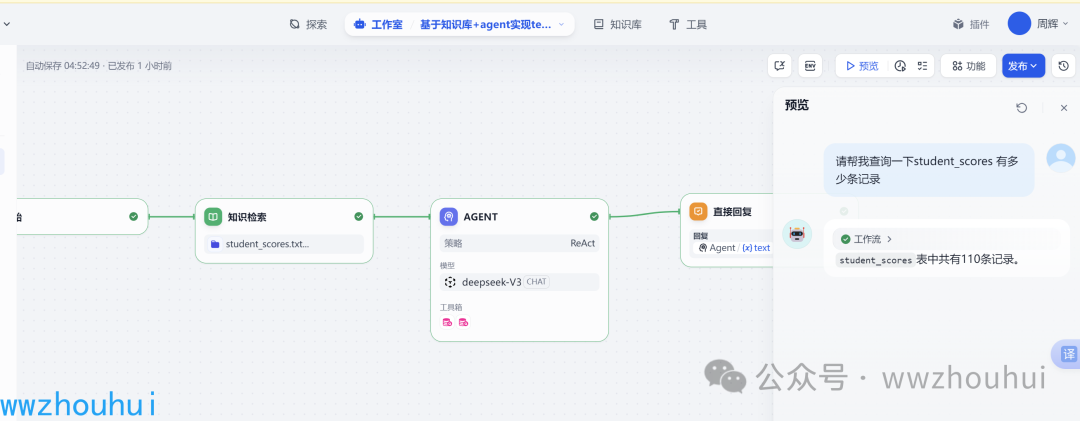
上图我们就通过简单的自然语言查询到student_scores 有多少条记录。
AI Agent 演示效果
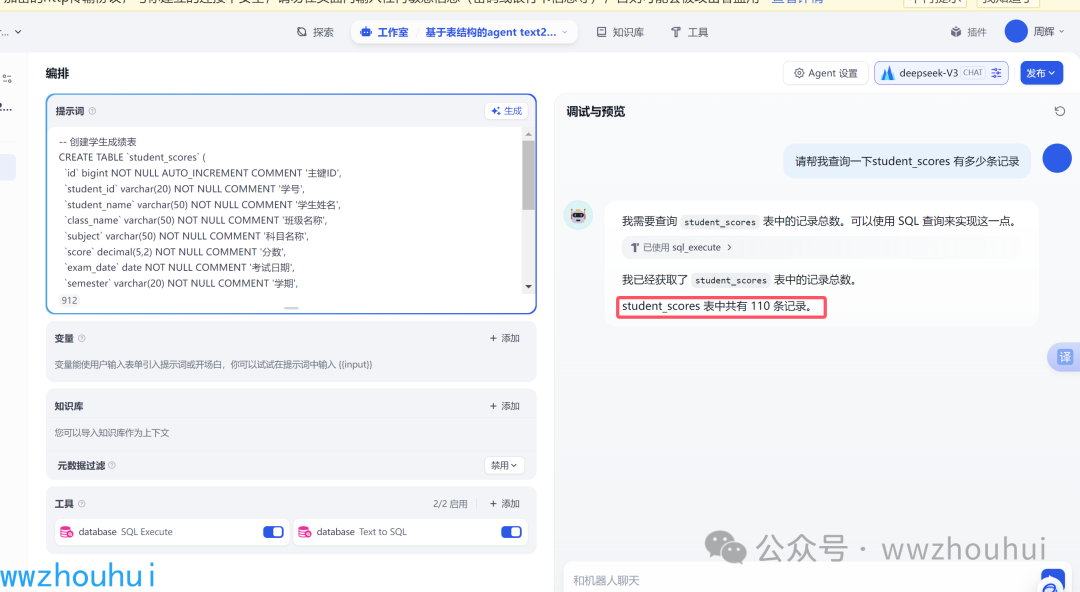
同样我们使用AI Agent 也实现了text2SQL 的效果。
那么上面的工作流和 AI Agent是如何实现的呢,下面说一下我们的具体实现思路。
2.工作流的制作
在工作流制作之前我们需要用到dify的知识库,之前我很少提到知识库,主要是dify知识库做的不太好。因为这个工作流用到知识库,所以我们顺便把这个知识点说一下。
知识库创建
在知识库创建之前我们需要向量模型,所以我们需要在系统模型设置里面填写一下 向量模型。
打开右上角设置-模型供应商
我们在找一下右上角有一个系统模型设置。
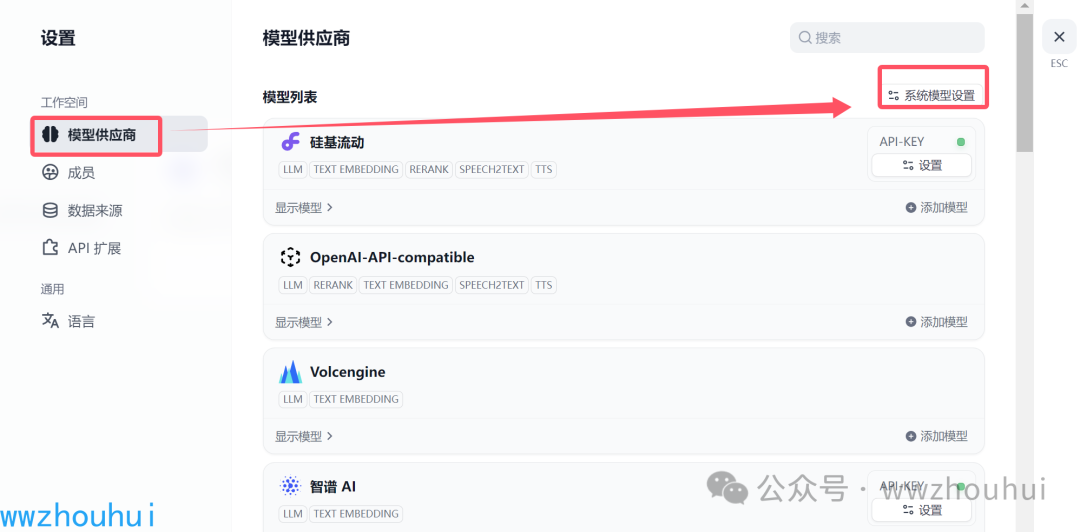
在弹开的模型设置里面,我把Embedding 模型、Rerank 模型 设置选一下。
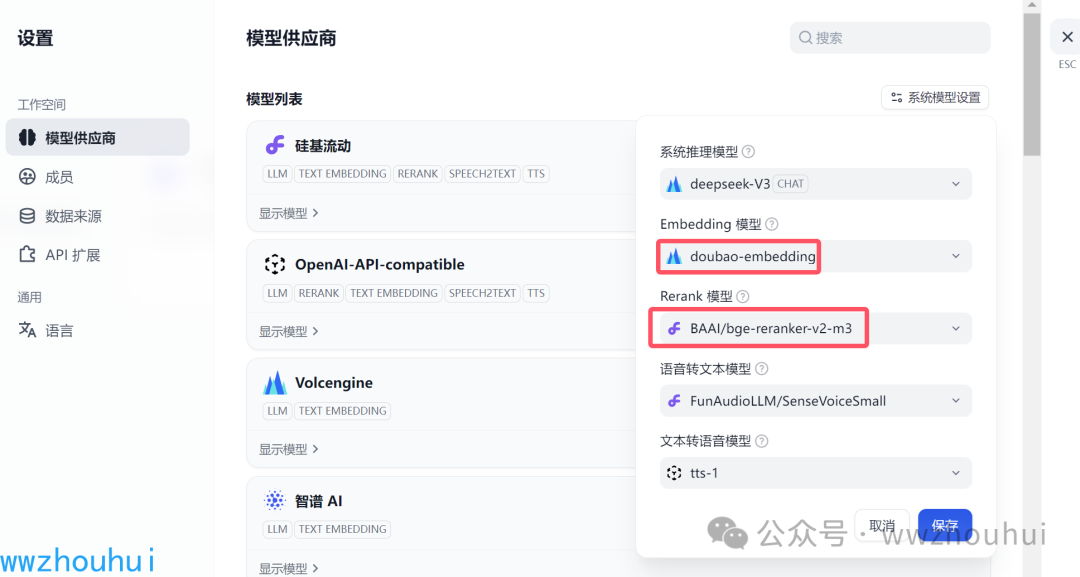
这里Embedding 模型 我们选择了火山引擎提供的 “doubao-embeding”,Rerank 模型 我们这里选择硅基提供的bge-reanker-v2-m3
上面配置好完成我们去知识库面板创建一个知识库
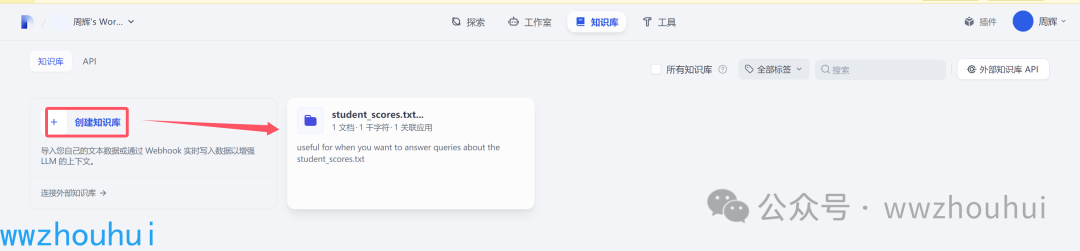
我们点开“创建知识库”。进入文件上传页面
