







比赛介绍
在百度智慧交通赛项中,百度飞桨场景化地设计了基于深度学习的智能车趣味赛题,要求同学们在一套故事线中,使用飞桨完成特定场景的自动驾驶任务及系列自动化操作,赛题旨在在为创新人才的培养提供综合演练平台,拓宽高校人工智能相关专业的教学内容,提升高校科技创新能力。
OCR任务说明
这一次的智慧交通组的任务由以往的检测分割换成了OCR任务。OCR任务分为两种文字检测和文字识别,检测需要定位文本位置(类似目标检测),而识别就是识别出图像中的文字,我们这次的比赛任务就是文字识别。

基线选择
本项目仅仅为大家展示这次线上赛的基本流程,更多的是需要大家探索模型涨点的技巧。对于OCR任务,我们首推PaddleOCR工具包,PaddleOCR中集成了非常多的OCR算法可供大家选择!如果你想更加深入地了解PaddleOCR,可以去github上查看,链接在这:PaddleOCR。
项目流程
那咱们话不多说直接开始吧!
1、数据集准备
我们首先需要解压数据,这里需要注意地是aistudio中数据最好放在data目录下,因为data目录下空间很大,放在其他地方会导致项目加载变慢。
#解压数据集
!unzip -d data/ data/data258841/DataForCompetitor.zip我们先对数据集的基本情况看一下,先来看看图片
![]()
![]()
![]()
下面是标签
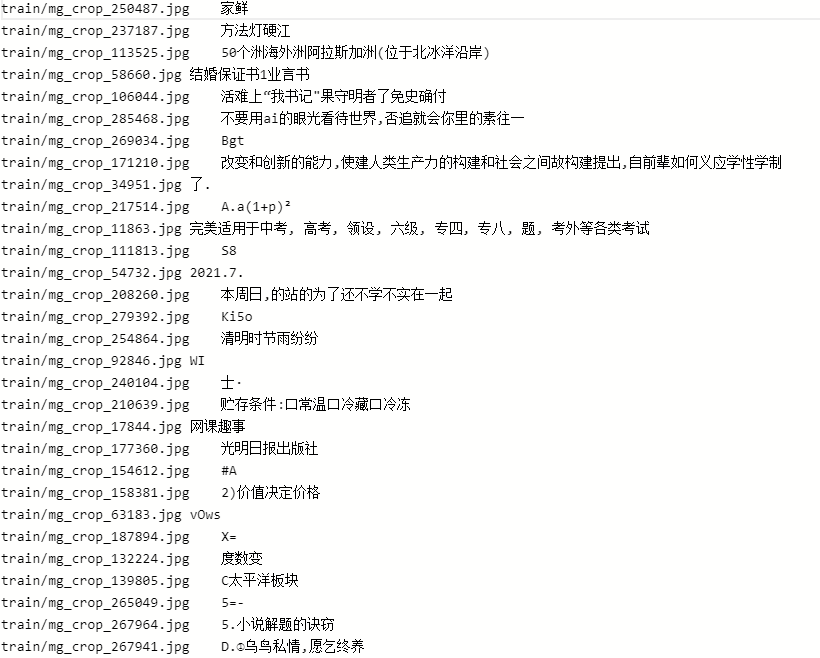
从标签的情况来看,数据集包含了英文、中文、字符等,本项目中我们使用了PaddleOCR自带的字典进行训练,当然大家可以根据数据集情况来定制化字典。 并且,数据集质量不是很高,图片分辨率很低很低,这就是一个需要解决的问题,大家可以开动脑筋。
数据集的一些Tips: (1) 大家要清楚地了解数据集的基本情况,包括图片质量,数据的分布。历年来看,最后高分选手都是对数据集进行了仔细地清洗。(2) 合成数据尽量少用,因为这个会导致结果无法重现。
2、克隆项目仓库
接下来我们克隆对应的项目仓库,注意,本项目一定要用PaddleOCR2.7才可以完成。另外,很多同学最后肯定会遇到文件过大问题,本项目对PaddleOCR进行了清洗删除了不必要部分,大家可以直接使用!
#PPOCRv4目前只在github上面,注意不要clone错了
#目前项目里面已经上传最新的PaddleOCR
# !git clone https://github.com/PaddlePaddle/PaddleOCR<span style="color:rgba(0, 0, 0, 0.85)"><span style="background-color:#ffffff">Cloning into 'PaddleOCR'...