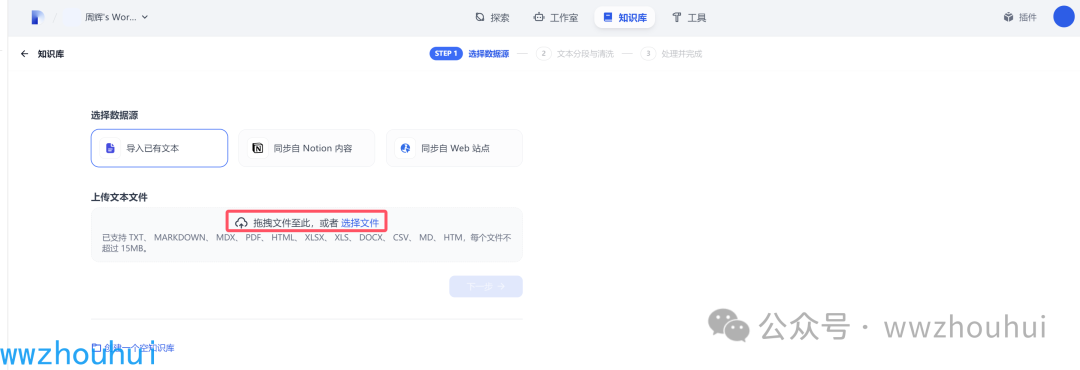
我们需要上传一个创建表的SQL 语句,文件类型是txt

上面txt文本内容如下:
-- 创建学生成绩表
CREATE TABLE `student_scores` (
`id` bigintNOT NULL AUTO_INCREMENT COMMENT '主键ID',
`student_id` varchar(20) NOT NULL COMMENT '学号',
`student_name` varchar(50) NOT NULL COMMENT '学生姓名',
`class_name` varchar(50) NOT NULL COMMENT '班级名称',
`subject` varchar(50) NOT NULL COMMENT '科目名称',
`score` decimal(5,2) NOT NULL COMMENT '分数',
`exam_date` dateNOT NULL COMMENT '考试日期',
`semester` varchar(20) NOT NULL COMMENT '学期',
`grade` varchar(20) NOT NULL COMMENT '年级',
`created_at` datetime NOT NULLDEFAULTCURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` datetime NOT NULLDEFAULTCURRENT_TIMESTAMPONUPDATECURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_student_id` (`student_id`),
KEY `idx_exam_date` (`exam_date`),
KEY `idx_subject` (`subject`),
KEY `idx_class` (`class_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='学生成绩信息表';
我们需要把他上传。
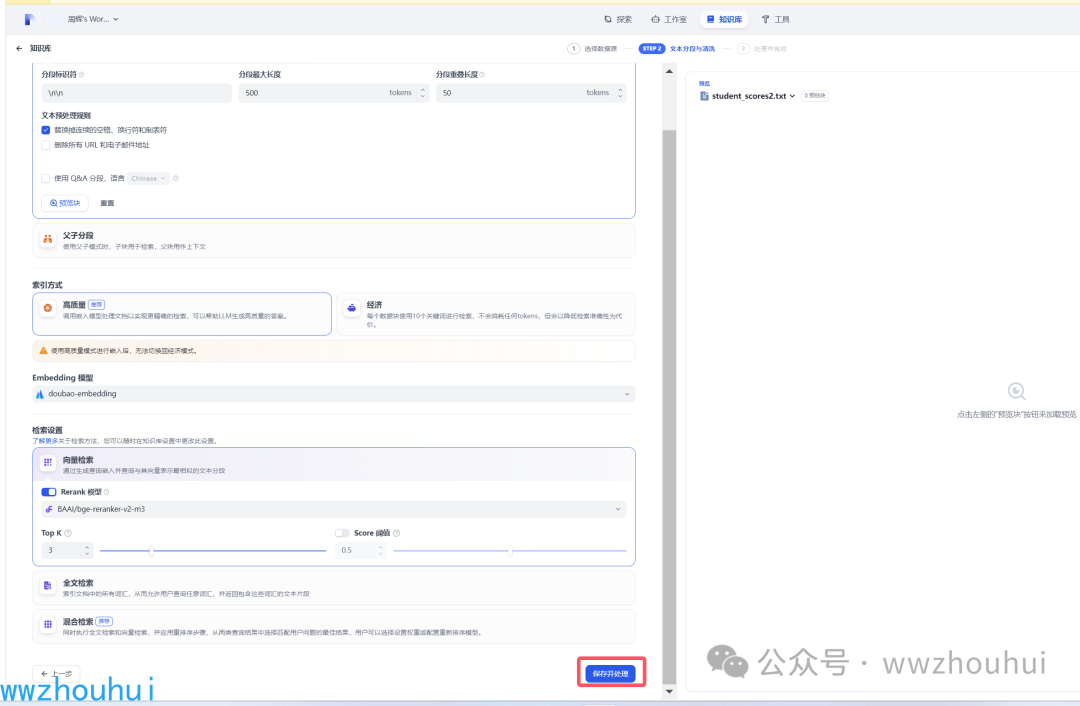
因为这个比较简单我们就用高质量的索引方式创建文本向量,创建完成后,我们完成创建表的SQL 语句知识库创建。
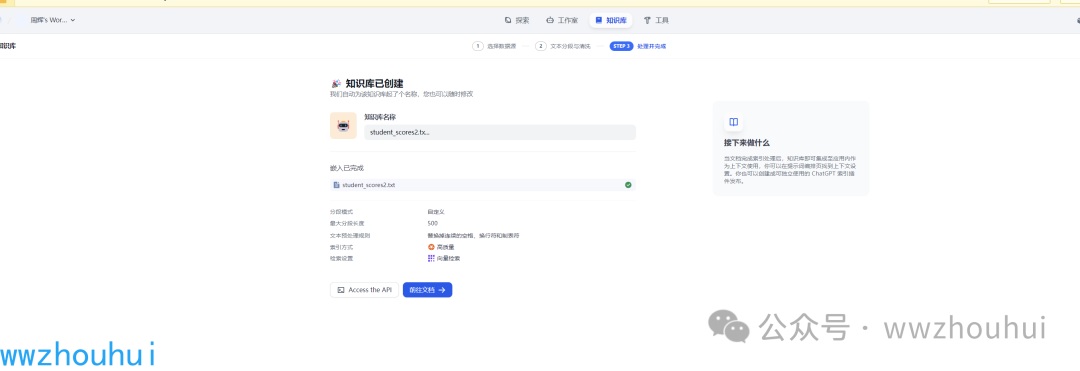
工作流制作
我们回到dify 工作台 创建一个 chatflow工作流,前面文章都有提到如何创建chatflow,这里就不做详细展开。
开始
这个开始节点我们这里不需要用户输入提示词,所以这个节点什么都不需要设置。
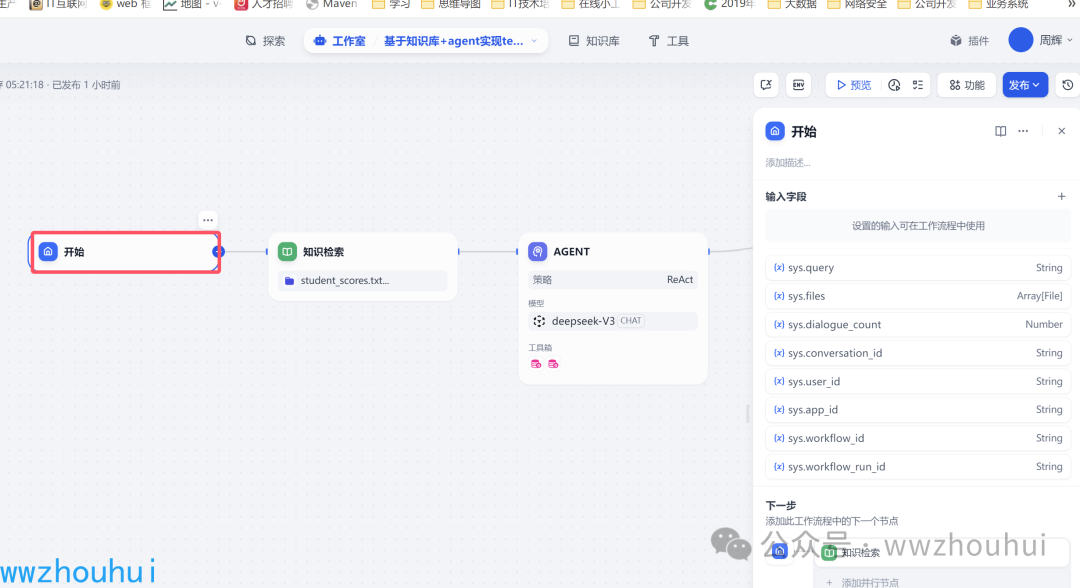
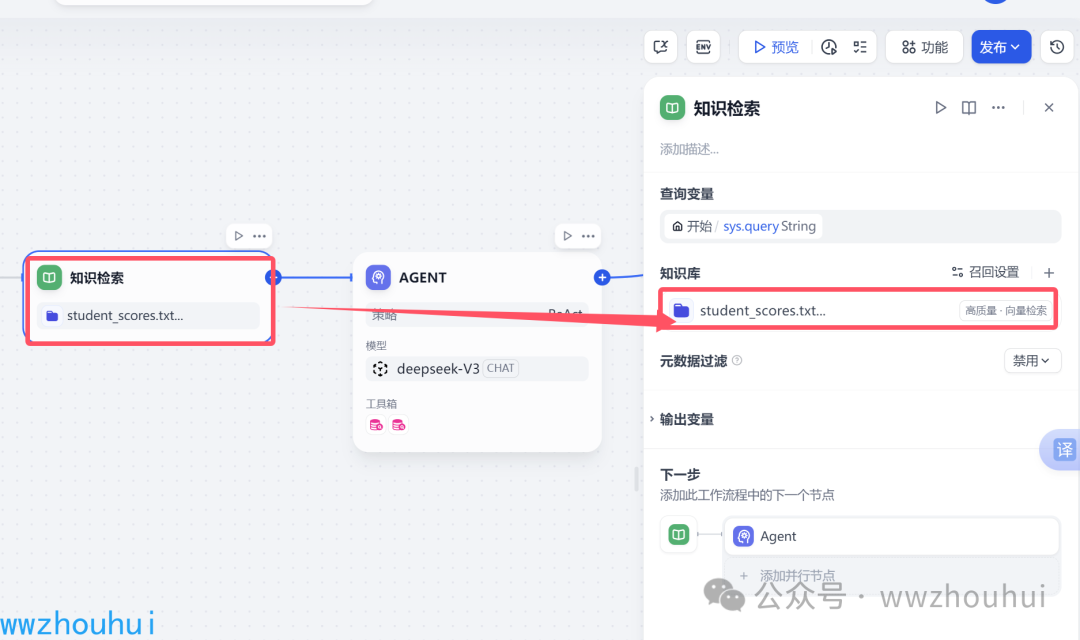
知识检索
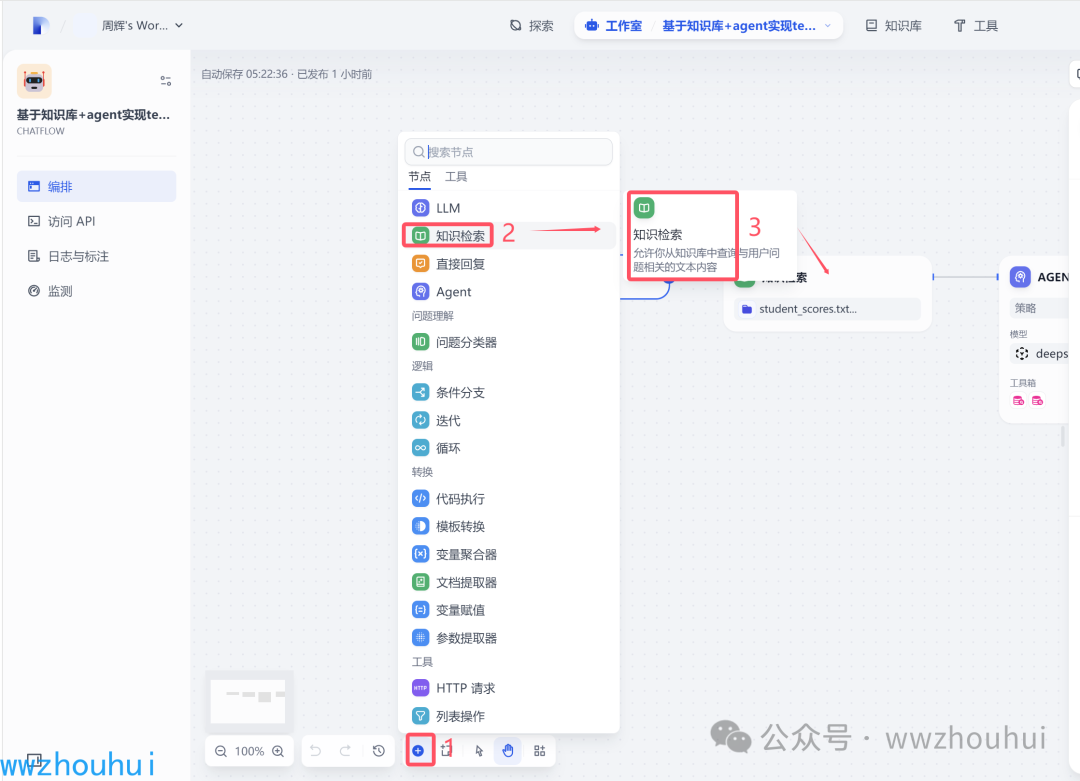
我们按照上面的步骤完成知识检索节点创建。
查询变量 输入sys.querystring