^C
</span></span>2、开始炼丹
准备好代码仓库和数据,那么下面就是快乐炼丹了。
# 解压一下预训练权重
!tar -xvf ch_PP-OCRv4_rec_train.tar<span style="color:rgba(0, 0, 0, 0.85)"><span style="background-color:#ffffff">ch_PP-OCRv4_rec_train/
ch_PP-OCRv4_rec_train/._student.pdparams
ch_PP-OCRv4_rec_train/student.pdparams
</span></span>#进入PaddleOCR目录
%cd /home/aistudio/PaddleOCR<span style="color:rgba(0, 0, 0, 0.85)"><span style="background-color:#ffffff">/home/aistudio/PaddleOCR
</span></span>#安装必要的依赖库
!pip install -r requirements.txt#开始执行训练
!python tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model=/home/aistudio/ch_PP-OCRv4_rec_train/student.pdparams这里我们选择的是最新的PPOCRv4,这里向大家介绍一下配置文件内容。
Global:
debug: false
use_gpu: true #是否使用GPU训练
epoch_num: 50 #训练轮数
log_smooth_window: 20 #常规log设置
print_batch_step: 10 #打印训练日志的迭代次数
save_model_dir: ./output/rec_ppocr_v4 #模型保存路径
save_epoch_step: 10 #保存模型的轮数
eval_batch_step: [0, 2000] #进行evaluation的迭代次数
cal_metric_during_train: true #训练过程中是否计算指标
pretrained_model: #预训练模型权重
checkpoints: #恢复训练的权重
save_inference_dir: #保存推理结果的路径
use_visualdl: false #是否可视化训练过程
infer_img: doc/imgs_words/ch/word_1.jpg #推理时候的图片
character_dict_path: ppocr/utils/ppocr_keys_v1.txt
max_text_length: &max_text_length 25
infer_mode: false
use_space_char: true
distributed: true #是否分布式训练
save_res_path: ./output/rec/predicts_ppocrv3.txt #保存预测结果的txt路径
Optimizer: #优化器参数
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.0001
warmup_epoch: 5
regularizer:
name: L2
factor: 3.0e-05
Architecture: #模型结构
model_type: rec #文本识别
algorithm: SVTR_LCNet #算法名称
Transform:
Backbone: #骨干网络
name: PPLCNetV3
scale: 0.95
Head: #预测头
name: MultiHead
head_list:
- CTCHead:
Neck:
name: svtr
dims: 120
depth: 2
hidden_dims: 120
kernel_size: [1, 3]
use_guide: True
Head:
fc_decay: 0.00001
- NRTRHead:
nrtr_dim: 384
max_text_length: *max_text_length
Loss: #损失函数
name: MultiLoss
loss_config_list:
- CTCLoss:
- NRTRLoss:
PostProcess: #后处理
name: CTCLabelDecode
Metric: #验证时候的指标
name: RecMetric
main_indicator: acc
Train: #训练过程配置
dataset: #数据集信息
name: MultiScaleDataSet
ds_width: false
data_dir: /home/aistudio/data/DataForCompetitor/ #数据集根路径
ext_op_transform_idx: 1
label_file_list: #标签路径
- /home/aistudio/data/DataForCompetitor/train_label.txt
transforms: #数据增强
- DecodeImage:
img_mode: BGR
channel_first: false
- RecConAug:
prob: 0.5
ext_data_num: 2
image_shape: [48, 320, 3]
max_text_length: *max_text_length
- RecAug:
- MultiLabelEncode:
gtc_encode: NRTRLabelEncode
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_gtc
- length
- valid_ratio
sampler:
name: MultiScaleSampler
scales: [[320, 32], [320, 48], [320, 64]]
first_bs: &bs 192
fix_bs: false
divided_factor: [8, 16] # w, h
is_training: True
loader:
shuffle: true
batch_size_per_card: *bs
drop_last: true
num_workers: 8
Eval: #验证信息
dataset:
name: SimpleDataSet
data_dir: /home/aistudio/data/DataForCompetitor/
label_file_list:
- /home/aistudio/data/DataForCompetitor/train_label.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- MultiLabelEncode:
gtc_encode: NRTRLabelEncode
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_gtc
- length
- valid_ratio
loader:
shuffle: false
drop_last: false
batch_size_per_card: 128
num_workers: 4
3、导出模型
我们需要将模型导出,以去除掉不必要的参数。
#注意修改下面的路径
# -c 后面设置训练算法的yml配置文件
# -o 配置可选参数
# Global.pretrained_model 参数设置待转换的训练模型地址,不用添加文件后缀 .pdmodel,.pdopt或.pdparams。
# Global.save_inference_dir参数设置转换的模型将保存的地址
!python tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model=/home/aistudio/output/rec_ppocr_v4/best_model/model Global.save_inference_dir=/home/aistudio/infer/<span style="color:rgba(0, 0, 0, 0.85)"><span style="background-color:#ffffff">W0221 15:17:53.666481 6723 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 12.0, Runtime API Version: 11.8
W0221 15:17:53.667668 6723 gpu_resources.cc:164] device: 0, cuDNN Version: 8.9.