知识库这里我们点击添加上面配置好的知识库。
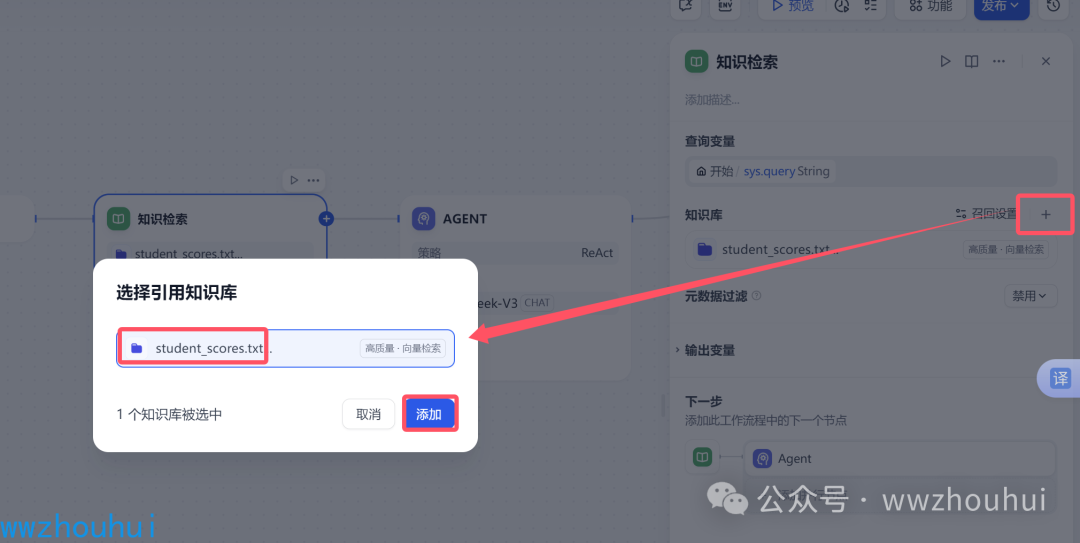
添加完成后,我们就设置好知识库检索这个节点。
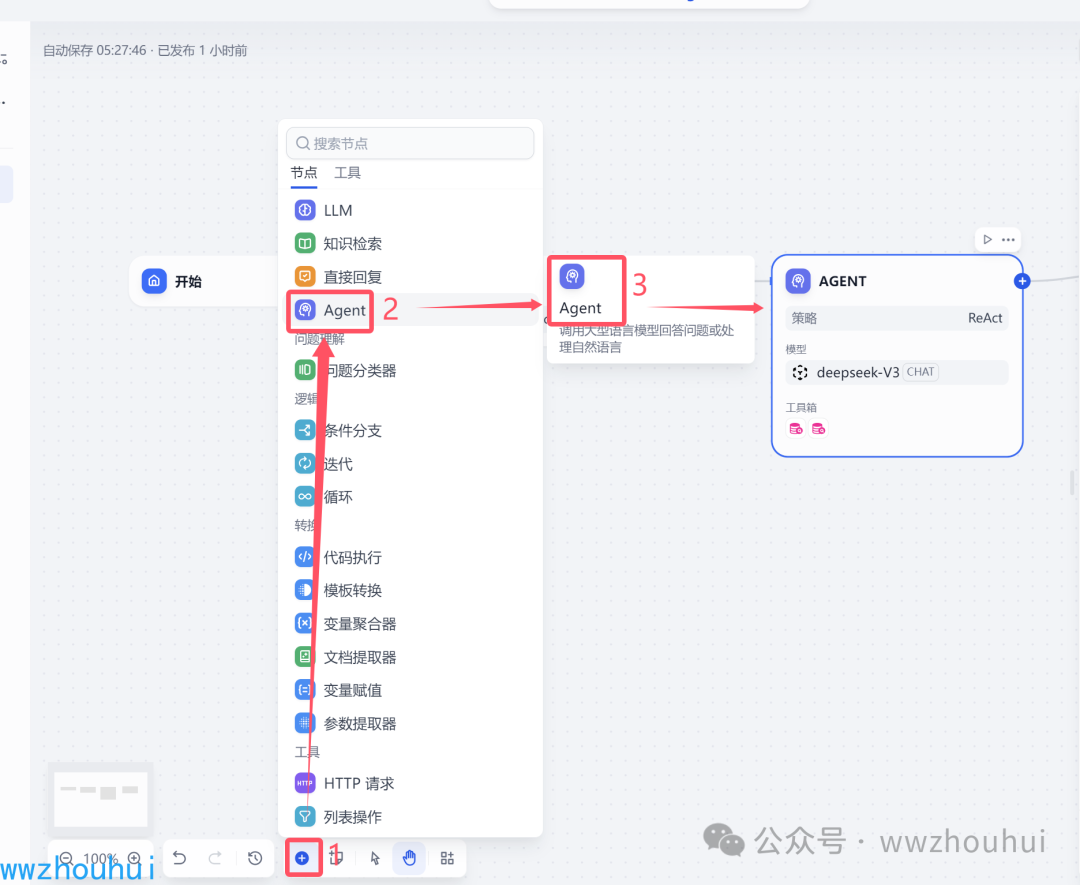
Agent
接下来我们在工作流中添加一个叫做“Agent”工作流节点. (这个Agent是dify 1.0.0之后版本中出现的,之前0.XX系列版本是没有的)
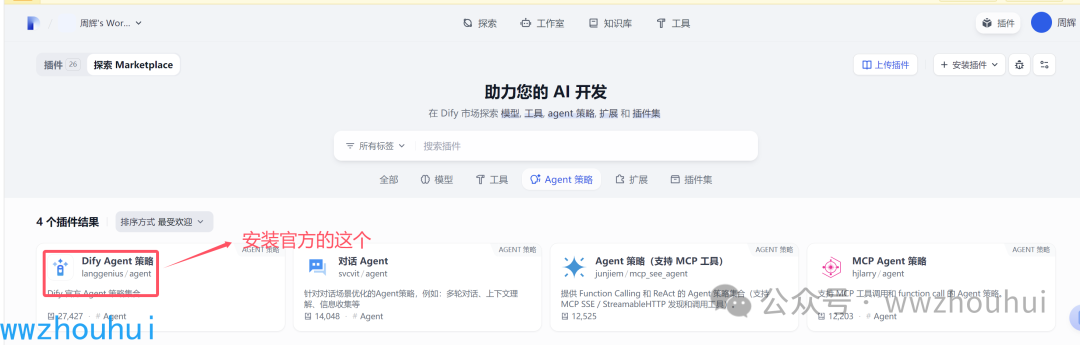
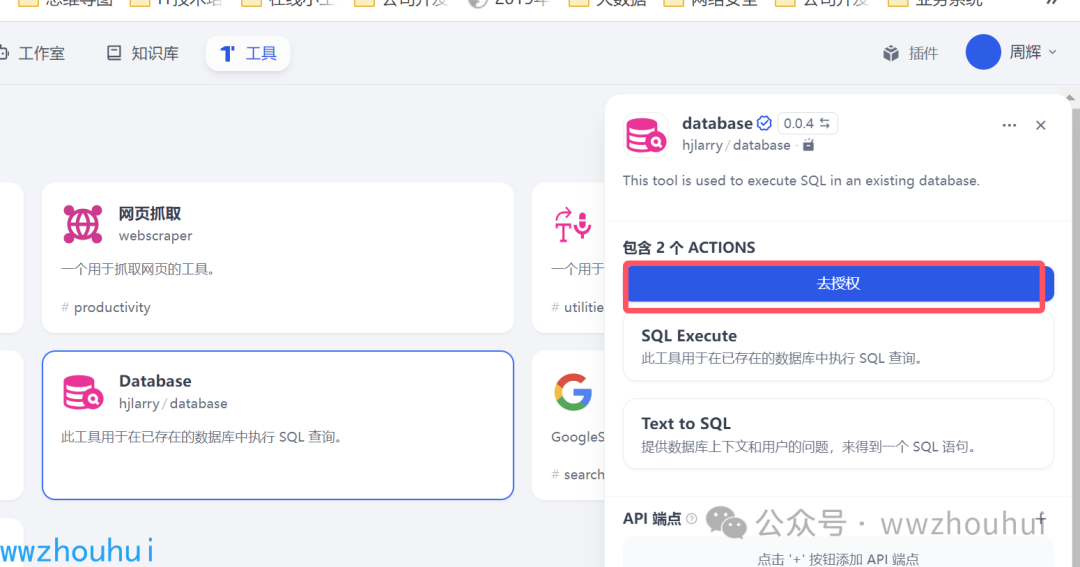
这里我们需要2个工具1个是 agent策略工具 1个是 database 插件。 这2个都是可以在插件市场找到
agent策略工具
database 插件
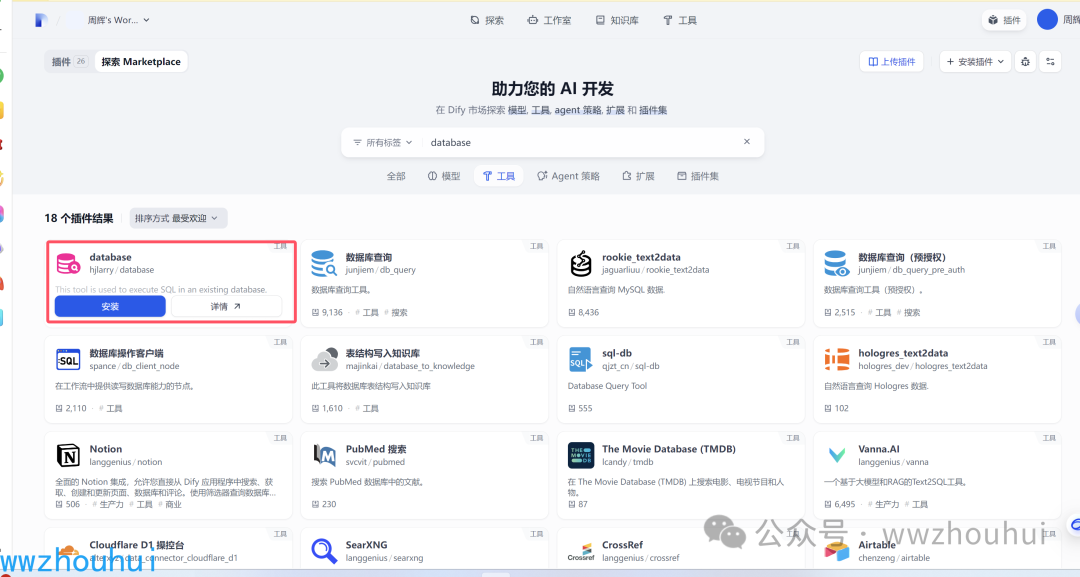
关于database 插件 可以看我之前的文章dify案例分享-基于database插件实现Text2sql的数据库查询图表工作流
我们可以在https://marketplace.dify.ai/plugins/hjlarry/database?language=zh-Hans 市场上找到这个项目
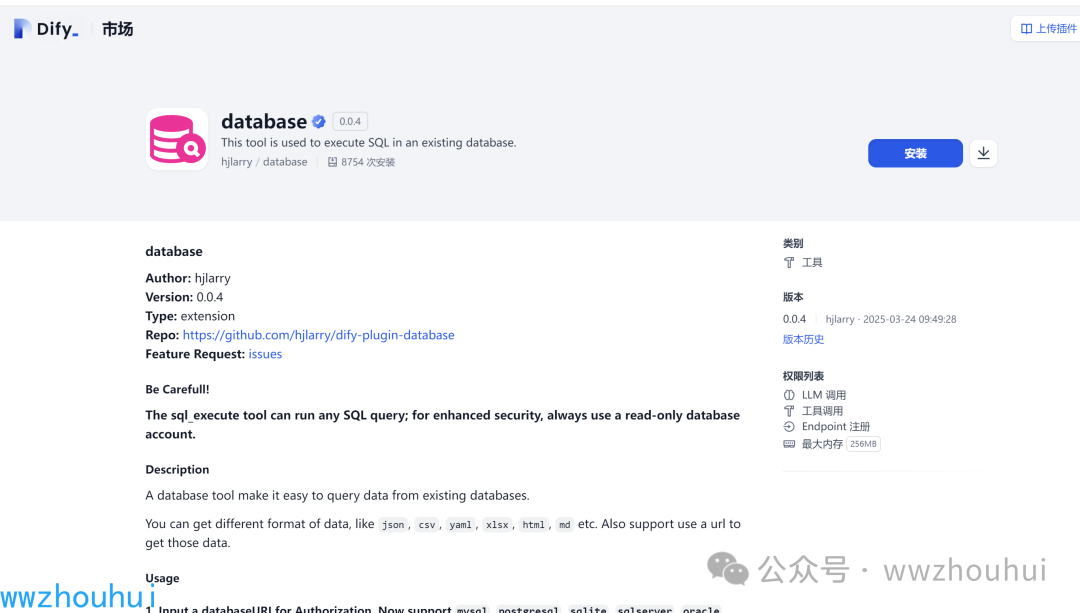
目前这个项目支持的数据库有mysql, postgresql, sqlite, sqlserver, oracle
mysql+pymysql://root:123456@localhost:3306/test
postgresql+psycopg2://postgres:123456@localhost:5432/test
sqlite:///test.db
mssql+pymssql://<username>:<password>@<freetds_name>/?charset=utf8
oracle+oracledb://user:pass@hostname:port[/dbname][?service_name=<service>[&key=value&key=value...]]我们在插件市场把它安装好后,就需要对它配置。
我们用的是mysql参考上述链接字符串
mysql+pymysql://root:123456@localhost:3306/test这里还有一个小技巧,就是如果数据库密码是带有@符号的,我们需要转义一下。否则会出现错误。
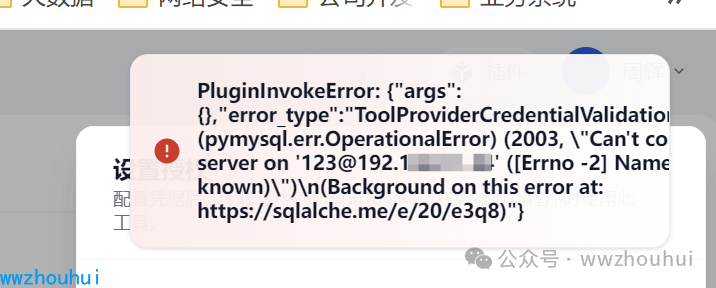
上述因为密码也带有特殊符号“@” 和后面的数据链接符号@产生了歧义 这样程序连接就会报错
如何解决
若要借助转义的方式来处理包含特殊字符 @ 的连接字符串,在标准的数据库连接字符串里,一般没有通用转义符号能直接用在字符串里。不过可以对特殊字符 @ 进行 URL 编码,@ 对应的 URL 编码是 %40。
最后的变成
mysql+pymysql://root:zzz%40123@192.168.11.84:19030/test_db这样修改后再连接就OK 了