[2024/02/21 15:17:56] ppocr INFO: load pretrain successful from /home/aistudio/output/rec_ppocr_v4/best_model/model
I0221 15:18:02.096050 6723 program_interpreter.cc:212] New Executor is Running.
[2024/02/21 15:18:02] ppocr INFO: inference model is saved to /home/aistudio/infer/inference
</span></span>4、准备提交结果
最后一步就是准备预测结果就行啦
%cd /home/aistudio/<span style="color:rgba(0, 0, 0, 0.85)"><span style="background-color:#ffffff">/home/aistudio
</span></span># 调试一下predict.py是否正确
!python predict.py<span style="color:rgba(0, 0, 0, 0.85)"><span style="background-color:#ffffff">[2024/02/21 14:46:56] ppocr INFO: In PP-OCRv3, rec_image_shape parameter defaults to '3, 48, 320', if you are using recognition model with PP-OCRv2 or an older version, please set --rec_image_shape='3,32,320
</span></span>#打包, 下载, 提交
!zip -q -r -o submission.zip model/ PaddleOCR/ predict.py压缩包的结构如下,提交结果一定要将PaddleOCR目录下训练好的权重目录删除,这些会导致目录超100M。这些模型都用不到,我们用导出模型预测。
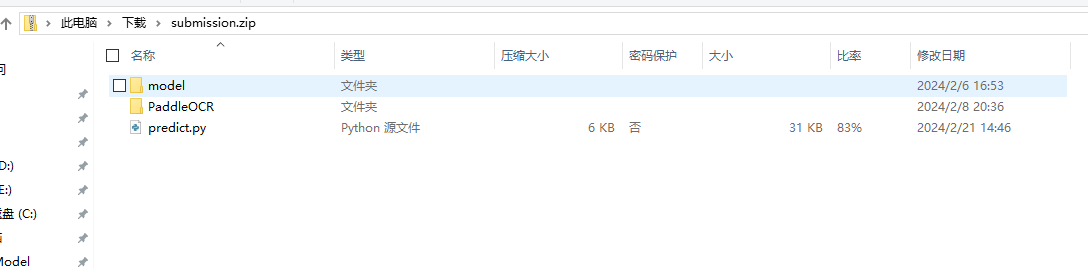
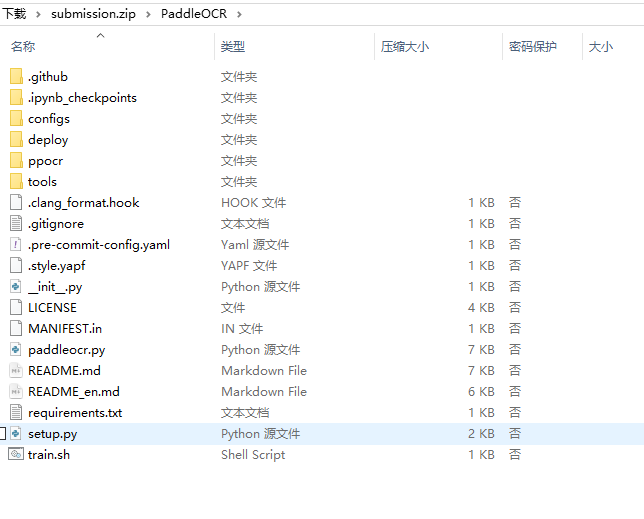
提交的PaddleOCR的目录如下
5、评价指标
Accuracy : 模型对每张图片里文字内容的识别准确率,错一个字即为错,按照准确率高低进行排名。
















 4433
4433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