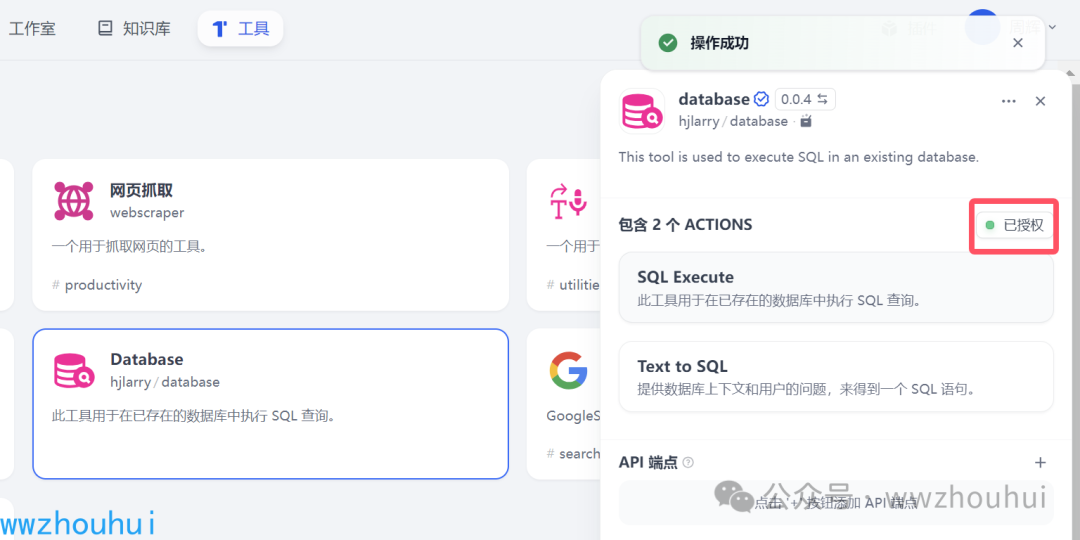
看到已授权完成配置。
上面2个工具安装和配置完成后,我们进入Agent策略工具的配置操作。
我们从下拉选项中选中我们前面装的Agent,如果只装了一个这里只有一个下拉选项。Agent 策略中有两个,一个是function calling ,另外一个是ReAct 我们选择第二个“ReAct”
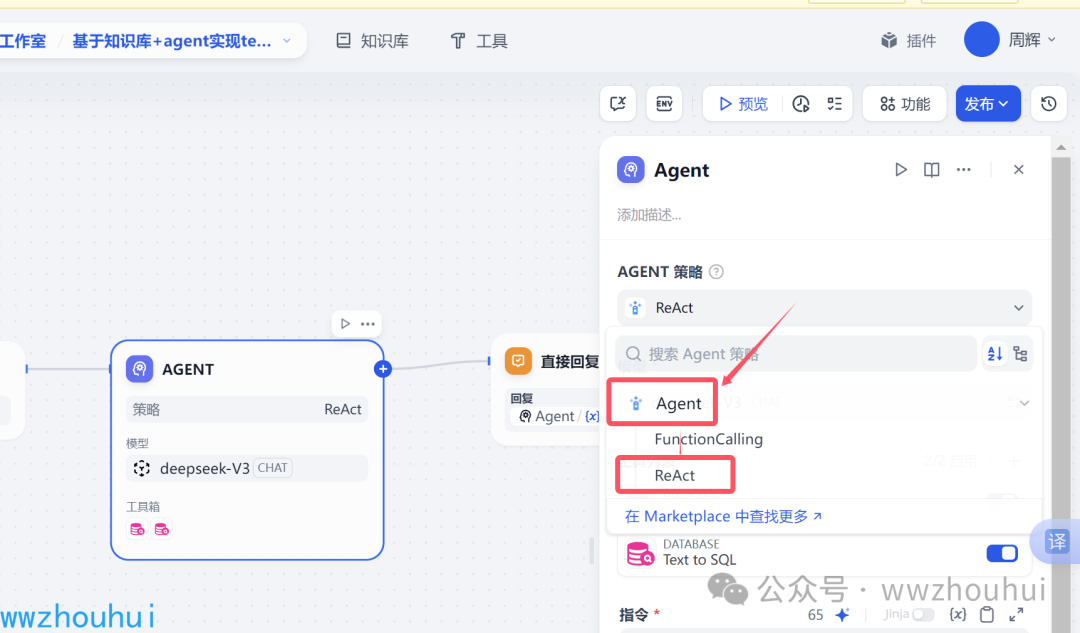
下面的模型选择就非常重要的了。建议你选择火山引擎的deepseek v3 模型,其他模型我测试效率效果不太好。AI agent对模型要求比较高。有的模型达不到效果,后面测试的时候这块很容易翻车。切记用我推荐的模型,其他模型跑不出来就别说没看我文章了。
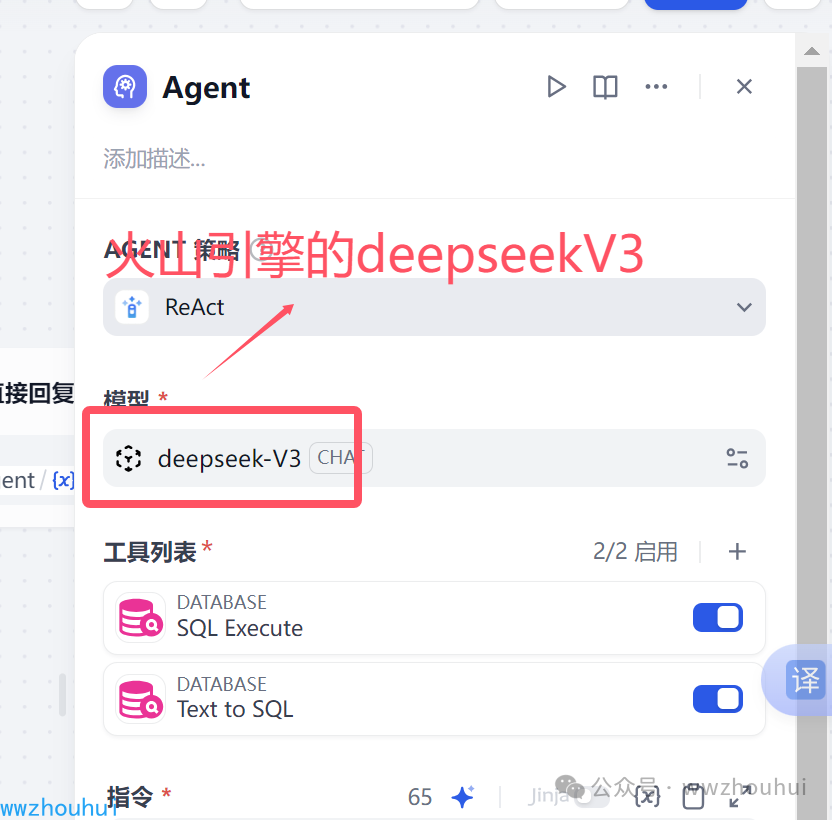
工具列表中,我们选择databse, 里面有个函数我们都选中它。
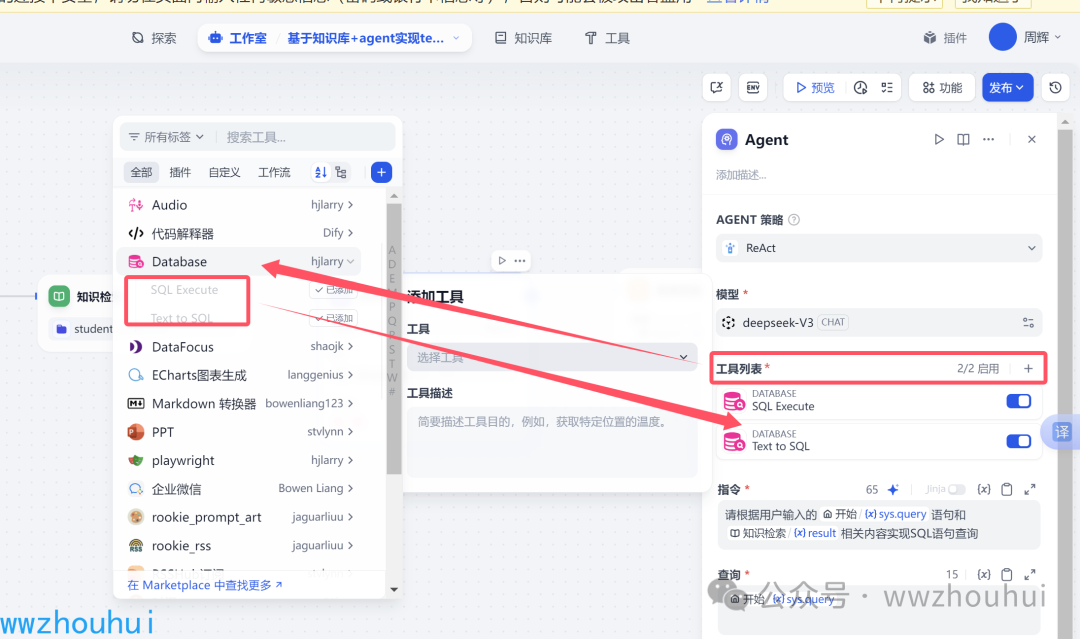
这里我们还需要有个设置,在text to SQL 点击设置,弹出对话框中 设置一下数据库模型。
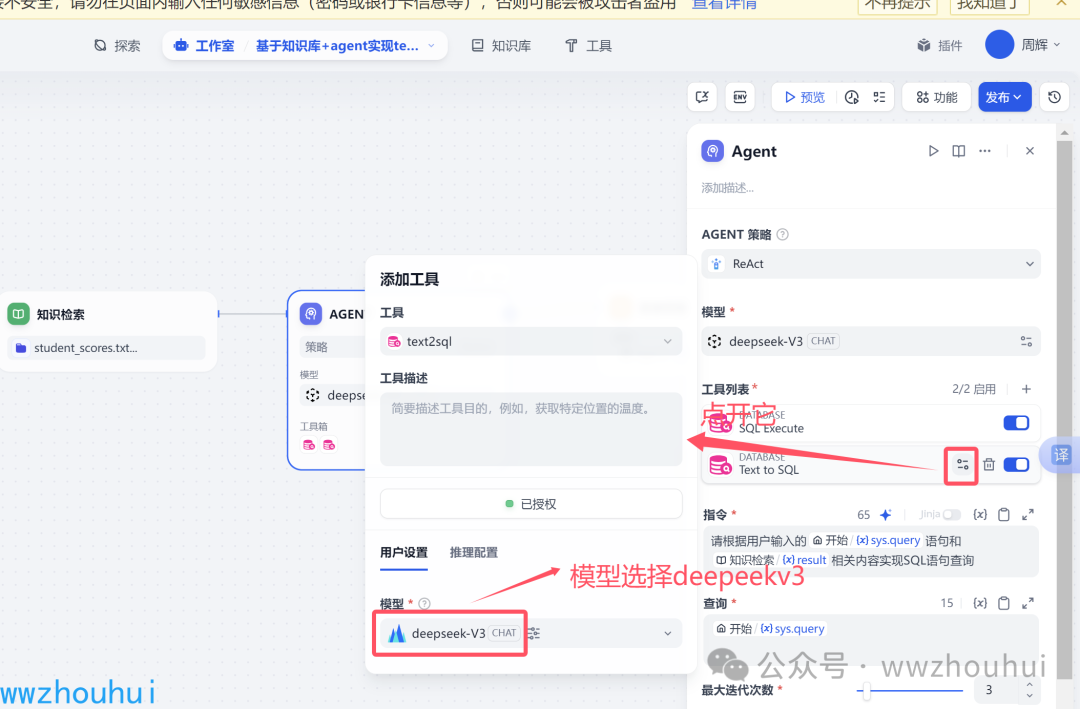
这个地方的模型我们也使用火山引擎的deepseek v3 模型,这2块的操作是本工作流的重点,细节比较多,如果不按照我文档的里面步骤 也很容易翻车。如果你翻车了建议你把这块文章在好好看一下,注意哪地方没设置好。
指令这块填写如下内容:
请根据用户输入的{{#sys.query#}}语句和{{#1745388821686.result#}}相关内容实现SQL语句查询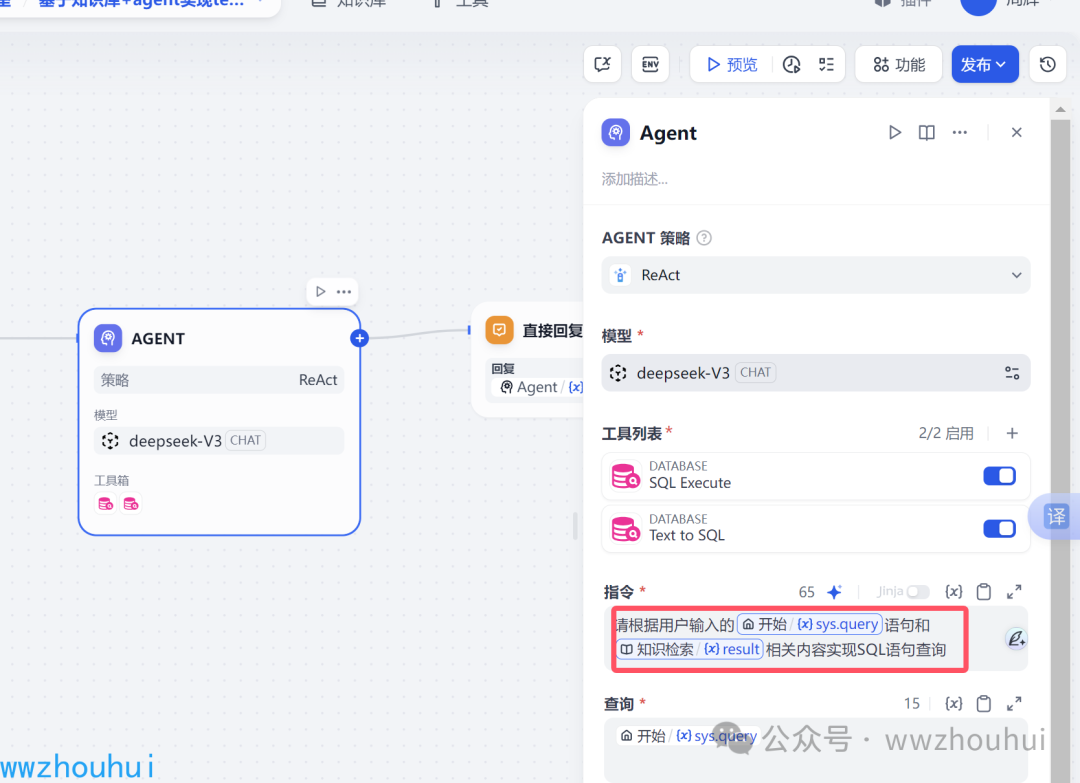
查询这块我们填入 sys.query
迭代次数默认3次,如果模型能力弱可以把这值在该大一点。
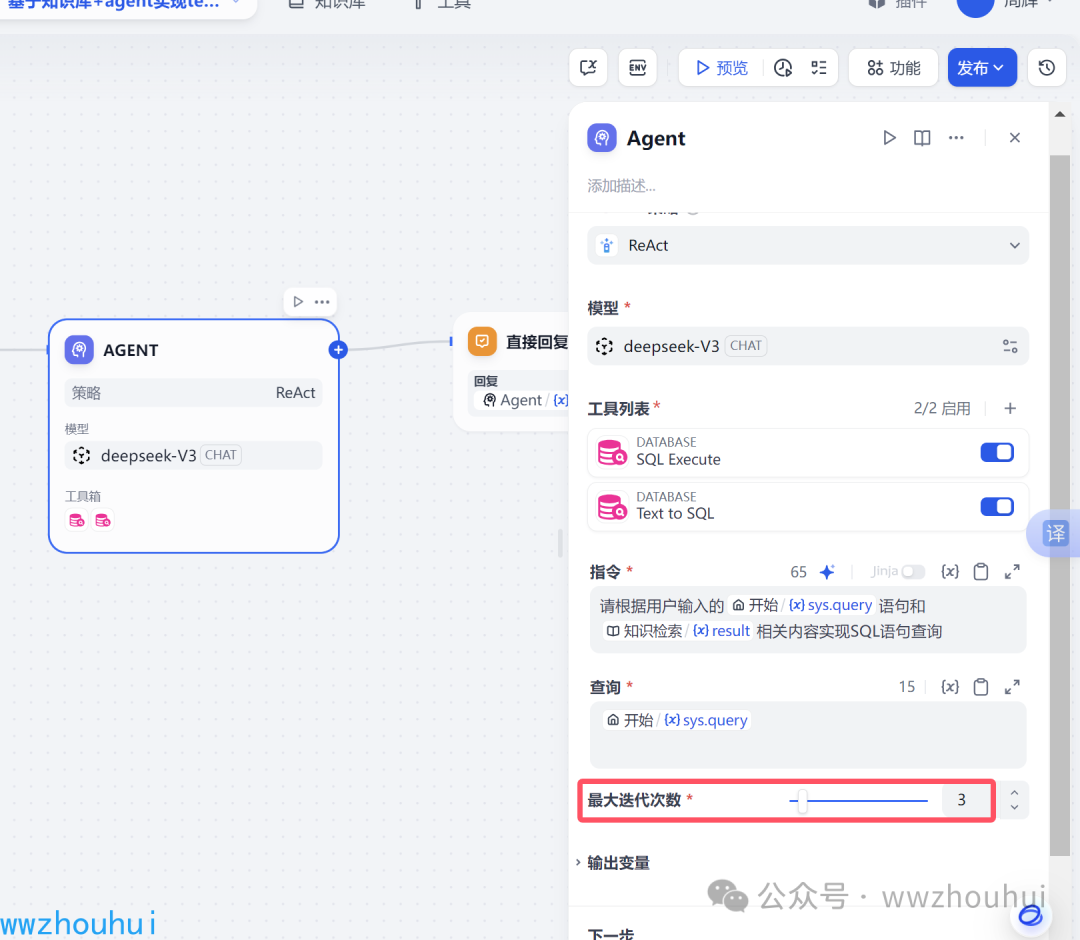
以上我们就完成了Agent 节点的配置。
直接回复
下面的直接回复就很简单了,直接把上面Agent输出返回即可。
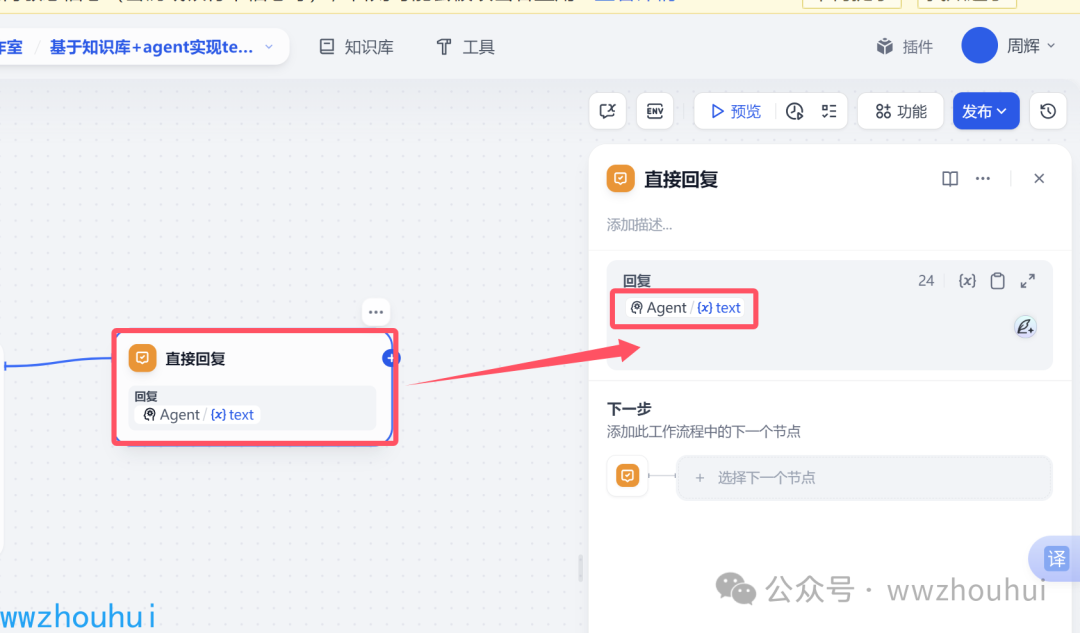
以上我们就完成了工作流流AI Agent 的搭建了。
3 .AI Agent制作
我们回到工作流 创建一个 AI agent
进入AI agent界面,这个地方配置就比较简单了。
系统提示词 我们这里输入 上面的SQL 语句脚本
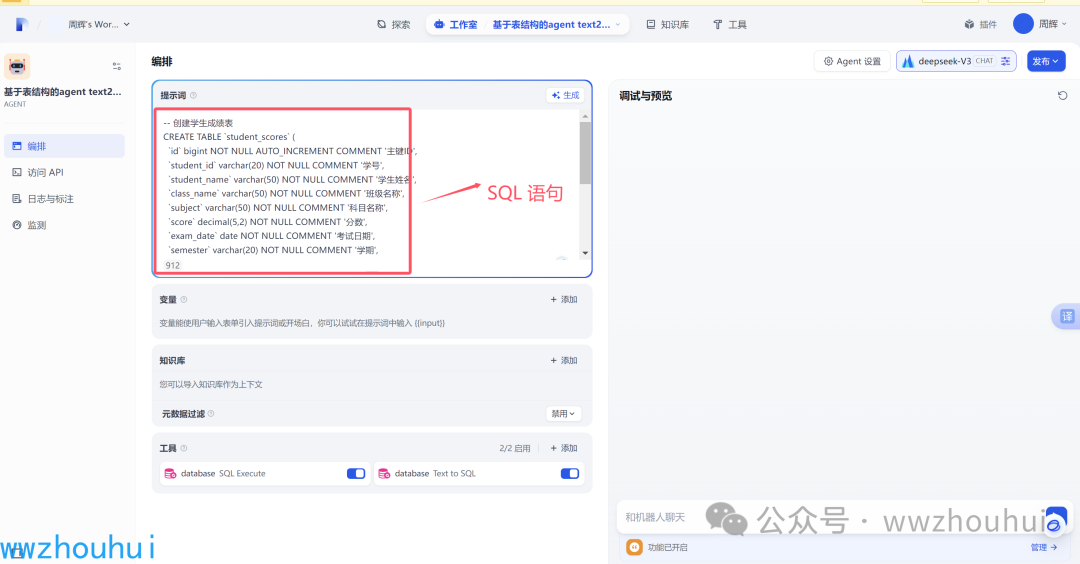
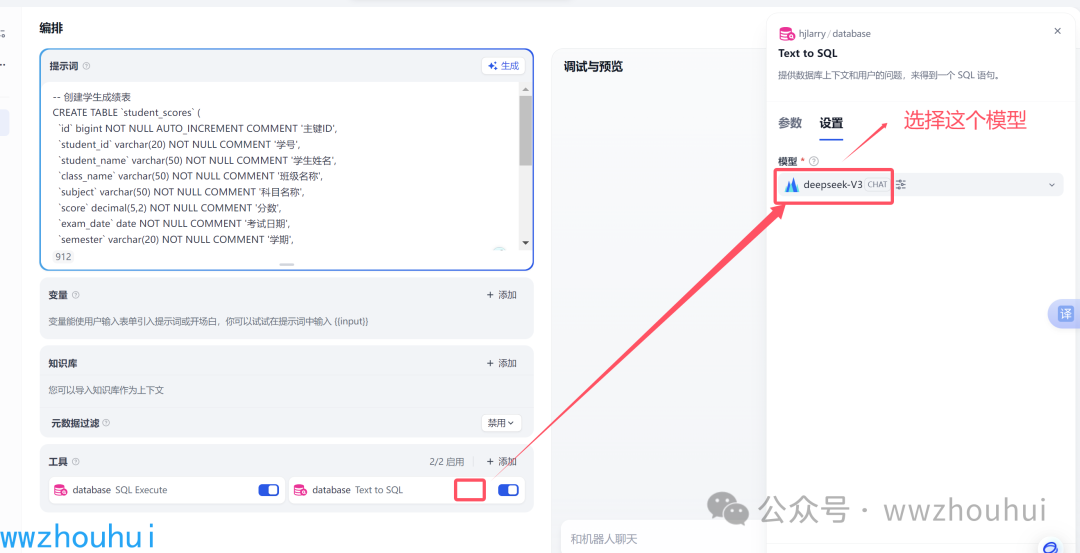
接下来 在工具里面配置一下database工具。这个配置比较简单,注意就是模型这个地方
右上角 Agent Mode 我们就选择默认的 ReAct
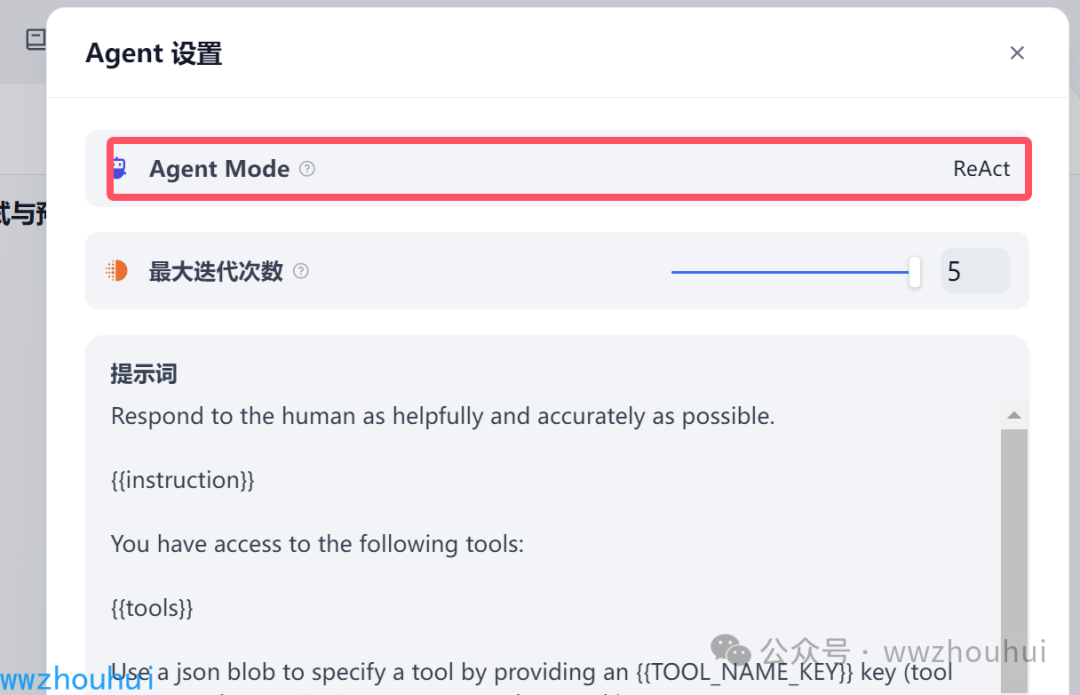
模型这里我们还是选择火山引擎的deepseek v3 模型
以上我们就完成了AI agent 制作。
4.验证及测试
工作流AI Agent测试
我们在工作流AI Agent工作流,点击“预览按钮” 输入我们的问题
请帮我查询一下student_scores有多少条记录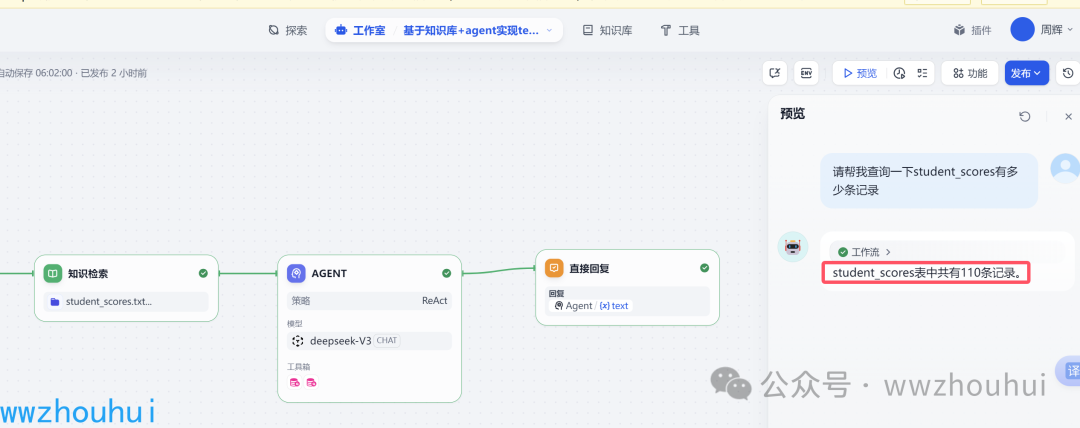
我们查询一下数据库有多少条记录
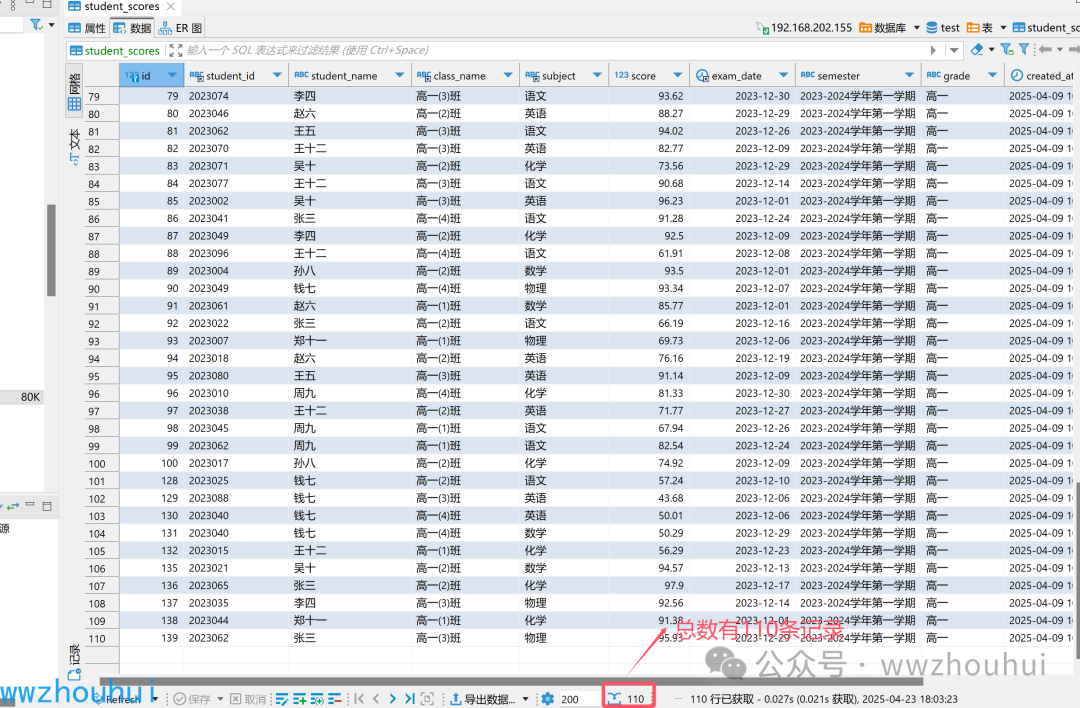
OK 数据量对的。
AI Agent测试
接下来我们回到AI Agent 对话窗口中,输入下面的问题
请帮我查询一下student_scores有多少条记录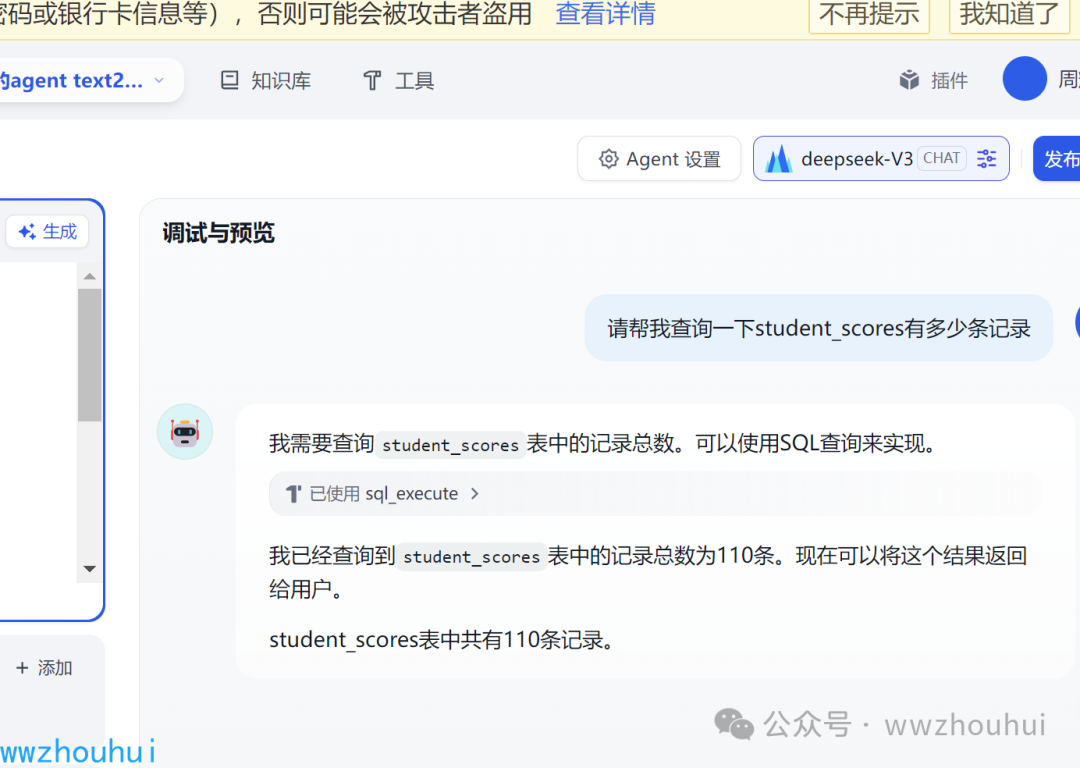
上面我们通过简单的自然语言实现了一个text2sql,这工作流也可以分享给其他人使用。
5.总结
今天主要带大家了解并实现了基于 Dify 知识库与 AI Agent 的 Text2SQL 工作流方案。借助 Dify 提供的功能,我们首先创建了知识库,上传创建表的 SQL 语句文本,完成文本向量的创建。接着制作工作流,添加开始、知识检索、Agent 和直接回复等节点,对每个节点进行细致配置,尤其在 Agent 节点配置中选择合适的工具、模型和策略,完成工作流 AI Agent 的搭建。之后,我们又创建了 AI Agent,配置系统提示词、工具及模型等。总体来说,这个方案属于比较简单的方案,感兴趣的小伙伴可以按照本文步骤去尝试。今天的分享就到这里结束了,我们下一篇文章见。


















 9374
9374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











